详解字典树(Trie)
本篇随笔简单讲解一下信息学奥林匹克竞赛中的较为常用的数据结构——字典树。字典树也叫Trie树、前缀树。顾名思义,它是一种针对字符串进行维护的数据结构。并且,它的用途超级广泛。建议大家熟练掌握。
字典树的概念
字典树,顾名思义,是关于“字典”的一棵树。即:它是对于字典的一种存储方式(所以是一种数据结构而不是算法)。这个词典中的每个“单词”就是从根节点出发一直到某一个目标节点的路径,路径中每条边的字母连起来就是一个单词。
上图理解:
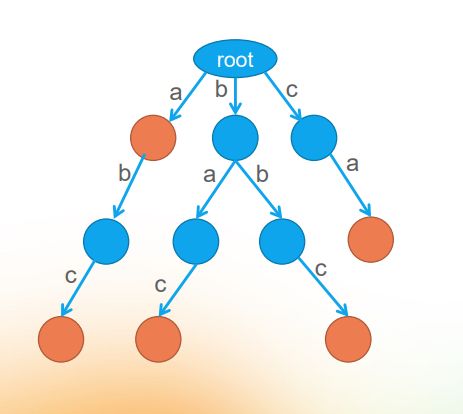
(标橙色的节点是“目标节点“,即根节点到这个目标节点的路径上的所有字母构成了一个单词。)
从这张图我们可以看出,字典树就是一棵树(emm...有些废话的嫌疑),只不过,这棵树的每条边上都有一个字母,然后这棵树的一些节点被指定成了标记节点(目标节点)而已。
这就是字典树的概念。结合上面说的概念,上图所示的字典树包括的单词分别为:
a
abc
bac
bbc
ca
字典树的功能
根据字典树的概念,我们可以发现:字典树的本质是把很多字符串拆成单个字符的形式,以树的方式存储起来。所以我们说字典树维护的是”字典“。那么根据这个最基本的性质,我们可以由此延伸出字典树的很多妙用。简单总结起来大体如下:
-
1、维护字符串集合(即字典)。
-
2、向字符串集合中插入字符串(即建树)。
-
3、查询字符串集合中是否有某个字符串(即查询)。
-
4、统计字符串在集合中出现的个数(即统计)。
-
5、将字符串集合按字典序排序(即字典序排序)。
-
6、求集合内两个字符串的LCP(Longest Common Prefix,最长公共前缀)(即求最长公共前缀)。
我们可以发现,以上列举出的功能都是建立在“字符串集合”的基础上的。再一次强调,字典树是“字典”的树,一切功能都是“字典”的功能。这也为我们使用字典树的时候提供了一个准则:看到一大堆字符串同时出现,就往哈希和Trie树那边想一下。
字典树的实现及代码实现
把上面的图搬下来...
字典树的两种基本操作分别是建树和查询。其中建树操作就是把一个新单词插入到字典树里。查询操作就是查询给定单词是否在字典树上。
那我们来想一下。
插入操作
假如这个字典只包括26个英文字母(暂且都定为小写),那么这个树的深度会由具体单词不一样而定。但是它的广度范围是可以提前确定好的。对于每个节点,广度最大为26。(因为每个节点的下一个字母(即后缀点)只可能是26个字母。)那么我们可以用结构体开好这个“虚拟全树”(这个名字是笔者自己起的,请大家好好理解)。然后通过深度迭代向里面尝试加入单词。
我们开一个包含\(26\)个后缀指针的结构体。用变量\(now\)来表示指向当前节点编号的一个指针,用\(tot\)变量表示点的编号。\(end\)数组表示当前单词的“目标节点”即单词结尾的那个节点具体是哪个单词的词尾。
那么代码就长成这样:
struct node
{
int nxt[27];
}trie[maxn];
int insert(char s[],int id)
{
int now=0;
int len=strlen(s);
for(int i=0;i查询操作
查询操作和刚刚的思路大同小异,因为我们已经有了一个“虚拟全树”,那么我们还是按深度向下迭代,对于需要查询的字符串的当前字符,如果这个对应的字符指针为空,就说明不含这个单词,直接跳出即可。当我们都迭代完成之后,直接返回\(end[now]\)即可。(注意,这里不能直接返回\(1\)或\(true\),假如字典中只保存了一个字符串\(abcdef\),而我们查询的是\(abc\),它可以不被跳出地一直迭代到最后,但是它并不是字典中的单词。即,需要考虑字典中单词子串的情况)。
代码:
bool search(char s[])
{
int len=strlen(s);
int now=0;
for(int i=0;i