本文主要翻译至链接且不局限于该文内容,也加入了笔者实践内容,翻译水平有限,欢迎指正,转载请注明出处。由于篇幅较长,四、编程指引-Scala篇拆成了上下两篇,上一篇请参考《Spark指南》四、编程指引-Scala篇(上)。
<接上文>
使用key-value键值对
虽然Spark在RDDs上的大部门操作支持任意类型的对象,但是一些操作只能在键值对上使用。最常见的是分布式“shuffle”操作,例如根据key对元素进行分组或聚集操作。在Scala中,这些操作可以在包含Tuple2对象(语言中的内置tuple,例如(a,b))的RDDs上使用。参考PairRDDFunctions,你可以看到元组RDD上支持的操作。下面是一个使用元组RDD的例子:
val lines = sc.textFile("data.txt")
val pairs = lines.map(s => (s, 1))
val counts = pairs.reduceByKey((a, b) => a + b)
这个例子在map中传递的函数生成了一个元组RDD,每个元组的键是该行的文本,值初始化为1,然后使用了reduceByKey操作对元组进行规约操作,把相同key的值进行相加,最终得到的是每个文本键的计数。
我们还可以使用counts.sortByKey()操作对得到的键值对进行字母序排列,然后调用counts.collect()将结果以对象数组形式都收集到驱动程序中。
注意:当使用普通的对象作为key时,你应该保证该对象类的equals()方法有一个对应的hashCode()方法。更多的信息请参考Object.hashCode() 文档
Transformations操作
下表列举了Spark支持的一些常用的transformations操作,更详细的操作请参考RDD的API文档(Scala, Java,Python,R)和元组RDD的API文档(Scala,Java)。
| Transformation | 含义 |
|---|---|
| map(func) | 将数据源的每个元素都传给一个用户定义的函数func,然后返回一个新的数据集 |
| filter(func) | 将数据源的每个元素都传给一个用户定义的过滤函数func,如果func返回true,则收集这些元素,最终以一个新的数据集返回 |
| flatMap(func) | 和map类似,但是每一个元素经过func处理后可以返回0个或多个输出元素,即func必须返回一个序列,而不是单个元素 |
| mapPartitions(func) | 和map类似,但是会在单独的RDD分区(块)上运行,因此当在类型T的RDD上运行时,func必须是Iterator |
| mapPartitionsWithIndex(func) | 和mapPartitions类型,区别是会给func函数提供一个整数值以表示数据所在的分区,因此当在类型T的RDD上运行时,func必须是 (Int, Iterator |
| sample(withReplacement, fraction, seed) | 使用给定的随机数发生器种子对一部分数据(fraction)进行抽样,可以进行替换(withReplacement为boolean值) |
| union(otherDataset) | 将源数据集与参数数据集进行合并,得到一个新的数据集 |
| intersection(otherDataset) | 返回源数据集与参数数据集的交集数据集 |
| distinct([numTasks])) | 过滤掉源数据集中的重复元素,返回一个set集合 |
| groupByKey([numTasks]) | 当在(K,V)键值对数据集上调用本函数时,返回一个新的数据集,值为(K,Iterable |
| reduceByKey(func, [numTasks]) | 当在(K,V)数据集上调用本函数时,返回一个新的(K,V)数据集,其中,每个key对应的所有值都会传递给给定的func函数func,操作类型为(V,V) => V。可以在第二个参数中传递numTasks来设置并行度。 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 当在(K,V)数据集上调用本函数时,返回一个新的(K,U)数据集,其中,seqOp函数用于聚集一个分区内的结果(类型为(U,T) => U),combOp函数用于聚集多个分区的结果(类型为(U,U) => U),zeroValue作为seqOp和combOp操作的初始值,典型情况下是一个自然元素,例如,如果是列表拼接操作,初始值可以指定为Nil,如果是求和操作,初始值可以指定为0。 聚合结果的值类型允许与输入值类型不同。 reduce任务的数量可以通过可选的第三个参数来配置。 |
| sortByKey([ascending], [numTasks]) | 当在(K,V)数据集上调用本函数时,返回一个以K值排序的(K,V)数据集,其中,K必须实现Ordered接口,升序或降序可以在第一个参数指定(true为升序),第二个参数指定并行度。 |
| join(otherDataset, [numTasks]) | 将源数据集(K,V)与目标数据集(K,W)进行连接操作,返回一个新的数据集(K,(V,W)),其中,K为所有的键,(V,W)为所有可能的组合。如果需要计算外部连接,可以使用leftOuterJoin、rightOuterJoin或fullOuterJoin方法,其含义与数据库表的连接类似。 |
| cogroup(otherDataset, [numTasks]) | 将源数据集(K,V)与目标数据集(K,W)进行此操作后,返回一个新的(K,(Iterable |
| cartesian(otherDataset) | 当在类型T的源数据集和类型U的参数数据集上进行此操作后(笛卡尔积),返回一个元组数据集,元组是所有可能的(T,U)对 |
| pipe(command, [envVars]) | 构建一个管道,对RDD的每个分区执行一个shell脚本(例如Perl、bash),RDD的每个元素作为该脚本进程的输入,该脚本的输出则生成一个新的RDD,RDD的一个元素对应输出结果的一行字符串 |
| coalesce(numPartitions) | 减少RDD的分区数到指定的numPartitions,在过滤完一个大规模数据集后执行操作时,这个方法可以更高效 |
| repartition(numPartitions) | 随机打乱RDD里的数据集,然后重新创建指定数量的分区,使分区内的元素尽量平衡。该操作通常会在整个网络内重组数据 |
| repartitionAndSortWithinPartitions(partitioner) | 随机打乱RDD里的数据集,然后重新创建指定数量的分区,对分区结果中的数据,根据他们的key值进行冲排序。该操作比先调用repartition再调用排序操作更高效,因为排序操作同时会在每个shuffle机器上执行 |
Actions操作
下表列举了Spark支持的一些常用的actions操作,更详细的操作请参考RDD的API文档(Scala, Java, Python, R),和元组RDD文档 (Scala, Java)。
| Action | 含义 |
|---|---|
| reduce(func) | 使用函数func聚集数据集中的所有元素,函数类型为((U,U) => U),该函数避暑是可交换和关联的,才能正确的进行并行计算。 |
| collect() | 将数据集的所有元素以数组的形式返回给驱动程序。该操作在一些过滤操作返回操作数据集的子集时非常有用。 |
| count() | 统计数据集的元素个数 |
| first() | 返回数据集的第一个元素,等同于take(1) |
| take(n) | 返回数据集的前n个元素 |
| takeSample(withReplacement, num, [seed]) | 随机抽样num个元素,withReplacement表示有无放回抽样,第三个参数可选,可以提供一个随机数种子发生器 |
| takeOrdered(n, [ordering]) | 返回数据集中排过序的前n个元素 |
| saveAsTextFile(path) | 将数据集中的元素以文本文件形式写到文件系统(本地、HDFS或其他Hadoop支持的文件系统)的path目录下,Spark会调用每个元素的toString方法来将每个元素转成一行字符串 |
| saveAsSequenceFile(path) (Java and Scala) | 将数据集中的元素以Hadoop序列化文件形式写到文件系统(本地、HDFS或其他Hadoop支持的文件系统)的path目录下,这个操作可以在实现Hadoop Writable接口的键值对RDD上使用。在Scala中,这个操作也支持在可以隐式转换为Writable对象的类型上使用,例如Int、Double、String等基础类型就支持隐式转换。 |
| saveAsObjectFile(path) (Java and Scala) | 将数据集中的元素以Java序列化形式写到文件系统(本地、HDFS或其他Hadoop支持的文件系统)的path目录下,这个文件随后可以通过调用SparkContext.objectFile()方法读取到内存中。 |
| countByKey() | 该操作只能在元组RDD上使用,它返回一个(K,Int)形式的hashmap,统计了每个Key对应的值的计数 |
| foreach(func) | 对数据集中的每个元素执行func操作。注意,更改foreach作用域之外的非Accumulators变量,可能会有预期之外的行为,详情请参考《Spark指南》四、编程指引-Scala篇(上) 一文中的“理解闭包” |
Spark RDD API也提供了一些actions的异步版本,例如foreach对应的异步版本为foreachAsync,该操作直接返回一个FutureAction对象给调用者,而不是阻塞在调用过程中。
Shuffle操作
Spark中执行的部分操作可能会触发shuffle事件,shuffle是Spark中一种重新分发数据的机制,不同分区内的数据因此会被重组。由于数据会在不同的分区和机器之间拷贝,shuffle是一个很复杂和代价很高的操作。
背景
以reduceByKey(func)操作为例,该操作的作用是扫描数据集中的所有(K,V)元组,对同一个Key下的所有values执行func操作,最终返回一个新的RDD,值为(K,func(V))。实际运行时,源数据集被拆分在不同机器的不同分区上,因此同一个key的所有values无法保证都在同一个分区或同一台机器,于是必须进行一些重组操作才能计算最终的结果。
在Spark中,数据通常都不会自动跨分区分布到特定操作所需要的位置上,在计算过程中,一个task只会操作一个单独的分区,因此为了重组所有的数据以保证reduceByKey task能够执行,Spark需要进行一个all-to-all操作,即,它必须在所有分区上对所有的keys进行重新分组,把一个key对应的所有values都跨分区读取到一起,以计算该key最终的结果——这个过程就是shuffle。
如果希望在shuffle操作之后,让数据有序,可以执行如下操作:
- 使用mapPartitions对分区进行排序
- 使用repartitionAndSortWithinPartitions在重新分区的同时进行排序
- 使用sortBy得到一个全局有序的RDD
会触发shuffle的操作包括repartition系列操作,例如repartition、coalesce,ByKey系列操作,例如groupByKey、reduceByKey,以及join系列操作,例如cogroup、join。
性能
Shuffle操作是一个代价很大的操作,因为它会涉及磁盘I/O、数据系列化甚至是网络I/O。Spark会生成一些列的tasks,包括:map tasks用于组织数据,reduce tasks用于聚集数据(这其中的map和reduce并不等价于Spark的map和reduce操作)。
在内部,map task产生的数据会一直保存在内存中(直到内存满了),然后他们基于目标分区进行重排序并写入到一个单独的文件中。在reduce一端,tasks直接读取相关的已排序过的数据块。
某些shuffle操作会消耗大量的堆内存,因为在传输数据前后,他们需要使用内存中的数据结构来表示。例如,reduceByKey和aggregateByKey操作会在map端创建这些数据结构,其他'ByKey操作会在reduce端生成这些数据结构。当内存中存放不下时,Spark会将这些数据暂存到磁盘,因此会增加额外的磁盘I/O开销,以及增加JVM的内存回收。
Shuffle操作也会在磁盘上生成大量的临时文件。从Spark 1.3开始,这些文件会被一直保留在磁盘上,直到相应的RDDs不再被使用,然后被当成垃圾回收。这样做的原因是如果进行相同的操作,中间数据可以被重用,而不必重新创建。如果应用程序一直保持着对RDDs的引用,或者GC操作不频繁,那么垃圾回收可能会在很长的一段时间以后才会进行,于是,一些长时间运行的Spark作业可能会占用大量的磁盘空间。临时的存储目录可以在SPark context中配置spark.local.dir属性。Shuffle操作支持很多配置参数来调整功能,你可以参考Spark Configuration Guide一文中的“Shuffle Behavior”小节。
RDD持久化
Spark中最重要的功能之一是在operations操作执行中在内存内持久化(或缓存)数据集。 当持久化RDD时,每个节点都存储它在自己内存中计算的数据分区,并在该数据集(或从其派生的数据集)上的其他操作中重新使用它们。 这通常能为接下来的操作能够提升效率(通常超过10倍)。 缓存则是迭代算法和快速交互使用的关键工具。
您可以使用persist()或cache()方法对RDD进行持久化。 第一次在action中计算它后,它将被保存在节点上的内存中。 Spark的缓存是容错的 - 如果RDD的任何分区丢失,它将根据最初创建时的变换自动重新计算。
此外,每一个持久化的RDD可以指定不同的存储级别,例如,你可以将数据存储在磁盘中,将它以java序列化对象的形式存储在内存中,或者在不同的节点之间进行复制拷贝。存储级别可以通过给persist()方法传递一个StorageLevel对象(Scala,Java, Python) 来实现。cache()方法等同于使用StorageLevel.MEMORY_ONLY级别的持久化(即,在内存中存储反序列化的对象),完整的存储级别包括如下:
| 存储级别 | 含义 |
|---|---|
| MEMORY_ONLY | 将RDD在JVM中存储为反序列化的java对象。如果存储超出了限制,某些分区将不会被缓存,而是在他们需要被使用时重新计算。该级别是默认的存储级别 |
| MEMORY_AND_DISK | 将RDD在JVM中存储为反序列化的java对象。如果存储超出了限制,某些分区将被存储到磁盘上,需要使用的时候再从磁盘中读取 |
| MEMORY_ONLY_SER (Java and Scala) | 将RDD在JVM中存储为序列化的java对象(每个分区对应一个字节数组),这种方式比反序列化方式具有更高的空间利用率。如果内存中放不下,数据不会被缓存,而是在使用时重新计算。 |
| MEMORY_AND_DISK_SER (Java and Scala) | 与MEMORY_ONLY_SER类似,不同的是内存中放不下时,数据会被存储到磁盘上。 |
| DISK_ONLY | 只在磁盘中存储RDD分区 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等. | 与前缀的级别类似,但是数据会在两个集群节点之间进行拷贝 |
| OFF_HEAP (实验阶段) | 与MEMORY_ONLY_SER相似,但是数据被存储在堆外内存中,该特性需要事先开启堆外内存功能,参考off-heap memory |
注意,在python中,存储的数据都是以Pickle进行序列化,因此一些序列化级别对python版无效,可用的存储级别包括:MEMORY_ONLY, MEMORY_ONLY_2, MEMORY_AND_DISK, MEMORY_AND_DISK_2, DISK_ONLY, and DISK_ONLY_2。
如果选择存储级别
Spark的存储级别意味着需要在内存使用率和CPU效率之间进行不同的权衡。我们建议按照如下过程进行选择:
- 如果你的RDDs足够存储在内存中(默认使用MEMORY_ONLY),那么尽量使用这种级别,它提供了最高效的运行方式。
- 如果不行,优先使用MEMORY_ONLY_SER然后选择一个高效的序列化库,这样能更好的利用内存空间,也保证足够的访问速率。
- 尽量不要把数据存储到磁盘上,除非重新计算数据代价很大,或者需要过滤一个非常大规模的数据。否则,重新计算可能都会比从内存中读取来得快。
- 如果你希望提供快速的错误恢复能力,可以使用可拷贝的存储级别,例如,为一个web应用程序提供服务时可能会用到。所有的存储级别在分区数据丢失时,都会通过重新计算来容错,但是数据具有拷贝的话,Spark就能够继续运行tasks而不是等待他们完成重新计算。
移除数据
Spark会自动监控缓存的使用,然后使用LRU(最近最少使用)算法丢弃老的数据分区。如果你想手动从缓存中移除数据,调用RDD.unpersist()方法。
共享变量
通常,当传递给Spark操作(例如map操作、reduce操作等)的函数在远程节点上执行时,该函数所使用的变量都是独立拷贝的。因此,这些变量的后续修改都不会反馈到驱动程序上,跨任务共享读写变量将是很低效的。Spark提供了两种共享变量类型来支持这种需求:广播变量(broadcast variables)和累加器(Accumulators)。
广播变量(broadcast variables)
广播变量允许开发者在每台机器上缓存一个只读的变量,而不是重复的在tasks之间进行实时拷贝。例如,它允许以一种更高效方式给每个节点拷贝一个数据集的副本。Spark本身会尝试使用高效的广播算法来分发广播变量,以降低通信成本。
Spark的actions操作通常由一系列由分布式的“shuffle”操作分割开的步骤组成,Spark会自动广播每一个步骤所需要使用的数据。以这种方式广播的数据会以序列化的形式缓存,然后再每个task执行之前反序列化。因此,显示地创建广播变量只有在如下情形才有用:1)跨越多个步骤的tasks需要使用相同的数据;2)以反序列化形式缓存数据很重要。
调用SparkContext.broadcast(v)可以创建一个以v的内容进行包装的广播变量,它的值可以通过value方法进行引用,代码例如:
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
创建完一个广播变量之后,你应该尽量使用该广播变量而不是直接使用变量v,以防在多个节点之间多次拷贝。此外,对象v不应该在被广播之后进行修改,确保所有节点获得的广播变量的值都是相同的(例如,如果变量以后被传输到新节点,应该还能保证是相同的值)。
累加器(Accumulators)
累加器是这样一类变量,它们在关联和交换操作中仅支持“累加”操作,因此支持有效的并行操作。 它们可以用于实现计数器(如在MapReduce中)或求和。 Spark本身支持数值类型的累加器,但是你可以添加对新类型的支持。
下图例举了一个名为counter的累加器,累加器会被展示在web UI上,并且每一个有修改操作的步骤都会展示出来,(Tasks表)。
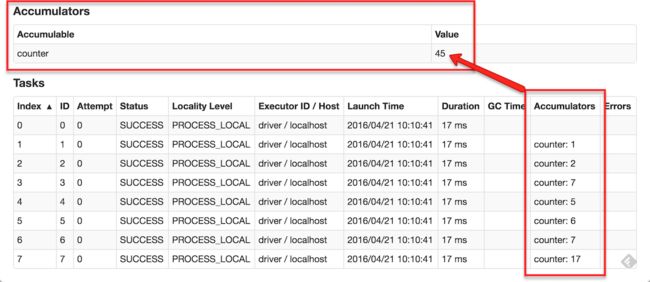
跟踪UI中的累加器对于理解每个运行步骤的进度又很大帮助。
在Scala中,可以使用SparkContext.longAccumulator()或SparkContext.doubleAccumulator()来创建一个long型或double型的累加器,Tasks在执行时,可以调用累加器的add方法来增加累加器的数值。然而,Tasks无法读取累加器的值,只有驱动程序才能使用value方法获取它们的取值。
例如,下面的例子展示了用一个累加器来累加一个数组的和:
scala> val accum = sc.longAccumulator("My Accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(My Accumulator), value: 0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Long = 10
这段代码使用了内置支持的Long类型累加器,开发者也可以通过创建AccumulatorV2的子类来实现自定义类型的累加器。AccumulatorV2抽象类有若干个方法,其中必须实现的包括:1)reset方法,用于将累加器清零;2)add方法,用于累加新的值到累加器上;3)merge方法,用于合并相同类型的累加器。其他必须重写的方法请参考API documentation。例如下面的例子中,我们假设MyVector类用于表示数学上的向量:
class VectorAccumulatorV2 extends AccumulatorV2[MyVector, MyVector] {
private val myVector: MyVector = MyVector.createZeroVector
def reset(): Unit = {
myVector.reset()
}
def add(v: MyVector): Unit = {
myVector.add(v)
}
...
}
// Then, create an Accumulator of this type:
val myVectorAcc = new VectorAccumulatorV2
// Then, register it into spark context:
sc.register(myVectorAcc, "MyVectorAcc1")
可以注意到,当开发者自定义累加器时,累加的结果类型允许和累加的参数不一致。
对于仅在actions内部进行的累加器更新,Spark保证每个task的更新到累加器上的操作只会进行一次,也就是说,如果重启tasks,累加器的值不会重复更新。但是在transformations操作中,开发者需要注意到每个task的更新操作可能会被执行不止一次,如果任务被重新执行的话。
注意,累加器并不会改变Spark的lazy评估模型。即,如果它们是在一个RDD操作内更新数值,则只有当该RDD开始计算时才会更新累加器的数值。因此,在对RDD应用一些lazy transformation时(例如map操作),累加器操作并不保证实时更新。例如,下面的代码运行结果仍然是0:
val accum = sc.longAccumulator
data.map { x => accum.add(x); x }
// Here, accum is still 0 because no actions have caused the map operation to be computed.
部署运行
提交应用程序
在《Spark指南》三、 提交应用程序这章中,我们描述了如何提交应用程序到集群中运行。简洁的说,我们需要把应用程序打包(对于Java/Scala,打成JAR包,对于Python,对应的是一些.py或.zip文件),然后调用bin/spark-submit来提交应用程序到集群中。
在Java/Scala中启动
org.apache.spark.launcher这个包提供了一些建议的Java API,可以以子进程的形式启动Spark作业。
单元测试
Spark可以很友好的使用各种单元测试框架进行单元测试,你需要做的只要创建一个SparkContext,然后将master URL设置为local就可以执行测试你的程序,当代码逻辑执行完毕,你需要调用SparkContext.stop()来关闭进程。尽量在创建新的context之前,使用finally块或测试框架的tearDown方法来关闭上下文,因为Spark不支持在单进程中同时存在两个上下文。
下一步
学完本章,你可以到Spark官网上看看一些Spark示例代码,或者,Spark的安装包中也有一个examples目录(Scala,Java, Python, R),你可以使用bin/run-example脚本执行这些示例程序,例如:
./bin/run-example SparkPi
对于,Python或R语言的范例,你需要使用spark-submit来提交程序:
./bin/spark-submit examples/src/main/python/pi.py
./bin/spark-submit examples/src/main/r/dataframe.R
如果需要调优,你可以参考configuration 和 tuning 这两篇文档。他们提出了一些最佳实践的建议,用以保证你的数据在内存中以一种高效的形式进行存储。
如果需要部署方面的帮助,你可以查阅cluster mode overview这篇文章,它描述了分布式操作中相关的一些组件,以及Spark所支持的集群管理器。
最后,你可以查阅Scala, Java, Python and R这些文档来了解完整的API。
相关的文章
- 《Spark指南》一、快速开始
- 《Spark指南》二、 独立模式
- 《Spark指南》三、 提交应用程序
- 《Spark指南》四、编程指引-Scala篇(上)
- 《Spark指南》四、编程指引-Scala篇(下)