概括
通过Python爬虫实现多线程对于36氪首页氪视频的爬取。
实现
36氪首页:https://36kr.com/
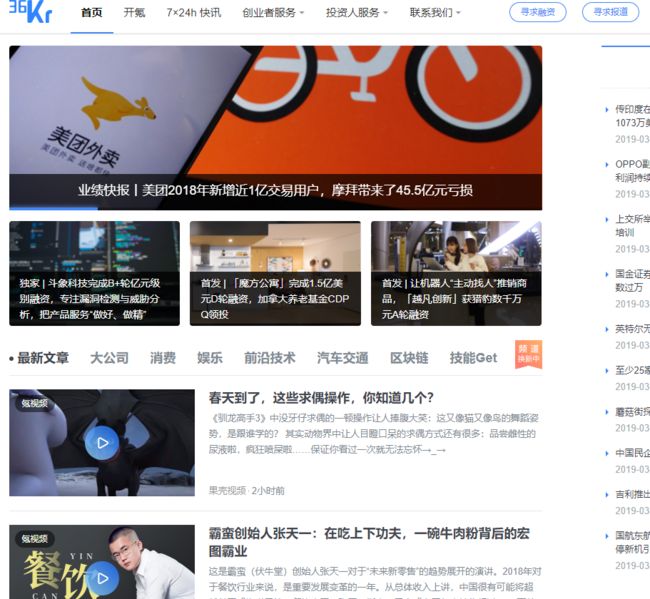
将文章列表往下拉,可以看到首页的文章并没有直接分页,而是当滚动条到达最下方时,自动加载下一页的文章,网页的局部刷新,通过Ajax请求动态获取文章数据。
-
获取Ajax请求的API
通过右键 > 检查,或F12打开浏览器调试模式,选择Network > XHR,此时滚动鼠标滑轮,直到自动刷新出新的文章(或者点击底部的“浏览更多”按钮),就可以获取动态数据包。

复制此接口并在新页面中打开,可以获取到响应的数据,而数据类型也正是Json。
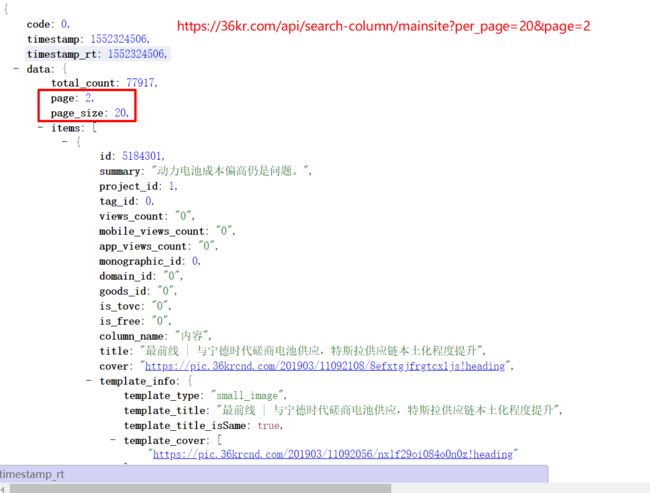
url 后的 per_page 和 page,是发送GET请求时携带的参数,分别是每页文章的个数(图中的page_size)和当前处于哪一页,而另一个参数 _=1552323953341 删掉没有影响,并非为必传参数。到这里就拿到了动态获取文章的接口。(page=1时即为首页所有文章)
https://36kr.com/api/search-column/mainsite?per_page=20&page=1
-
通过 requests 发送请求
import json
import jsonpath
import requests
import re
import time
from queue import Queue
from threading import Thread
class Krspider(object):
def __init__(self):
# 留下page入口以实现获取多页数据
self.base_url = 'https://36kr.com/api/search-column/mainsite?per_page=20&page={}'
self.video_url = 'https://36kr.com/video/{}' # 拼接氪视频详情页url
self.headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
self.url_queue = Queue()
self.send_request_queue = Queue()
self.parse_detail_queue = Queue()
self.detail_data_queue = Queue()
self.parse_video_queue = Queue()
self.count = 0
def send_request(self):
while True:
url = self.url_queue.get()
str_json = requests.get(url, headers=self.headers).content.decode()
self.send_request_queue.put(str_json)
self.url_queue.task_done()
通过 requests 的 get 方法向目标 url 发送 get 请求,str_json 即为响应的 Json 字符串。收发网络请求是耗时的,会产生阻塞,使用多线程,也用到队列模块 Queue,把每个步骤封装成函数,分别用线程去执行,每个步骤间通过队列相互通信,也对函数间解耦。
def run(self):
total_page = int(input('输入要抓取的页数:'))
for page in range(1, total_page + 1):
url = self.base_url.format(page)
self.url_queue.put(url)
通过遍历页数,得到每一页的 url,同时将各个 url 放入到 url 队列 self.url_queue 中。发送请求并接受响应的方法 send_request 会不断的从 url 队列中拿出 每一页的 url,并发送请求。将收到的每一页返回的Json字符串放入到 self.send_request_queue 队列中。
-
解析氪视频页面的url
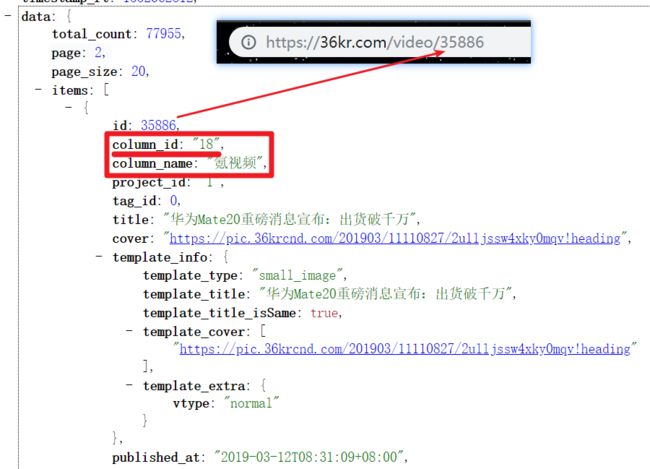
首页的文章分类有很多,有“教育”、“消费”、“氪视频”等,而我们只需要氪视频的 url,可以看到氪视频分类的 column_id 是 “18”,而 url 是 https://36kr.com/video/ + id 拼接而来。
从 self.send_request_queue 队列中取到每个页面的 Json 字符串,通过 json.loads() 将 Json 字符串转为字典。
data_dict = json.loads(data)
再通过 jsonpath 将所氪视频文章取出,返回一个列表,列表中每个字典就是每一个氪视频文章数据。
# 通过 column_id = "18"取出当前页面所有氪视频文章的字典
video_news_list = jsonpath.jsonpath(data_dict, '$..items[?(@.column_id=="18")]')
遍历 video_news_list 列表,在每个氪视频文章字典中通过“title”、“id”两个键取出对应的标题和 id,这个 id 用于拼接氪视频详情页面的 url
for video_dict in video_news_list:
title = video_dict['title']
url = self.video_url.format(video_dict['id'])
解析全过程:
def parse_detail(self):
while True:
data = self.send_request_queue.get()
data_dict = json.loads(data)
video_news_list = jsonpath.jsonpath(data_dict, '$..items[?(@.column_id=="18")]')
for video_dict in video_news_list:
title = video_dict['title']
url = self.video_url.format(video_dict['id'])
# 将标题和 url 组成的列表放入 self.parse_detail_queue 队列中
self.parse_detail_queue.put([title, url])
self.send_request_queue.task_done()
-
解析视频MP4文件的url
-
向详情页发送请求,获取响应
def send_detail_request(self):
while True:
video_list = self.parse_detail_queue.get()
data = requests.get(video_list[1], headers=self.headers).content.decode()
# 将响应字符串和标题组成的列表放入队列
self.detail_data_queue.put([data, video_list[0]])
self.parse_detail_queue.task_done()
-
解析详情页响应,获取MP4文件的url
def parse_video_url(self):
while True:
list = self.detail_data_queue.get()
pattern = re.compile('http://video\.chuangkr\.china\.com\.cn/.*vb1152\.mp4?')
try:
# 响应字符串正则匹配,获得 MP4文件的 url
str = pattern.search(list[0]).group()
video_url = str.split(',')[-1].lstrip('"url_1152":"')
except AttributeError:
pass
else:
if video_url:
# 将 MP4 文件 url 和标题组成列表放入队列
self.parse_video_queue.put([video_url, list[1]])
else:
pass
self.detail_data_queue.task_done()
响应字符串中有多个 MP4 文件的 url,但是清晰度却不同,分别以“vb_384.mp4”、“vb_512.mp4”、“vb_1152.mp4”结尾,这里获取清晰度最高的以“vb_1152.mp4”结尾的文件 url


-
获取 MP4 文件数据并保存
有了 MP4 文件的url,最后一步就是发送请求获取响应数据并保存。
def receive_down_load_video(self):
while True:
list = self.parse_video_queue.get()
video_url = list[0]
title = list[1]
print('开始下载:[{}]'.format(title))
start = time.time()
data = requests.get(video_url, headers=self.headers, stream=True).content
file_name = title[:10] # 标题前8位作为文件名
file_path = 'video_36kr/' + file_name + '.mp4'
with open(file_path, 'wb') as f:
f.write(data)
end = time.time()
print('\n' + '[%s]下载完成,用时%.2f秒' % (title, (end - start)))
self.count += 1
self.parse_video_queue.task_done()
-
run() 方法开启多线程
def run(self):
total_page = int(input('输入要抓取的页数:'))
start = time.time()
for page in range(1, total_page + 1):
url = self.base_url.format(page)
self.url_queue.put(url)
th_list = []
for i in range(3):
send_th = Thread(target=self.send_request)
th_list.append(send_th)
parse_th = Thread(target=self.parse_detail)
th_list.append(parse_th)
send_detail_th = Thread(target=self.send_detail_request)
th_list.append(send_detail_th)
parse_video_th = Thread(target=self.parse_video_url)
th_list.append(parse_video_th)
download_th = Thread(target=self.receive_down_load_video)
th_list.append(download_th)
for th in th_list:
th.setDaemon(True) # 把子线程设置为守护线程,主线程结束,子线程也结束
th.start()
for q in [self.url_queue, self.send_request_queue, self.parse_detail_queue, self.detail_data_queue, self.parse_video_queue]:
q.join() # 队列计数不为0的时候让主线程阻塞等待,队列计数为0的时候主线程才会继续往后执行
end = time.time()
print('>>>全部下载完成,总耗时%s秒<<<' % (end - start))
print('共下载视频个数:{}'.format(self.count))
把每个子线程都设置为守护线程,主线程结束,所有子线程结束。而当每一个任务队列计数不为0,即还有任务没有被执行时,主线程阻塞,当所有队列计数都为0,即所有任务被执行,主线程往后执行并结束,所有的子线程也随之结束(while True 循环停止)。
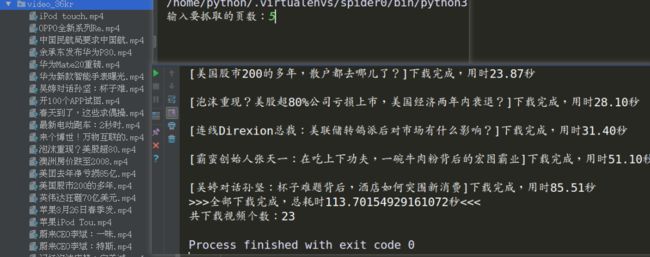
最后来尝试运行一下程序,抓取前5页的视频:
播放一个视频:
最后是整个程序的代码:
import json
import jsonpath
import requests
import re
import time
from queue import Queue
from threading import Thread
class Krspider(object):
def __init__(self):
# 留下page入口以实现获取多页数据
self.base_url = 'https://36kr.com/api/search-column/mainsite?per_page=20&page={}'
self.video_url = 'https://36kr.com/video/{}' # 拼接氪视频详情页url
self.headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
self.url_queue = Queue()
self.send_request_queue = Queue()
self.parse_detail_queue = Queue()
self.detail_data_queue = Queue()
self.parse_video_queue = Queue()
self.count = 0
def send_request(self):
while True:
url = self.url_queue.get()
str_json = requests.get(url, headers=self.headers).content.decode()
self.send_request_queue.put(str_json)
self.url_queue.task_done()
def parse_detail(self):
while True:
data = self.send_request_queue.get()
data_dict = json.loads(data)
video_news_list = jsonpath.jsonpath(data_dict, '$..items[?(@.column_id=="18")]')
for video_dict in video_news_list:
title = video_dict['title']
url = self.video_url.format(video_dict['id'])
# 将标题和 url 组成的列表放入 self.parse_detail_queue 队列中
self.parse_detail_queue.put([title, url])
self.send_request_queue.task_done()
def send_detail_request(self):
while True:
video_list = self.parse_detail_queue.get()
data = requests.get(video_list[1], headers=self.headers).content.decode()
# 将响应字符串和标题组成的列表放入队列
self.detail_data_queue.put([data, video_list[0]])
self.parse_detail_queue.task_done()
def parse_video_url(self):
while True:
list = self.detail_data_queue.get()
pattern = re.compile('http://video\.chuangkr\.china\.com\.cn/.*vb1152\.mp4?')
try:
# 响应字符串正则匹配,获得 MP4文件的 url
str = pattern.search(list[0]).group()
video_url = str.split(',')[-1].lstrip('"url_1152":"')
except AttributeError:
pass
else:
if video_url:
# 将 MP4 文件 url 和标题组成列表放入队列
self.parse_video_queue.put([video_url, list[1]])
else:
pass
self.detail_data_queue.task_done()
def receive_down_load_video(self):
while True:
list = self.parse_video_queue.get()
video_url = list[0]
title = list[1]
print('开始下载:[{}]'.format(title))
start = time.time()
data = requests.get(video_url, headers=self.headers, stream=True).content
file_name = title[:10] # 标题前8位作为文件名
file_path = 'video_36kr/' + file_name + '.mp4'
with open(file_path, 'wb') as f:
f.write(data)
end = time.time()
print('\n' + '[%s]下载完成,用时%.2f秒' % (title, (end - start)))
self.count += 1
self.parse_video_queue.task_done()
def run(self):
total_page = int(input('输入要抓取的页数:'))
start = time.time()
for page in range(1, total_page + 1):
url = self.base_url.format(page)
self.url_queue.put(url)
th_list = []
for i in range(3):
send_th = Thread(target=self.send_request)
th_list.append(send_th)
parse_th = Thread(target=self.parse_detail)
th_list.append(parse_th)
send_detail_th = Thread(target=self.send_detail_request)
th_list.append(send_detail_th)
parse_video_th = Thread(target=self.parse_video_url)
th_list.append(parse_video_th)
download_th = Thread(target=self.receive_down_load_video)
th_list.append(download_th)
for th in th_list:
th.setDaemon(True) # 把子线程设置为守护线程,主线程结束,子线程也结束
th.start()
for q in [self.url_queue, self.send_request_queue, self.parse_detail_queue, self.detail_data_queue,
self.parse_video_queue]:
q.join() # 队列计数不为0的时候让主线程阻塞等待,队列计数为0的时候主线程才会继续往后执行
end = time.time()
print('>>>全部下载完成,总耗时%s秒<<<' % (end - start))
print('共下载视频个数:{}'.format(self.count))
if __name__ == '__main__':
Krspider().run()