这几章我们聊聊集成学习,集成学习算法是目前为止我们在相同特征条件下做特征工程时,建立模型评分和效果最好的算法。比之前讲过的线性回归、Logist回归、KNN、决策树的评分效果都好。
集成学习的讲解分三个部分:Bagging-自举汇聚、Boosting-提升算法、Stacking-模型融合。注意:Stacking模型是一个很有趣的算法,在比赛中用到有时候效果会出奇得好,但有时候会出现画蛇添足的效果,需要大家在比赛中自己体会一番,这个后续我们会讲到。
Bagging算法:随机森林,随机森林的思想就是Bagging算法的核心思想。
Boosting算法:集成学习中最重点的内容,GBDT-迭代决策树/梯度提升决策树、Adaboost-自适应提升、XGBoost、LightGBM。
在比赛中XGBoost算法用得比较多,模型效果相当不错。
此外需要进一步研究学习的一个重要算法是LightGBM,这是微软算法研究团队推出的一套,以直方图为标准的提升算法。其运算效率在集成学习算法中是最快的。
一、为什么要进行集成学习
集成学习的思想是将若干个学习器(分类器、回归器)组合之后产生一个新的学习器。
弱分类器(weak learner): 指那些分类准确率值只稍好于随机猜测的分类器(error<0.5);
集成算法的成功在于保证弱分类器的多样性。而且集成不稳定的算法也能够得到一个比较明显的性能提升。
选择集成学习主要原因:
1、弱分类器间存在一定的差异性,这会导致分类的边界不同,也就是说可能存在错误。那么将多个若分类器合并后,就可以得到更加合理的边界,减少整体的错误率,实现更好的效果。
2、对于数据集过大或者过小,可以分别进行划分和有放回的操作,产生不同的数据子集,然后使用数据子集训练不同的分类器,最终再合并成一个大分类器。
3、如果数据的划分边界过于复杂,使用线性模型很难描述情况,那么可以训练多个模型,然后再进行模型的融合。
4、对于多个异构的特征集,很难进行融合。那么可以考虑为每个数据集构建一个分类模型,然后将多个模型融合。
例 - 在实际工作中很可能拿到如下的数据类型,如何将ABC三个数据集合并?
A数据集:x1-物品大类,x2-金额 | Y-点击次数
①:电脑、10000 | 点了
②:日用品、50 | 没点
B数据集(电脑):x1-CPU型号,x2-显卡 | Y-电脑的类型
①:I7、1080 | 苹果
②:I5、1070 | IBM
C数据集(日用品):.....
方法:构建多个分类模型,最终将模型进行融合。
A数据集中,将电脑和日用品进行分类,分成两个大类。
A-电脑和B结合,生成一个模型进行预测。
A-日用品和C结合,生成一个模型进行预测。
最后得到的模型进行融合。
二、Bagging方法
Bagging方法又称自举汇聚法,思想是:在原始数据集上,通过有放回的抽样的方法,重新选择出S个新数据集来分别训练S个分类器的集成技术。即:这些模型训练的数据中允许存在重复的数据。

之前讲过,这里回顾一下:从m个样本中,抽取出m个新的观测值,此时任意一个样本没有被抽到的概率为36.8%。
解析:某个样本一次被抽到的概率是1/m ,那么一次没有被抽到的概率就是 1-1/m,m次都没有抽取到的联合概率是 (1-1/m)m 即样本没有出现在新的数据集中的概率。假如样本的数据集足够的大,即当m趋向于无穷大的时候求出的极限为1/e,约等于36.8%。
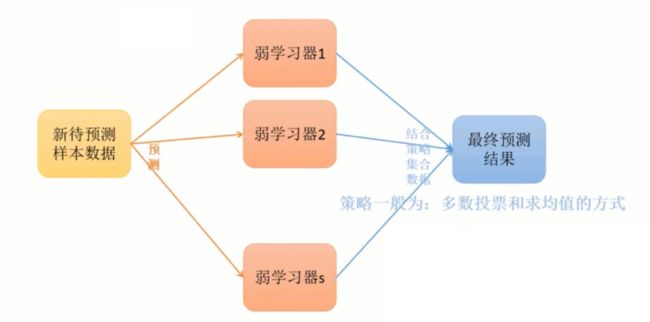
Bagging方法训练出的模型在预测新样本分类时,会使用多数投票、求均值的方式来统计最终分类结果。
Bagging方法的弱学习器可以是基本的算法模型:Linear、Ridge、Lasso、Logistic、Softmax、ID3、C4.5、CART、SVM、KNN等。
总结: Bagging是有放回的抽样,并且每个自己的样本数量必须和原样本数量一致,允许子集存在重复数据。
三、随机森林(Random Forest)
在Bagging策略的基础上进行修改后的一种算法
1、从原始样本集m个中用Bootstrap采样-有放回重采样,选出m个样本。
2、从所有属性中随机选出k个属性,选择最佳分割属性作为节点创建决策树。
3、重复以上两步s次,即建立s个决策树。
4、这s个决策树形成随机森林,通过投票表决结果,决定数据属于哪一类。
随机森林包含两个随机的层面:样本随机,选择特征随机。
PS:随机森林在传统行业,比如金融行业用的比较多。一般金融行业用到的算法:Logistic回归、决策树、随机森林。但在比赛中随机森林用到的概率比较低,原因在于比赛数据比较复杂,如果没有很好的进行特征工程,那么在训练集上模型的表现就很差了。
比较决策树和随机森林:
决策树做分支的时候,考虑的是所有的属性。而随机森林分支的时候是对随机选出的属性做分类。
决策树的构建方式: 从原始K个特征中,每一个特征都找到当前特征的最优分割点。然后基于最优分割点,找到最优的分割属性。

随机森林的构建方式: 抽取K个特征,找到每个特征的最优分割点,再选择最优的分割属性。

随机森林算法:
1、随机有放回抽样,选取S个数据集,建立S个模型。
2、在每一个基模型构建过程中,对于划分决策树时,随机选择K个特征进行划分。
随机森林算法本身(bagging方法),不会对原有数据集中的数据内容进行改变,只是对数据集进行随机抽样。
四、袋外错误率 - 随机森林的评价指标
袋外: out of bag,error rate
随机森林有一个重要的有点是:没有必要对它进行交叉验证或用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,即在生成过程中就对误差建立了一个无偏估计。
在构建每个树时,我们对训练集使用了不同的bootstrap sample(随机且有放回地抽取)。所以对每棵树而言,假设对第k棵树,大约有1/3的示例没有参与第k课树的生成,它们称为第k棵树的oob样本。
袋外错误率的计算方式:
根据采样的特点我们可以进行oob估计,计算方式如下:
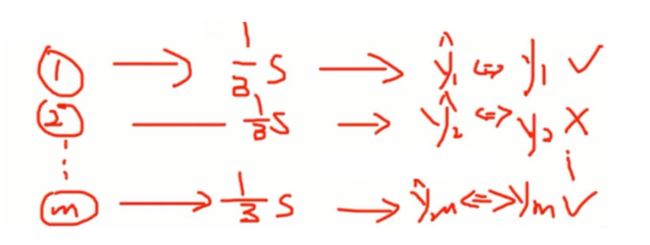
1、对每个样本,计算它作为oob样本的树,对它的分类情况(约1/3的树)。
解释:设有S个树,如上我们所知,任意一个样本大约会出现在2/3S个树上,同时也约有1/3S棵树上没有出现这个样本。这个样本是这1/3S棵树上的oob。这也意味着,这个样本可以作为1/3S棵树上的测试样本。
2、然后以简单多数投票作为该样本的分类结果。
解释:将某个样本放入1/3S棵树上,每个树都会得出一个预测结果,对这1/3S个数据进行投票。
3、最后用误分个数占样本总数的比率,作为随机森林oob的误分率。
解释: 将每个预测结果和真实值进行比较,即ym^ 和 ym 是否相等。找出错误预测的个数占总数m的比率,即随机森林oob的误分率。
oob误分率是随机森林泛化误差的一个无偏估计,它的结果近似于需要大量计算的k折交叉验证。
泛化误差: 测试集上表现好,说明泛化能力强。反之说明泛化能力弱。
袋外错误率 = 测试集的错误率
02 集成学习 - Bagging - 特征重要度、随机森林推广算法