1. 回顾Boosting提升算法
AdaBoost是典型的Boosting算法,属于Boosting家族的一员。在说AdaBoost之前,先说说Boosting提升算法。Boosting算法是将“弱学习算法“提升为“强学习算法”的过程,主要思想是“三个臭皮匠顶个诸葛亮”。一般来说,找到弱学习算法要相对容易一些,然后通过反复学习得到一系列弱分类器,组合这些弱分类器得到一个强分类器。Boosting算法要涉及到两个部分,加法模型和前向分步算法。
模型为加法模型就是我们最终的强分类器是若干个弱分类器加权平均而得到的(弱分类器线性相加而成)。
前向分步就是我们在训练的过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的。我们的算法是通过一轮轮的弱学习器学习,利用前一个强学习器的结果和当前弱学习器来更新当前的强学习器的模型。也就是说
第k-1轮的强学习器为:$f_{k-1}(x) = \sum\limits_{i=1}^{k-1}\alpha_iG_{i}(x)$
而第k轮的强学习器为:$f_{k}(x) = \sum\limits_{i=1}^{k}\alpha_iG_{i}(x)$
上两式一比较可以得到:$f_{k}(x) = f_{k-1}(x) + \alpha_kG_k(x)$
可见强学习器的确是通过前向分步学习算法一步步而得到的。
2. 集成学习之AdaBoost算法
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。这里的集合起来的策略是通过提高前一轮分类器分类错误的样本的权值,降低分类分类正确的样本权值,对于那些没有本分类正确的样本会得到后面分类器更多的关注。然后可以产生很多的弱分类器,通过多数加权投票组合这些弱分类器,加大误差率小的分类器,减少误差率大的分类器,使其在表决中起到较少的作用。
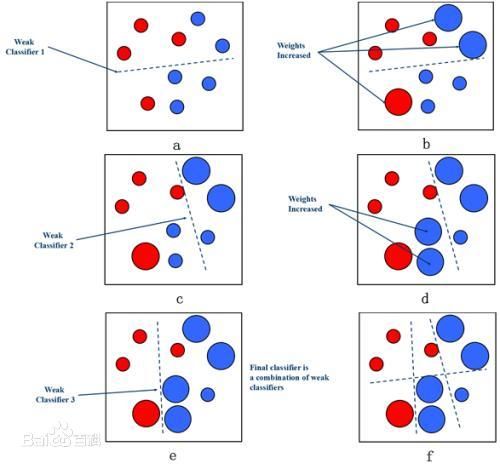
只要是boosting算法,都要解决以下这4个问题:(结合Adaboost算法原理理解怎么解决)
1)如何计算学习误差率e?
2)如何得到弱学习器权重系数αα?
3)如何更新样本权重D?
4) 使用何种结合策略?
3. Adaboost算法原理
假设一个二分类训练样本集:
$$T=\{(x_,y_1),(x_2,y_2), ...(x_m,y_m)\}$$
训练集的在第k个弱学习器的输出权重为:
$$D(k) = (w_{k1}, w_{k2}, ...w_{km}) ;\;\; w_{1i}=\frac{1}{m};\;\; i =1,2...m$$
第k个弱分类器$G_k(x)$在训练集上的加权误差率为:
$$e_k = P(G_k(x_i) \neq y_i) = \sum\limits_{i=1}^{m}w_{ki}I(G_k(x_i) \neq y_i)$$
第k个弱分类器$G_k(x)$的权重系数为:
$$\alpha_k = \frac{1}{2}log\frac{1-e_k}{e_k}$$
为什么这样计算弱学习器权重系数?从上式可以看出,如果分类误差率$e_k$越大,则对应的弱分类器权重系数$\alpha_k$越小。也就是说,误差率小的弱分类器权重系数越大。具体为什么采用这个权重系数公式,我们在讲Adaboost的损失函数优化时再讲。
更新样本权重D。假设第k个弱分类器的样本集权重系数为$D(k) = (w_{k1}, w_{k2}, ...w_{km})$,则对应的第k+1个弱分类器的样本集权重系数为:
$$w_{k+1,i} = \frac{w_{ki}}{Z_K}exp(-\alpha_ky_iG_k(x_i))$$
这里$Z_k$是规范化因子:
$$Z_k = \sum\limits_{i=1}^{m}w_{ki}exp(-\alpha_ky_iG_k(x_i))$$
从$w_{k+1,i}$ 计算公式可以看出,如果第i个样本分类错误,则$yiGk(xi)<0$,导致样本的权重在第k+1个弱分类器中增大,如果分类正确,则权重在第k+1个弱分类器中减少.具体为什么采用样本权重更新公式,我们在讲Adaboost的损失函数优化时再讲。
最后是集合策略。Adaboost分类采用的是加权表决法,构建基本分类器的线性组合:
$$f(x) = \sum\limits_{k=1}^{K}\alpha_kG_k(x)$$
最终的强分类器为:
$$G(x) = sign(f(x)) = sign(\sum\limits_{k=1}^{K}\alpha_kG_k(x))$$
4. AdaBoost分类问题的损失函数优化
分类问题的Adaboost的弱学习器权重系数公式和样本权重更新公式,可以从Adaboost的损失函数推导出来。Adaboost是模型为加法模型,学习算法为前向分步学习算法,损失函数为指数函数的分类问题。
首先AdaBoost算法的最终模型表达式为:
$$f(x) = \sum\limits_{m=1}^{M}\alpha_kG_k(x)$$
可以看到这是一个“加性模型(additive model)”。我们希望这个模型在训练集上的经验误差最小,即:
$$min\sum_{i=1}^{N}L(y_i,f(x)) < = > min\sum_{i=1}^{N}L(y_i,\sum\limits_{i=1}^{M}\alpha_mG_m(x))$$
通常这是一个复杂的优化问题。前向分步算法求解这一优化问题的思想就是: 因为最终模型是一个加性模型,如果能从前往后,每一步只学习一个基学习器$G_m(x)$及其权重$\alpha_m$, 不断迭代得到最终的模型,那么就可以简化问题复杂度。具体的,当我们经过$m-1$轮迭代得到了最优模型$f_{m-1}(x)$时,由前向分步算法可知:
$$f_m(x) = f_{m-1}(x) + \alpha_mG_m(x)$$
所以此轮优化目标就为:
$$min\sum_{i=1}^{N}L(y_i,f_{m-1}(x) + \alpha_mG_m(x))$$
求解上式即可得到第$m$个基分类器$G_m(x)$及其权重$\alpha_m$。
这样,前向分步算法就通过不断迭代求得了从$m=1$到$m=M$的所有基分类器及其权重,问题得到了解决。
上面主要介绍了前向分步算法逐一学习基学习器,这一过程也即AdaBoost算法逐一学习基学习器的过程。下面将证明前向分步算法的损失函数是指数损失函数(exponential loss function)时,AdaBoost学习的具体步骤。
首先指数损失函数即$L(y,f(x)) = exp(-yf(x))$,指数损失函数是分类任务原本0/1损失函数的一致(consistent)替代损失函数,由于指数损失函数有更好的数学性质,例如处处可微,所以我们用它替代0/1损失作为优化目标。
AdaBoost是采用指数损失,由此可以得到损失函数:
$$Loss=\sum_{i=1}^{N}exp(-y_if_m (x_i ))=\sum_{i=1}^{N}(-y_i(f_{m-1}(x_i )+\alpha_mG_m(x)))$$
因为$y_if_{m-1}(x)$与优化变量$\alpha$和$G$无关,所以令$w_{m,i}=exp(-y_if_m(x))$,这里$y_if_{m-1}(x)$是已知的,相当于可以作为常量移到前面去:
$$Loss=\sum_{i=1}^{N}w_{m,i} exp(-y_i\alpha_mG_m(x)))$$接下来就是求解上式的优化问题的最优解$\hat{\alpha}_m$和$\hat{G}_m(x)$。
首先我们求$\hat{G}_m(x)$,可以得到:
$$G_m(x) = \underset{G}{arg\;min\;}\sum\limits_{i=1}^{m}w_{mi}I(y_i \neq G_m(x_i))$$
上式将指数函数换成指示函数是因为前面说的指数损失函数和0/1损失函数是一致等价的。式子中所示的优化问题其实就是AdaBoost算法的基学习器的学习过程,即计算数据集的分类误差率,得到的$\hat{G}_m(x)$是使第$m$轮加权训练数据分类误差最小的基分类器。
然后求$\hat{\alpha}_m$,将$G_m(x)$带入损失函数,并对$\alpha$求导,使其等于0,即可得到:$$\alpha_m = \frac{1}{2}log\frac{1-e_m}{e_m}$$
其中,$e_m$即为我们前面的分类误差率:$$e_m = \frac{\sum\limits_{i=1}^{m}w_{mi}I(y_i \neq G(x_i))}{\sum\limits_{i=1}^{m}w_{mi}} = \sum\limits_{i=1}^{m}w_{mi}I(y_i \neq G(x_i))$$
最后看样本权重的更新:利用$f_{m}(x) = f_{m-1}(x) + \alpha_mG_m(x) $和$w_{mi} = exp(-y_if_{m-1}(x))$,即可得:$$w_{m+1,i} = w_{mi}exp[-y_i\alpha_mG_m(x)]$$
到此AdaBoost二分类算法推导结束。
5. Adaboost算法的正则化
为了防止Adaboost过拟合,我们通常也会加入正则化项,这个正则化项我们通常称为步长(learning rate)。定义为ν,对于前面的弱学习器的迭代:
$$f_{k}(x) = f_{k-1}(x) + \alpha_kG_k(x) $$
如果我们加上了正则化项,则有:
$$f_{k}(x) = f_{k-1}(x) + \nu\alpha_kG_k(x) $$
ν 的取值范围为0<ν≤1。对于同样的训练集学习效果,较小的ν意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
6. AdaBoost二元分类问题算法流程总结
输入:训练数据集$T=\{(x_,y_1),(x_2,y_2), ...(x_m,y_m)\}$,输出为{-1, +1},弱分类器算法, 弱分类器迭代次数K;
输出:为最终的强分类器$f(x)$。
1) 初始化样本集权重为:
$$D(1) = (w_{11}, w_{12}, ...w_{1m}) ;\;\; w_{1i}=\frac{1}{m};\;\; i =1,2...m$$
2) 对于k=1,2,...K:
a) 使用具有权重$D_k$的样本集来训练数据,得到弱分类器$G_k(x):\chi\to\{{-1,+1}\}$
b)计算$G_k(x)$的分类误差率:$$e_k = P(G_k(x_i) \neq y_i) = \sum\limits_{i=1}^{m}w_{ki}I(G_k(x_i) \neq y_i)$$
c) 计算弱分类器的系数:$$\alpha_k = \frac{1}{2}log\frac{1-e_k}{e_k}$$
d) 更新样本集的权重分布:$$w_{k+1,i} = \frac{w_{ki}}{Z_K}exp(-\alpha_ky_iG_k(x_i)) \;\; i =1,2,...m$$
这里$Z_k$是规范化因子:$$Z_k = \sum\limits_{i=1}^{m}w_{ki}exp(-\alpha_ky_iG_k(x_i))$$
3) 构建最终分类器为:$$f(x) = sign(\sum\limits_{k=1}^{K}\alpha_kG_k(x))$$
对于Adaboost多元分类算法,其实原理和二元分类类似,最主要区别在弱分类器的系数上。比如Adaboost SAMME算法,它的弱分类器的系数:$$\alpha_k = \frac{1}{2}log\frac{1-e_k}{e_k} + log(R-1)$$
其中R为类别数。从上式可以看出,如果是二元分类,R=2,则上式和我们的二元分类算法中的弱分类器的系数一致。
7. 总结
到这里Adaboost分类问题差不多结束了,前面有一个没有提到,就是弱学习器的类型。理论上任何学习器都可以用于Adaboost,但一般来说,使用最广泛的Adaboost弱学习器是决策树和神经网络。对于决策树,Adaboost分类用了CART分类树,而Adaboost回归用了CART回归树。
Adaboost的优点有:
1)Adaboost作为分类器时,分类精度很高;
2)在Adaboost的框架下,可以使用各种回归分类模型来构建弱学习器,非常灵活;
3)作为简单的二元分类器时,构造简单,容易实施,结果可理解;
4)不容易发生过拟合。
Adaboost的缺点有:
1)对异常样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性。
【补充】:文章开头有提到Adaboost既可以用作分类,也可以用作回归,本文主要针对Adaboost二分类问题做了详细介绍,关于Adaboost回归问题,可以参考https://www.cnblogs.com/pinard/p/6133937.html这篇博客,解释的很详细。
参考文章:
https://zhuanlan.zhihu.com/p/59121403
https://www.cnblogs.com/pinard/p/6133937.html
https://www.cnblogs.com/ScorpioLu/p/8295990.html