flink内部通信机制
- Operator间的数据传递
- 本地线程数据传递
- 远程线程数据传递
- 同一线程的Operator数据传递
- Buffer读写
- Buffer读取
- Buffer写入
- 内存管理
- MemorySegment和Buffer
- MemorySegment和Buffer的读写
当我们编写一个Flink任务时,抽象来说,是在描绘一个有向图。图中的边相当于由一系列数据记录组成的数据流,图中的顶点相当于我们对数据流的处理。 接下来的内容将在自顶向下地介绍有向图中的数据流是怎么在顶点间传递的。
为了统一术语,先简单介绍Flink中的术语使用。
- Operator和Stream: 是Flink编程模型的基础组成。Flink编程模型由Stream(DataSet内部也是Stream组成的)和StreamOperator组成。Stream代表由一系列数据记录(data records)组成的数据流。一般情况下,Stream从SourceOperator开始,到SinkOperator结束。而TransformationOperator消费一个或多个stream,对stream进行处理,最后生产出一个或多个stream作为处理结果。
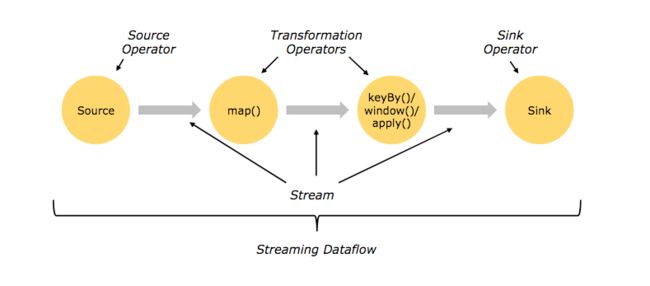
- Task: Operator是编程视图中的有向图顶点(Node),而Task则是运行视图中的有向图顶点。增加Operator的并行度相当于增加运行这个Operator的SubTask。一个SubTask相当于一个线程。 一个Task可以由多个SubTask组成, 一个SubTask可以由多个Operator组成。
综上,本文所指的Flink的通信即是指Operator间的数据传递。存在上下游关系的Operator可能在同一SubTask中,可能在同一进程的不同SubTask中(本地线程通信),也可能在不同进程的不同SubTask中(远程线程通信)。
Operator间的数据传递
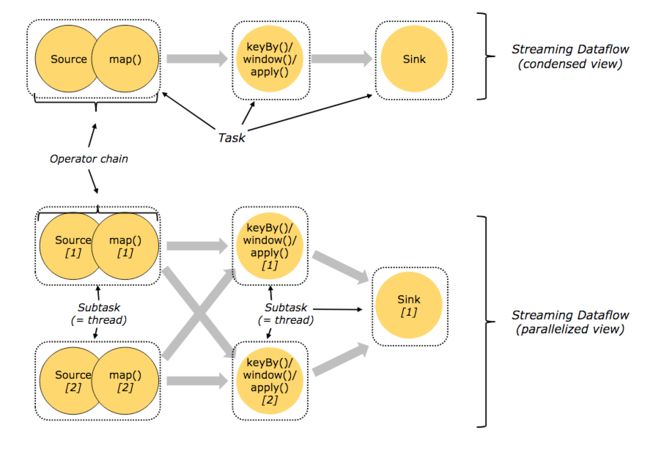
以Flink自带的WordCount为例,这个例子使用核心API DataStream API 编写,源代码可在github flink repo查看。下图为WordCount中的Operator分布和对应Task类型图解。

图中有两种Operator分布方式,sum()和Sink为Operator chain ,分布在同一SubTask内, Collection Source和FlatMap 分别分布在不同的SubTask中。 它们都运行在同一个TaskManager进程中。
本地线程数据传递
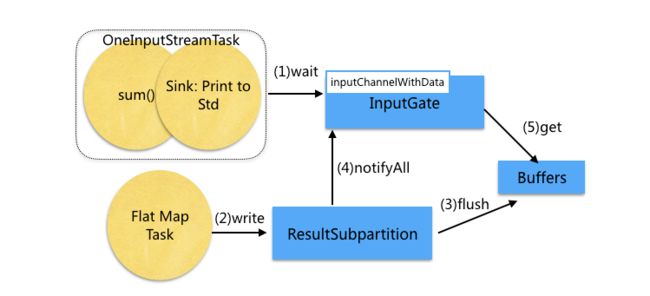
以Operator FlatMap 所在线程 与 下游 Operator sum() 所在线程间的通信为例。这两个task线程共享同一个Buffer pool,通过wait()/notifyAll来同步。 Buffer和Netty中的ByteBuf功能类似,可以看作是一块共享的内存。inputGate负责读取Buffer或Event,
- (1) 当没有Buffer可以消费时,Operator sum()所在的线程阻塞(通过inputGate中的inputChannelWithData.wait()方法阻塞)
- (2)(3) 当FlatMap所在线程写入结果数据到ResultSubPartition,并flush到buffer后
- (4) 会唤醒Operator sum()所在的线程(通过inputChannelWithData.notifyAll()方法唤醒)。
- (5) 线程被唤醒后会从Buffer中读取数据,经反序列化后,传递给Operator中的用户代码逻辑处理。交互过程如下图所示:
远程线程数据传递
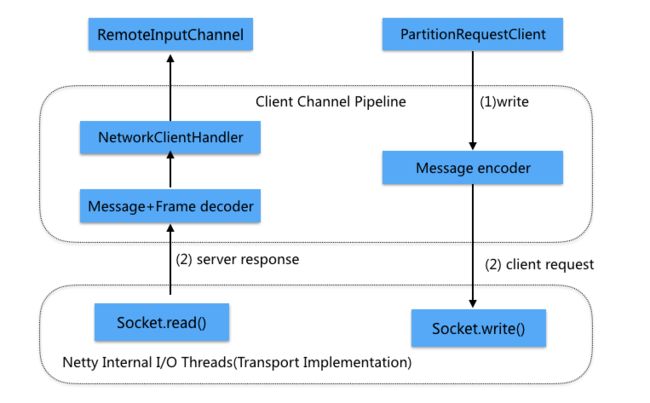
远程线程的Operator数据传递与本地线程类似。不同点在于,当没有Buffer可以消费时,会通过PartitionRequestClient向Operator FlatMap所在的进程发起RPC请求。远程的PartitionRequestServerHandler接收到请求后,读取ResultPartition管理的Buffer。并返回给Client。
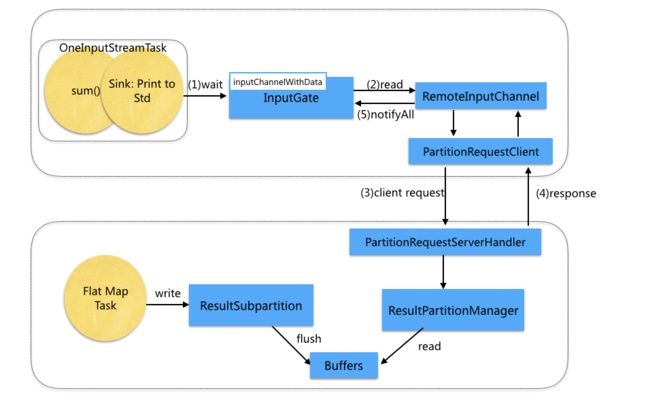
RPC通信基于Netty实现, 下图为Client端的RPC请求发送过程。PartitionRequestClient发出请求,交由Netty写到对应的socket。Netty读取Socket数据,解析Response后交由NetworkClientHandler处理。
同一线程的Operator数据传递
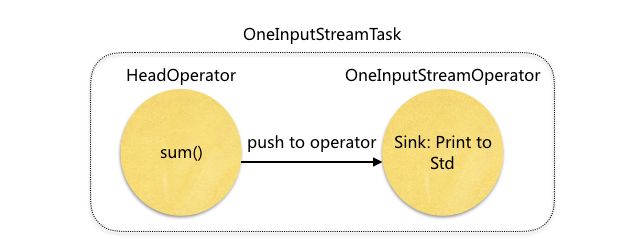
以Operator sum() 和Operator sink:Print to std 为例。 这两个Operator在同一个线程中运行,数据不需要经过序列化和写到多线程共享的buffer中, Operator sum()通过Collector发送数据后,直接调用Operator sink的processElement方法传递数据。
Buffer读写
由上述内容可知,在Flink中跨线程的数据传递都需要通过数据序列化 , flush Buffer , read Buffer ,数据反序列化这几个步骤。
下面同样以Operator FlatMap 所在线程 与 下游 Operator sum() 所在线程间的通信为例,讲解数据是如何从Buffer中被读取出来 ,传递给用户代码 ,以及用户代码逻辑生产的数据是如何写入Buffer的。
Buffer读取
Task线程启动后,通过while循环调用StreamInputProcessor.processInput()消费和发送数据,上文所指的“线程阻塞在inputGate中的inputChannelWithData.wait()”这段逻辑也是在StreamInputProcessor.processInput中发生的。Task启动到Buffer读取的调用栈如下图所示,图例只展示了核心内容,省略了一些逻辑。
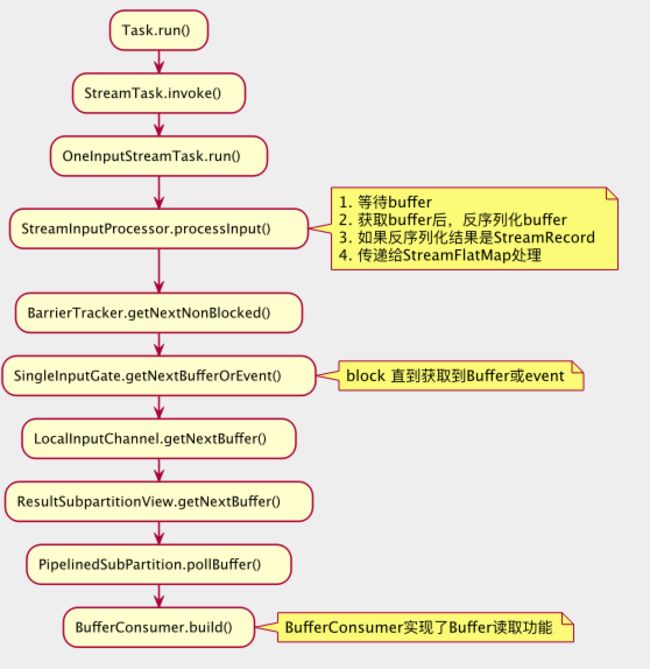
在调用栈的后部,ResultSubpartition的子类PipelinedSubPartition通过BufferConsumer来读取Buffer。
Buffer写入
在上图注释中,StreamInputProcessor调用CheckPointBarrierHandler.getNextNonBlocked阻塞直到获取到StreamRecord后,会调用StreamFlatMap.processElement(),内部调用FlatMapFunction.flatMap(T value, Collector
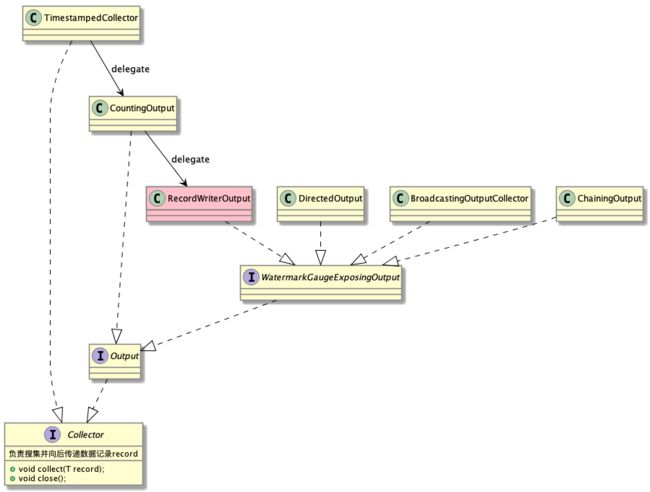
FlatMap和sum()是线程间通信,数据的发送最后会委托给实现了Collector接口的RecordWriterOutput。在RecordWriterOutput内部, 序列化逻辑由TypeSerializer实现,数据发送逻辑由StreamRecordWriter实现。而StreamRecordWriter的包含了ChannelSelector , ResultPartitionWriter这两个对象,其中ChannelSelector相当于NIO概念中的Selector,负责选择Channel,即选择通向数据发送的目标对象的Buffer通道。ResultPartitionWriter提供了两类方法,flush数据到buffer和添加buffer的消费者BufferConsumer, BufferConsumer用于读取ResultPartitionWriter写入的buffer,提供可消费的Buffer视图。ResultPartitionWriter的主要实现类是ResultPartition。
在WordCount这个例子中,ChannelSelector 使用的是KeyGroupStreamPartitioner,Operator FlatMap发送数据时,把word作为key,按照key hash取模的方式分发到下游的Operator sum() 。ChannelSelector还有很多种实现类,此处不展开描述
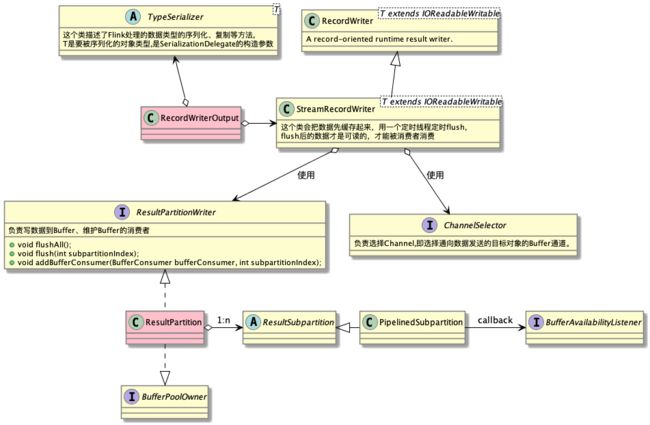
ResultPartition是一个复杂的类,它代表单个task生产的结果数据块 , 一个ResultPartition是一系列Buffer实例的集合。这些buffer会被分配到一个或多个ResultSubpartition实例中。即,一个ResultPartition可能被分成多个子集,然后根据数据分发类型交由consuming task消费。ResultSubpartition的主要实现类是PipelinedSubpartition , 该类提供了通知功能,当有新的数据写入buffer时,会回调BufferAvailabilityListener的notifyDataAvailable()方法。下面是BufferAvailabilityListener的几个实现类图示。

在此例中,上下游在同一个进程中,使用的是LocalInputChannel, LocalInputChannel实际调用SingleInputGate.notifyChannelNonEmpty(InputChannel channel) ,这个方法调用inputChannelsWithData.notifyAll , 唤醒阻塞在inputChannelsWithData对象实例的所有线程。上文提到的阻塞在CheckPointBarrierHandler.getNextNonBlocked()方法的线程也会被唤醒,返回数据。
内存管理
Flink底层做了精细化的内存管理。在Flink中MemorySegment代表一块内存,上文提到的Buffer是MemorySegment的封装。Flink的内存管理实现类图如下所示:
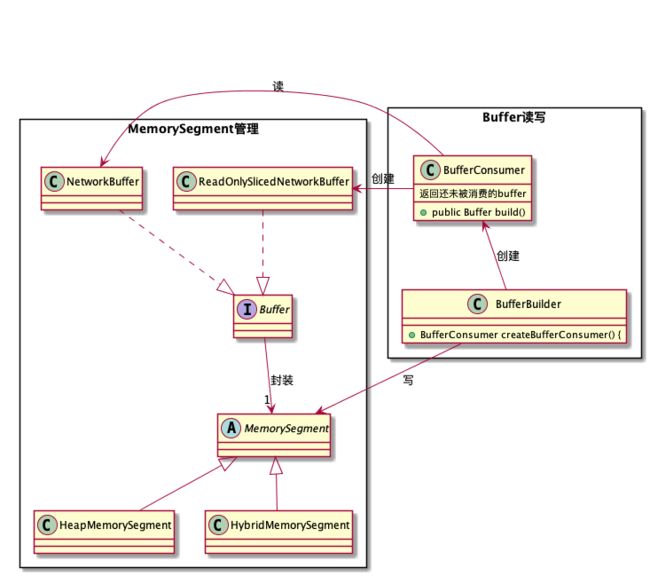
MemorySegment和Buffer
MemorySegment这个抽象类代表了一块由Flink管理的内存,可以是堆外内存或堆内内存。有两个主要的实现类,HeapMemorySegment 和 HybridMemorySegment。这两个类分别实现了堆内内存和堆外内存的读写。使用者可以透明地操作这些memory segment,不需要知道具体类型。这个类在概念上满足Java的java.nio.ByteBuffer的实现目的。专门增加这个类是为了:
- 增加binary的compare,swap,copy功能
- 增加通过绝对偏移来批量读取/写入,并且保证线程安全
- 用collapsed checks的方式来检查内存分配和访问的范围
- 提供明确的大端/小端访问函数,而不是在内部跟踪使用的byte顺序
关于效率: 为了更高的运行效率,使用这个类时需要保证只加载了一个子类(HeapMemorySegment或HybridMemorySegment),或者使用到的方法只有其中一个子类有实现。在这种情况下,所有在MemorySegment定义的抽象方法都只会被加载一次。
通过类继承分析(CHA, Class Hierarchy Analysis),JIT可以非常方便地识别到这个类,最后完美地内联(function inline,JIT使用的一种优化方法)这些方法。
Buffer是对MemorySegment的封装,增加了引用计数功能,当引用数为0时,表示buffer可以被回收。Buffer的功能类似于Netty的ByteBuf,比起ByteBuf,扩展了ByteBuf的一些方法和对ByteBuf原有的方法加了限制。Buffer用了两个不同的指针来进行读取和写入操作.例如,reader index和writer index把分配到的内存划分为三个区域
+-------------------+----------------+----------------+
| discardable bytes | readable bytes | writable bytes |
+-------------------+----------------+----------------+
| | | |
0 <= readerIndex <= writerIndex <= max capacity
非Netty应用类要么直接依赖于getMemorySegment(),要么依赖于ByteBuffer,ByteBuffer读写时不会主动修改指针,因此需要手动调用setReaderIndex(int)和setSize(int)来修改指针
MemorySegment和Buffer的读写
BufferBuilder和BufferConsumer分别负责MemorySegment数据的读写。
- BufferBuilder: 写数据到MemorySegment ,并创建负责消费这份数据的BufferConsumer
- BufferConsumer: BufferConsumer负责把NetworkBuffer(MemorySegment的封装)中的数据读出,组装成ReadOnlySlicedNetworkBuffer。NetworkBuffer和ReadOnlySlicedNetworkBuffer是Buffer接口的不同实现。ReadOnlySlicedNetworkBuffer可以看成BufferConsumer对NetworkBuffer分片后的结果。