
数据集
约瑟夫海勒捕捉22是我最喜欢的小说。我最近读完了 ,并喜欢整本书中语言的创造性使用和荒谬人物的互动。对于我的可视化类,选择文本作为我的最终项目“数据集”是一个简单的选择。该文有大约175,000个单词,分为42章。我在网上找到了这本书的原始文本版本并开始工作。
我使用正则表达式和简单字符串匹配的组合在Python中解析文本。
我shiny在R中以交互方式可视化这些数据集。
地中海旅行
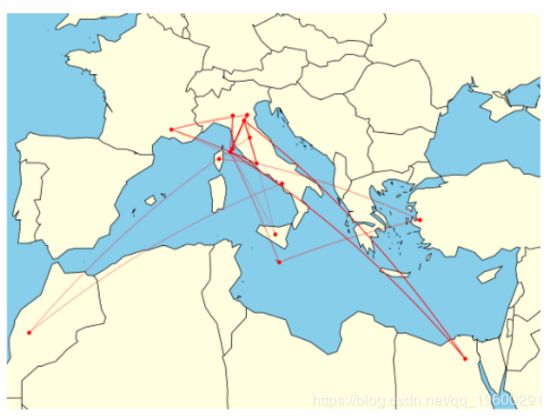
这种可视化映射了整本书中提到的地中海周围位置的提及。
人物形象

该图基本上代表了书中提到不同字符的时间序列。
我将数据绘制为标准散点图,章节为x轴(因为它与时间相似),字符为离散y轴,垂直条为标记。
人物共同出现

用于构建此可视化的数据与前一个中使用的数据完全相同,但需要进行大量转换才能将其转换为可表示这些模式的形式。
聚类为此图添加了另一个维度。在整本书上应用分层聚类方案,以尝试在角色中找到社区。再次,使用章节(1表示现在,0表示不存在)和42维欧几里德距离用于使用完整链接AGNES算法对字符进行聚类。对不同聚类方案和距离测量的树状图进行人工检查发现,这是最“水平”,因为更频繁出现的角色占主导地位的方案最少。这是六个簇的树形图:
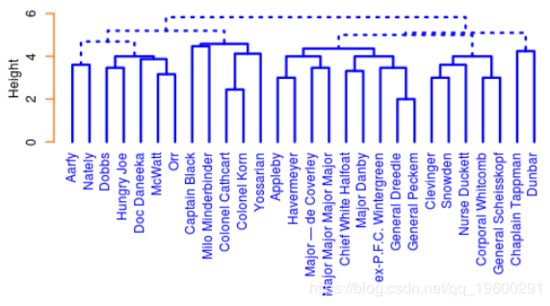
当用户选择通过聚类对图进行着色时,用于共享相同聚类的字符的共同位置的单元用唯一颜色填充,而显示来自不同社区的字符的共同位置的那些单元用灰色阴影。应该注意,聚类是在整个文本上执行的,而不是由应用程序的用户放大的章节。我觉得动态改变聚类会让人分心。
字母或频率排序将群集“爆炸”成无法识别的空间,但按群集排序会将它们带入紧密的社区,让观众也可以看到群集之间的某些交互。
我对共同位置的编码和应用于每个单元的阴影的映射肯定会引起争论,而其他聚类方法导致找到非常不同的社区。也就是说,从定性上讲,我花了很多时间用我自己的文本知识来评估结果,发现当前的实现比我测试的任何其他实现更令人满意。
我发现书中的每个主角在某些时候与几乎所有其他角色互动都非常有趣。我不会期望这么多重叠。与Les Mis相比,情节更加密集,我怀疑这是由于聚集的章节数量的10倍差异。
特色词

这个图可能是四个图中最常规的图,但可能显示了对文本的很多见解。
我可以选择为此可视化选择堆叠条形图或堆积区域图。我喜欢堆积区域图更好地显示单词突出的连续章节,但是承认当章节之间存在高度可变性时,三角形形式会扭曲关系。
结论
我在这个过程中学到了很多东西,无论是在使用方面,还是在shiny本身方面。