整体背景
本文实现了在colab环境下基于tf-nightly-gpu的BERT中文多分类,如果你在现阶段有实现类似的功能的需求,详细这篇文章会给你带来一些帮助。
准备工作
1.环境:
硬件环境:
直接使用谷歌提供的免费训练环境colab,选择GPU
软件环境:
tensorflow:tensorflow2.1.0版本对BERT的支持有些问题,现象是可以训练但预测时无法正常加载模型(稍后代码里会详述),因此改为选择tf-nightly(主线版本随时会有新变更,如果担心有影响可以选择打tag的dev版本,如笔者验证2.2.0.dev20200218是可以的)
预训练模型:基于tf2.x的中文预训练模型(https://tfhub.dev/tensorflow/bert_zh_L-12_H-768_A-12/1)【注:谷歌基于tf1.x版本公布过一个中文预训练模型(BERT-base,Chinese),根据注释其在tf2.0环境下应该无法使用】
分类代码逻辑:谷歌已经帮我们准备好了基于BERT的分类主程序,其不随tensorflow一起提供,而是单独放在了tensorflow/models下面。models目前也分为发布版和主线版本,本文为了保证分类代码逻辑的稳定,选择发布版models v2.1.0【注:models主线版本近期(2020年2月)有频繁变更,可以看到的是正在对BERT分类逻辑做小规模的重构优化,所以当models 2.2.0的时候,可能分类逻辑会有较大变化】
适配代码:谷歌提供的代码肯定不能直接满足我们自己的需求,所以要对代码进行修改调整,本文也提供了基于models2.1.0版本修改出来的BERT分类适配代码
2.训练数据:
本文从百度百科上爬取了10w左右的词条,按照人物(human)、自然(nature)、地点(poi)、组织(org)、生活(life)等等标注成大概十几个类别。把每个百科词条中的信息按照标题、概述、正文、infobox等分别提取出来并进行简单的清洗操作后,直接连接到一起形成一个长文本。再与百度百科id以及分类标签按照"id\tinfo\tlabel"的格式组织成3列,形成类似于这种格式的训练数据:
bkid info label
---------------
1 xxxx life
2 xxxx human
……
实际数据看起来是这样的:

数据准备好后重新洗牌并按照70%:20%:10%的比例拆分成训练集、验证集和测试集。
代码适配
bert相关代码都在tensorflow/models下面,将models 2.1.0压缩包下载下来后后,BERT分类代码位于:models2.1.0/official/nlp/bert目录下
$ tree . . |-- bert_cloud_tpu.md |-- classifier_data_lib.py # 分类数据方法库 |-- common_flags.py # 通用命令行参数 |-- create_finetuning_data.py # 生成tfrecord格式的微调数据(依赖classifier_data_lib.py) |-- create_pretraining_data.py # 生成预训练数据(只有重新预训练整个模型时才使用,本次不用) |-- custom_metrics.py # 自定义文件,用于计算自定义metrics |-- do_pred_data.py # 自定义文件,用于生成预测数据 |-- do_predict.py # 自定义文件,用于模型训练完成后执行预测 |-- export_tfhub.py |-- export_tfhub_test.py |-- __init__.py |-- input_pipeline.py # 用于加载tfrecord格式的训练数据 |-- model_saving_utils.py # 用于模型保存 |-- README.md |-- run_classifier.py # finetune分类主程序 |-- run_pretraining.py # 预训练主程序(本次不用) |-- run_squad.py # squad主程序(本次不用) |-- squad_lib.py |-- squad_lib_sp.py |-- tf1_checkpoint_converter_lib.py |-- tf2_albert_encoder_checkpoint_converter.py |-- tf2_encoder_checkpoint_converter.py |-- tokenization.py # 分词器 |-- tokenization_test.py `-- utils.py #自定义文件,用于绘制自定义metrics图表 0 directories, 25 files
主要修改点有二:
1. 添加自定义的数据处理器及处理逻辑
2. 原finetune代码只有训练集和验证集的代码流程,本文在整个训练结束后添加了测试集的相关流程。
3. 原代码只系统了训练逻辑,本文添加了训练完成之后的预测逻辑(暂未包括生产环境部署)。
下面对主要修改点进行说明:
1.数据格式转换逻辑:
tensorflow推荐使用tfrecord格式的数据,因此将数据集转换成tfrecord格式并保存下来,便于后续重复使用
文件1:create_finetuning_data.py
a. 添加新的数据处理器:
1 def generate_classifier_dataset(): 2 """Generates classifier dataset and returns input meta data.""" 3 assert FLAGS.input_data_dir and FLAGS.classification_task_name 4 5 processors = { 6 "cola": classifier_data_lib.ColaProcessor, 7 "mnli": classifier_data_lib.MnliProcessor, 8 "mrpc": classifier_data_lib.MrpcProcessor, 9 "qnli": classifier_data_lib.QnliProcessor, 10 "sst-2": classifier_data_lib.SstProcessor, 11 "xnli": classifier_data_lib.XnliProcessor, 12 "bdbk": classifier_data_lib.BdbkProcessor, # 添加新的数据处理器 13 } 14 ......
文件2:classifier_data_lib.py
a. 添加新Processor的处理逻辑:
谷歌预设的数据处理器以及后续的分类逻辑中,都只使用了训练集和验证集,本文在此基础上,增加了测试集和预测集的数据处理和使用
1 class BdbkProcessor(DataProcessor): 2 """Processor for bdbk data set.""" 3 4 def get_train_examples(self, data_dir): 5 """See base class.""" 6 return self._create_examples(self._read_tsv(os.path.join(data_dir, "train.tsv")), "train") 7 8 def get_dev_examples(self, data_dir): 9 """See base class.""" 10 return self._create_examples(self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev") 11 12 def get_test_examples(self, data_dir): 13 """See base class.""" 14 return self._create_examples(self._read_tsv(os.path.join(data_dir, "test.tsv")), "test") 15 16 def get_predict_examples(self, data_dir): 17 return self._create_examples(self._read_tsv(os.path.join(data_dir, "predict.tsv")), "predict") 18 19 def get_labels(self): 20 """See base class.""" 21 return [ 22 'human', 23 'poi', 24 'nature', 25 ... 此处根据你的需要,定义自己的类别标签 26 ] 27 @staticmethod 28 def get_processor_name(): 29 """See base class.""" 30 return "BDBK" 31 32 def _create_examples(self, lines, set_type): 33 """Creates examples for the training and dev sets.""" 34 examples = [] 35 for (i, line) in enumerate(lines): 36 guid = "%s-%s" % (set_type, i) 37 if i == 0: # 如果你的数据有标题行,就加上这两句代码跳过 38 continue 39 text_a = self.process_text_fn(line[1]) # line[1]列是文本 40 label = self.process_text_fn(line[2]) if len(line) >= 3 else "na" # line[2]列是标签 41 examples.append(InputExample(guid=guid, text_a=text_a, text_b=None, label=label)) 42 return examples
2.训练、验证及测试逻辑:
对tfrecord数据读取、模型训练结果存储等功能进行调整
文件1:run_classifier.py
run_classifier是分类主程序入口,涵盖了预训练模型加载、分类模型构建及编译、输入数据读取、模型训练和评估、产出训练结果等全过程。
其中分类模型构建环节中没有添加其他分类网络,即直接用BERT预训练模型的输出对接dropout(抑制过拟合)层后,直接接fc层产出各个类别的概率。此处也可以自定义其他网络结构,比如BERT的输出对接一个TextCNN,然后再接fc层(这种网络结构也可以理解成BERT作为word embedding层,TextCNN作为分类模型)。本文中采用第一种默认结构,即BERT+dropout+fc,网络模型结构如下:
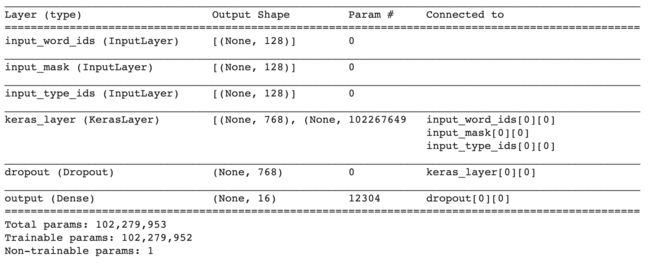
a. 添加一些epoch结尾的评估metrics,便于评估训练效果
1 eval_data_list = list(evaluation_dataset.as_numpy_iterator()) 2 custom_metric = custom_metrics.Metrics(labels_list, valid_data=eval_data_list[0]) 3 4 if custom_callbacks is not None: 5 custom_callbacks += [custom_metric, summary_callback, checkpoint_callback] 6 else: 7 custom_callbacks = [custom_metric, summary_callback, checkpoint_callback] 8 9 history = bert_model.fit( 10 x=training_dataset, 11 validation_data=evaluation_dataset, 12 steps_per_epoch=steps_per_epoch, 13 epochs=epochs, 14 validation_steps=eval_steps, 15 callbacks=custom_callbacks) 16 17 return bert_model, history, custom_metric
文件2:model_saving_utils.py
a. 在export_bert_model()最后添加训练结果保存逻辑
# tf.train.Checkpoint API was used via custom training loop logic. else: checkpoint = tf.train.Checkpoint(model=model) # Restores the model from latest checkpoint. latest_checkpoint_file = tf.train.latest_checkpoint(checkpoint_dir) assert latest_checkpoint_file logging.info('Checkpoint file %s found and restoring from ' 'checkpoint', latest_checkpoint_file) checkpoint.restore( latest_checkpoint_file).assert_existing_objects_matched() model.save(model_export_path, include_optimizer=True, overwrite=True, save_format='h5') # 添加训练结果保存 return
b. 新增custom_metrics.py,用于在on_epoch_end中计算自定义metrics
from sklearn.metrics import f1_score, recall_score, precision_score, classification_report from tensorflow.keras.callbacks import Callback import numpy as np class Metrics(Callback): def __init__(self, labels_list, valid_data): super(Metrics, self).__init__() self.validation_data = valid_data self.val_f1s = [] self.val_recalls = [] self.val_precisions = [] self.reports = [] self.labels_list = labels_list def on_epoch_end(self, epoch, logs=None): logs = logs or {} val_predict = np.argmax(self.model.predict(self.validation_data[0]), -1) val_targ = self.validation_data[1] if len(val_targ.shape) == 2 and val_targ.shape[1] != 1: val_targ = np.argmax(val_targ, -1) # 分别计算macro f1, recall, precision _val_precision = precision_score(val_targ, val_predict, average='macro') self.val_precisions.append(_val_precision) logs['val_precision'] = _val_precision _val_recall = recall_score(val_targ, val_predict, average='macro') self.val_recalls.append(_val_recall) logs['val_recall'] = _val_recall _val_f1 = f1_score(val_targ, val_predict, average='macro') self.val_f1s.append(_val_f1) logs['val_f1'] = _val_f1 remain_list = [] val_union = np.union1d(val_targ, val_predict) for i, v in enumerate(self.labels_list): if i in val_union: remain_list.append(v) # 一并计算三个指标 report = classification_report(val_targ, val_predict, target_names=remain_list, output_dict=True) def get(self, metrics, of_class): return [report[str(of_class)][metrics] for report in self.reports]
c. 新增utils.py,用于绘制训练结果图
#-*- encoding:utf-8 -*- import pickle import matplotlib.pyplot as plt import matplotlib.style as style class MetricPlot(object): def __init__(self, file_pickle_path): self.file_pickle = file_pickle_path def draw_all_curves(self): with open(self.file_pickle + '/metric/metric.pickle', 'rb') as f: metric_data = pickle.load(f) reports = metric_data['reports'] style.use("bmh") class_list = [] for report in reports: class_list.extend(list(report.keys())) class_list = list(set(class_list)) class_list.remove('accuracy') class_list.remove('macro avg') class_list.remove('weighted avg') # 每个类别分别打印precision、recall、f1 class_num = len(class_list) # 每个类别分别打印precision、recall、f1 class_num = len(class_list) plt.figure(figsize=(8, class_num * 4)) for i, v in enumerate(class_list): plt.subplot(class_num, 1, i + 1) for m in {'precision', 'recall', 'f1-score'}: plt.plot([report[v][m] for report in reports], label='Class {0} {1}'.format(v, m)) plt.legend(loc='lower right') plt.ylabel('Class {}'.format(v)) plt.title('Class {} Curves'.format(v)) plt.show() def draw_metric_curves(self): with open(self.file_pickle + '/metric/metric.pickle', 'rb') as f: metric_data = pickle.load(f) f1 = metric_data['f1'] recall = metric_data['recall'] precision = metric_data['precision'] epochs = len(f1) style.use("bmh") plt.figure(figsize=(8, 12)) plt.subplot(3, 1, 1) plt.plot(range(1, epochs+1), f1, label='Val F1') plt.legend(loc='lower right') plt.ylabel('F1') plt.title('Validation F1 Curve') plt.subplot(3, 1, 2) plt.plot(range(1, epochs+1), recall, label='Val Recall') plt.legend(loc='lower right') plt.ylabel('Recall') plt.title('Validation Recall Curve') plt.subplot(3, 1, 3) plt.plot(range(1, epochs+1), precision, label='Val Precision') plt.legend(loc='lower right') plt.ylabel('Precision') plt.title('Validation Precision Curve') plt.xlabel('epoch') plt.show() def draw_history_curves(self): """Plot the learning curves of loss and macro f1 score for the training and validation datasets. Args: history: history callback of fitting a tensorflow keras model """ with open(self.file_pickle + '/history/hist.pickle', 'rb') as f: history = pickle.load(f) loss = history['loss'] val_loss = history['val_loss'] accuracy = history['test_accuracy'] val_accuracy = history['val_test_accuracy'] epochs = len(loss) style.use("bmh") plt.figure(figsize=(8, 8)) plt.subplot(2, 1, 1) plt.plot(range(1, epochs+1), loss, label='Training Loss') plt.plot(range(1, epochs+1), val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.plot(range(1, epochs+1), val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.ylabel('Loss') plt.title('Training and Validation Loss') plt.subplot(2, 1, 2) plt.plot(range(1, epochs+1), accuracy, label='Training Accuracy') plt.plot(range(1, epochs+1), val_accuracy, label='Validation Accuracy') plt.legend(loc='lower right') plt.ylabel('Accuracy') plt.title('Training and Validation Accuracy') plt.show()
主要的代码逻辑修改介绍完毕,下面介绍在colab上操作的流程。
三、colab操作:
1.环境部署:
# 安装tf-nightly-gpu,目前master各版本应该均可用(至少2.2.0.dev20200218亲测可用) # 如选择发布版2.1.0,在预测阶段(重新load_model)会触发tf底层的一个bug(https://github.com/tensorflow/neural-structured-learning/issues/41),导致加载模型失败 !pip install tf-nightly-gpu # 下载并解压tensorflow models2.1.0 !wget https://github.com/tensorflow/models/archive/v2.1.0.tar.gz !tar xzf v2.1.0.tar.gz && rm v2.1.0.tar.gz # 安装models需要的依赖 !pip install -r /content/models-2.1.0/official/requirements.txt
2.将修改代码上传到colab,并放置到对应的目录
# 下载数据集合和修改适配的文件 %rm -rf bert_multiclass_zh_model2-1-0/ %rm -rf process_dir # 此处将修改好的代码传到colab上
<下载代码> %mv /content/bert_multiclass_zh_model2-1-0/code/utils.py /content/ %mv /content/bert_multiclass_zh_model2-1-0/code/*.py /content/models-2.1.0/official/nlp/bert/ %mv /content/bert_multiclass_zh_model2-1-0/process_dir /content/
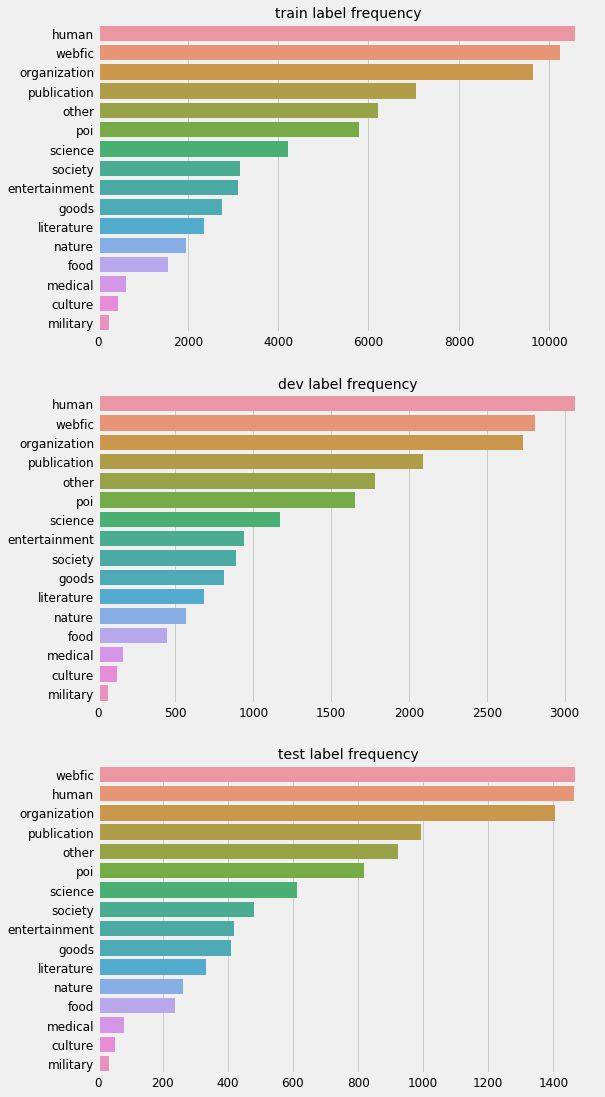
3. 为了对数据有更直观的了解,可以用下面代码对数据的分布进行观察
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import matplotlib.style as style 4 import seaborn as sns 5 6 style.use("fivethirtyeight") 7 plt.figure(figsize=(8, 12)) 8 9 show_data_dict = { 10 'train': pd.read_csv("/content/process_dir/train_data/train.tsv", "\t"), 11 'dev': pd.read_csv("/content/process_dir/train_data/dev.tsv", "\t") 12 } 13 14 # Get label frequencies in descending order 15 length = len(show_data_dict) 16 cnt = 0 17 for k, v in show_data_dict.items(): 18 cnt += 1 19 plt.subplot(length, 1, cnt) 20 label_freq = v['label'].apply(lambda s: str(s)).value_counts().sort_values(ascending=False) 21 # Bar plot 22 sns.barplot(y=label_freq.index, x=label_freq.values, order=label_freq.index) 23 plt.title("{} label frequency".format(k), fontsize=14) 24 plt.xlabel("") 25 plt.xticks(fontsize=12) 26 plt.yticks(fontsize=12) 27 plt.show()
执行后可以看到数据分布情况:
4.生成tfrecord格式的数据:
1 !python ./models/official/nlp/bert/create_finetuning_data.py \ 2 --input_data_dir=${BASE_DIR}/train_data \ 3 --vocab_file=${BASE_DIR}/hub/vocab.txt \ 4 --train_data_output_path=${BASE_DIR}/train_data/${TASK_NAME}_train.tf_record \ 5 --eval_data_output_path=${BASE_DIR}/train_data/${TASK_NAME}_eval.tf_record \ 6 --test_data_output_path=${BASE_DIR}/train_data/${TASK_NAME}_test.tf_record \ 7 --meta_data_file_path=${BASE_DIR}/train_data/${TASK_NAME}_meta_data \ 8 --fine_tuning_task_type=classification \ 9 --max_seq_length=128 \ 10 --classification_task_name=${TASK_NAME}
6. 启动训练:
1 !python ./models/official/nlp/bert/run_classifier.py \ 2 --mode='train_and_eval' \ 3 --input_meta_data_path=${BASE_DIR}/train_data/${TASK_NAME}_meta_data \ 4 --train_data_path=${BASE_DIR}/train_data/${TASK_NAME}_train.tf_record \ 5 --eval_data_path=${BASE_DIR}/train_data/${TASK_NAME}_eval.tf_record \ 6 --test_data_path=${BASE_DIR}/train_data/${TASK_NAME}_test.tf_record \ 7 --bert_config_file=${BASE_DIR}/hub/bert_config.json \ 8 --train_batch_size=64 \ 9 --eval_batch_size=128 \ 10 --test_batch_size=256 \ 11 --steps_per_loop=1 \ 12 --learning_rate=2e-5 \ 13 --num_train_epochs=2 \ 14 --model_dir=${BASE_DIR}/output \ 15 --hub_module_url=https://tfhub.dev/tensorflow/bert_zh_L-12_H-768_A-12/1 \ 16 --use_keras_compile_fit=True \ 17 --distribution_strategy=mirrored \ 18 --num_gpus=1 \ 19 --save_history_path=${BASE_DIR}/history/hist.pickle \ 20 --save_metric_path=${BASE_DIR}/metric/metric.pickle \ 21 --model_export_path=${BASE_DIR}/export_model/save_model.h5 \ 22 --test_result_dir=${BASE_DIR}/test_result/test_ret
因为在run_classifiert.py中model.fit()之前增加了一行model.summary(),所以训练开始前的日志中可见训练图层次结构等信息
整个模型参数都设置为是trainable的(默认值),笔者尝试过修改代码来freeze BERT自带的102267649个参数,但训练10个epoch后,accuracy仍达不到90%以上,感觉效果不是很好。具体原因还未深究。
7. 查看训练结果:
日志中可以查看训练中,每个batch结束后的训练loss、accuracy;每个epoch结束后的val loss、val accuracy;以及整个训练结束后的test accuracy
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',). I0223 04:38:43.759790 140623330674560 cross_device_ops.py:414] Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',). INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',). I0223 04:38:43.761969 140623330674560 cross_device_ops.py:414] Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',). Train for 1093 steps, validate for 313 steps Epoch 1/2 1093/1093 [==============================] - 1161s 1s/step - loss: 0.4250 - accuracy: 0.8925 - val_loss: 0.1785 - val_accuracy: 0.9474 Epoch 2/2 1093/1093 [==============================] - 1144s 1s/step - loss: 0.1220 - accuracy: 0.9664 - val_loss: 0.1622 - val_accuracy: 0.9532 I0223 05:18:29.677855 140623330674560 run_classifier.py:420] test_accuracy: 0.951200008392334
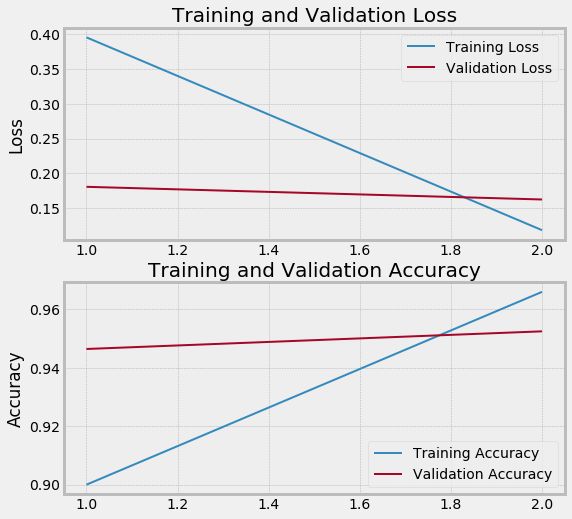
查看原代码里定义的metrics(loss、accuracy),以及自定义的metrics(各类别的F1、precise、recall等)
1 import utils 2 3 mp = utils.MetricPlot('/content/process_dir/') 4 mp.draw_history_curves() 5 mp.draw_metric_curves() 6 mp.draw_all_curves()

训练完成之后,就可以进行预测了。
首先参考create_finetune_data.py,将待预测数据转换为tfrecord格式并存储
# 预测,生成待预测数据 !python ./models-2.1.0/official/nlp/bert/do_pred_data.py \ --input_data_dir=${PRED_DATA_DIR} \ --vocab_file=${BASE_DIR}/model/hub_config/vocab.txt \ --predict_data_output_path=${PRED_DATA_DIR}/${TASK_NAME}_predict.tf_record \ --meta_data_file_path=${PRED_DATA_DIR}/${TASK_NAME}_meta_data \ --max_seq_length=128
然后参照run_classifier.py,读取待预测tfrecord数据,加载之前训练好的模型(save_model.h5),开始预测,将结果保存在文件中
# 开始预测 !python ./models-2.1.0/official/nlp/bert/do_predict.py \ --input_meta_data_path=${PRED_DATA_DIR}/${TASK_NAME}_meta_data \ --predict_data_path=${PRED_DATA_DIR}/${TASK_NAME}_predict.tf_record \ --bert_config_file=${BASE_DIR}/model/hub_config/bert_config.json \ --predict_batch_size=32 \ --hub_module_url=https://tfhub.dev/tensorflow/bert_zh_L-12_H-768_A-12/1 \ --model_export_path=${BASE_DIR}/model/saved_model/save_model.h5 \ --predict_output_dir=${PRED_DATA_DIR}/result \ # 如果选择tf2.1.0版本,则此处会触发tf底层的一个bug(https://github.com/tensorflow/neural-structured-learning/issues/41),导致加载模型失败
最终训练出来的文件内容是这样的:第一列是标签的编号,第二列是标签,由于是串行训练,因此输出的标签和输入的预测文本是一一对齐的。
1 poi 4 webfic 7 science 0 human 0 human 0 human 1 poi 7 science
至此,整个finetuneing训练+预测过程全部结束。欢迎拍砖指导~~~~
稍后再研究一下如何部署到生产环境……