0.PTA得分截图
![]()
1.本周学习总结(0-4分)
1.1 总结线性表内容
顺序表结构体定义、顺序表插入、删除的代码操作等
顺序表结构体定义:
typedef int ElemType;
typedef struct
{
ElemType data[MaxSize]; //存放顺序表元素
int length ; //存放顺序表的长度
} List;
顺序表插入
bool ListInsert(List &L,int i,ElemType e)
{ int j;
if (i<1 || i>L->length+1)
return false; //参数错误时返回false
i--; //将顺序表逻辑序号转化为物理序号
for (j=L->length;j>i;j--) //将data[i..n]元素后移一个位置
L->data[j]=L->data[j-1];
L->data[i]=e; //插入元素e
L->length++; //顺序表长度增1
return true; //成功插入返回true
}
顺序表删除
bool ListDelete(List &L,int i,ElemType &e)
{
if (i<1 || i>L->length) //删除位置不合法
return false;
i--; //将顺序表逻辑序号转化为物理序号
e=L->data[i];
for (int j=i;jlength-1;j++)
L->data[j]=L->data[j+1];
L->length--; //顺序表长度减1
return true;
}
链表结构体定义
typedef struct LNode {
ElemType data; // 数据域
struct Lnode *next; // 指针域
} LinkList;
LinkList *L; // L 为单链表的头指针
头插法
void CreateListF(LinkList& L, int n)//头插法建链表,L表示带头结点链表,n表示数据元素个数
{
int i;
LinkList node;
L = new LNode;
L->next = NULL;
for (i = 0; i < n; i++)
{
node = new LNode;
cin >> node->data;
node->next = L->next;
L->next = node;
}
}
尾插法
void CreateListR(LinkList& L, int n)//尾插法建带头结点链表,细节不表
{
int i;
LinkList node, tail;
L = new LNode;
L->next = NULL;
tail = L;
for (i = 0; i < n; i++)
{
node = new LNode;
cin >> node->data;
node->next=NULL;
tail->next = node;
tail = node;
}
}
链表插入
bool ListInsert(LinkList &L,int i,ElemType e){
int j=0;
LinkList p=L,s;
while(p&&jnext;
}
if(p==NULL) return false; //未找到第i-1个结点
s=new LNode;
s->data=e;
s->next=p->next; //插入p后面
p->next=s;
return true;
}
链表删除
bool ListDelete_L(LinkList &L,int i,ElemType &e)
{
int j=0;
LinkList p=L,s,q;
while(p&&jnext;j++;
}
if(p==NULL) return false;
q=p->next; //第i个位置
if(q==NULL) return false;
e=q->data;
p->next=q->next;//改变指针关系,删除
delete q;
return true;
}
有序表的合并
void MergeList(LinkList& L1, LinkList L2)
{
LNode *pa,* pb;
pa = L1->next;
pb = L2->next;
LNode *r, *s;
r = L1;//r为L1头结点
while (pa != NULL && pb != NULL)
{
if (pa->data < pb->data)
{
s = new LNode;
s->data = pa->data;
r->next = s;
r = s;
pa = pa->next;
}
else if (pa->data > pb->data)
{
s = new LNode;
s->data = pb->data;
r->next = s;
r = s;
pb = pb->next;
}
else
{
if (pa->next != NULL)
pa = pa->next;
else
pb = pb->next;
}
}
while (pa)
{
s = new LNode;
s->data = pa->data;
r->next = s;
r = s;
pa = pa->next;
}
while (pb)
{
s = new LNode;
s->data = pb->data;
r->next = s;
r = s;
pb = pb->next;
}
}
循环链表
特点:循环单链表:将表中尾结点的指针域改为指向表头结点,整个链表形成一个环。由此从表中任一结点出发均可找到链表中其他结点,而单链表做不到。循环链表中没有明显的尾端。循环双链表与非循环双链表相比,①链表中没有空指针域;②p所指结点为尾结点的条件:p->next==L;③一步操作即L->prior可以找到尾结点。
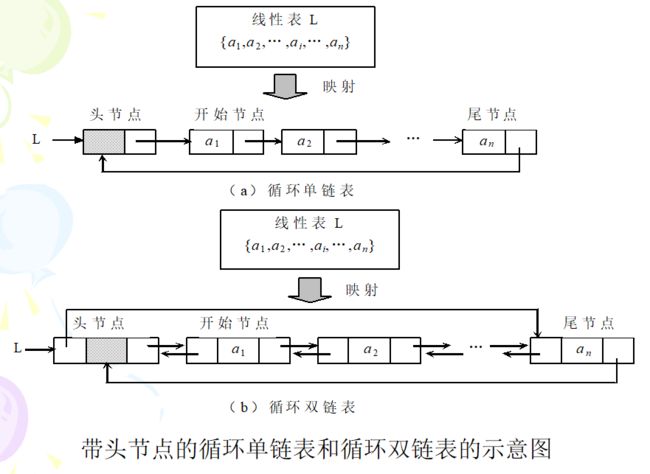
双链表结构特点
双链表每个节点有2个指针域,一个指向后继节点,一个指向前驱节点。优点是:从任一结点出发可以快速找到其前驱结点和后继结点;从任一结点出发可以访问其他结点。
类型定义:
typedef struct DNode //声明双链表节点类型
{ ElemType data;
struct DNode *prior; //指向前驱节点
struct DNode *next; //指向后继节点
} DLinkList;
1.2.谈谈你对线性表的认识及学习体会。
本章学习的主要内容有:线性表的基本概念、顺序存储和链式存储、应用以及有序表,相对于上学期学习的内容相比更加注重实践。学习线性表的过程中,需要大量地使用到指针,所以对这一块内容的操作要比较熟悉,在写题目的时候也要注重代码的逻辑性。在学习过程中也接触到了像时间复杂度这种概念,知道了通过改良算法来节约时间的必要性,还有一些c++的语法,相比于c个人觉得更加简洁一些。
2.PTA实验作业(0-2分)
2.1.题目1:6-1 jmu-ds-区间删除数据 (20分)
2.1.1代码截图


2.1.2本题PTA提交列表说明。
![]()
部分正确:有个测试点没有通过,应为格式问题
2.2.题目2:6-11 jmu-ds-链表分割 (20分)
2.2.1代码截图

2.2.2本题PTA提交列表说明。
答案错误:一开始没理清题意,写的代码能输出但是只有一堆乱码
段错误:大部分都是调试内存访问出错而引起的程序崩溃,由于提交了很多次导致提交错误列表很长,后面画了画图才写出来,由此感觉到画图在线性表的学习中是真的有助于理解和思考的
编译错误:语法问题,少个条件
2.3.题目3:6-8 jmu-ds-链表倒数第m个数 (20分)
2.3.1代码截图

2.3.2本题PTA提交列表说明。

编译错误:代码不完整
部分正确:没有注意输出要求,需要添加m的判定条件使函数能够返回-1
3.阅读代码(0--4分)
3.1 题目及解题代码
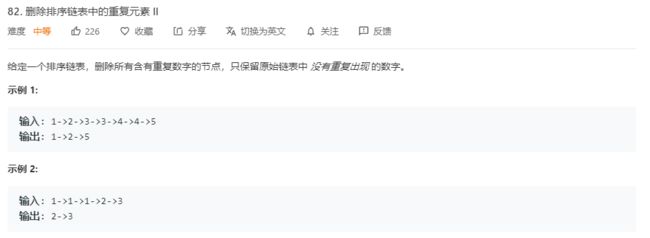
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* deleteDuplicates(struct ListNode* head){
//假设1->1->3->3->4
struct ListNode dummy;
dummy.next = head;
//让cur指向dummy
struct ListNode*cur = &dummy;
while(cur->next && cur->next->next){
if(cur->next->val == cur->next->next->val){// 1->1满足条件
struct ListNode *tmp = cur->next;
while(tmp && tmp->next && tmp->val == tmp->next->val){//不满足
tmp = tmp->next;
}
cur->next = tmp->next;//跳过前面重复节点,直接3->3-4
}
else
cur = cur->next;
}
return dummy.next;
}
3.1.1 该题的设计思路
1.设置dummy节点以便删除头节点重复元素
2.当cur下一段节点为重复节点时,设置临时节点tmp向前探路,当走到重复节点最后一个节点时,让cur->next = tmp->next。
3.1.2 该题的伪代码
while cur->next和cur->next->next 不为空
if 满足重复的条件
struct ListNode *tmp = cur->next;
while 遇到重复元素
tmp指向下一节点
cur下一节点指向tmp下一节点
else 不重复
cur指向下一节点;
end if
返回dummy.next;
3.1.3 运行结果

3.1.4分析该题目解题优势及难点
设置了一个临时节点tmp,当操作指针遇到重复的元素时,就用tmp向下探路,直到遇到不重复的节点为止,直接跳过了前面重复的节点,成功将重复元素删去,这个探路指针既是难点也是巧妙之处
3.2 题目及解题代码
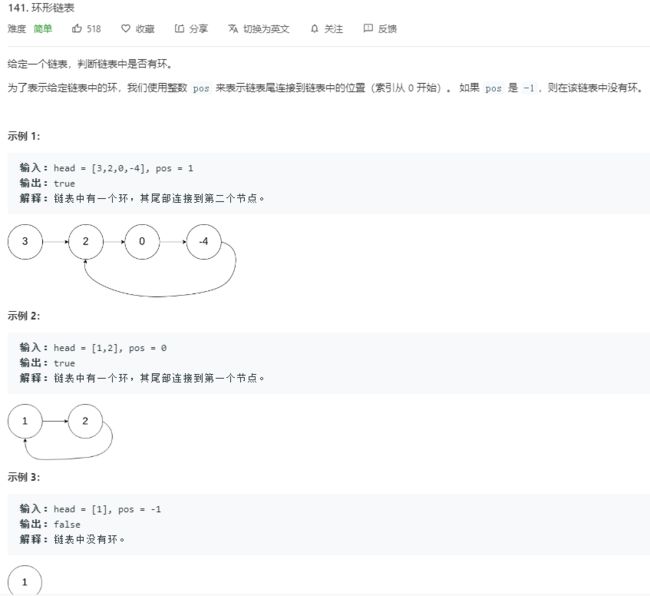
class Solution {
public:
bool hasCycle(ListNode* head)
{
//两个运动员位于同意起点head
ListNode* faster{ head }; //快的运动员
ListNode* slower{ head }; //慢的运动员
if (head == NULL) //输入链表为空,必然不是循环链表
return false;
while (faster != NULL && faster->next != NULL)
{
faster = faster->next->next; //快的运动员每次跑两步
slower = slower->next; //慢的运动员每次跑一步
if (faster == slower) //他们在比赛中相遇了
return true; //可以断定是环形道,直道不可能相遇
}
return false; //快的运动员到终点了,那就是直道,绕圈跑不会有终点
}
};
3.2.1 该题的设计思路
假如该链表是循环链表,定义了两个指针,一个每次向前移动两个节点,另一个每次向前移动一个节点。这就和田径比赛是一样的,假如这两个运动员跑的是直道,那快的运动员和慢的运动员在起点位于同一位置,但快的运动员必将先到达终点,期间这两个运动员不会相遇。而如果绕圈跑的话(假设没有米数限制),跑的快的运动员在超过跑的慢的运动员一圈的时候,他们将会相遇,此刻就是循环链表。
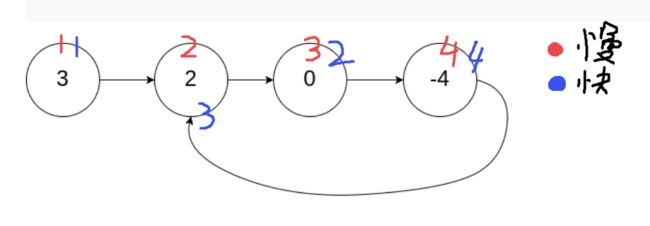
3.2.2 该题的伪代码
while faster不为空
faster向下移动两次
slower向下移动一次
if 相等
相遇,返回true
end if
end while
未相遇,返回false
3.2.3 运行结果
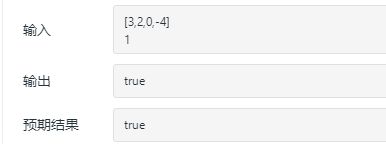
3.2.4分析该题目解题优势及难点
运用了快慢指针来判断是否为循环链表的问题,巧妙地利用了循环链表和非循环链表之间的差别