cookie & session
由于http协议的无记忆性,用户(http浏览器)访问某个服务器后,等下次再次访问时,服务器是不会记住用户的信息的。
这些信息包含用户身份验证、登录状态或者相关设置,当用户再次访问相同服务器时,需要重新设置相关信息,进行相关身份验证。
为了弥补这点,就采用了cookie和session的一种补充协议。
cookie:指某些网站为了辨别用户身份、确认登录状态等,进行 session 跟踪而储存在用户本地终端上的数据(通常经过加密) 。
cookie就是存放在本地的一段信息,session是保存在服务器上的与cookie对应的另一半信息。也就是说,当服务器验证用户身份时,不仅要验证本地cookie信息,还要验证与之对应的session的信息,如果相匹配,则验证成功,可以进行上一次的访问。
-
cookie和session的区别:
- 存放位置不同:cookie存放在本地,session存放在服务器端的内存或数据库中。
- cookie不安全,因此只存放不重要的信息,重要的信息存放在session中。
- session会保存在服务器上一段时间,时间一到就过期。也就是说,cookie可以存放很久,但只要session过期,那么cookie与session信息不对应,即使访问cookie也无法打开用户的信息,无法验证通过。
- 单个cookie保存数据不超过4k,很多浏览器规定cookie的数量不超过20个。
-
cookie和session的验证:
- 当用户访问某个网站时,http浏览器会先查找本地是否有关于此网站的cookie信息,如果有,浏览器会发送消息给服务器,服务器就会验证与之对应的session是否存在,如果存在,则会无需用户验证即可登录且还保存着上次登录时的状态和相关设置信息。如果没有,或者session失效,验证失败,需要用户重新手动验证(重新输入密码,重新设置相关信息)等操作,然后才能登录并访问服务器。
验证cookie的使用
为了验证cookie的作用,在这里使用两个例子:一个是不使用cookie,一个是使用cookie。
手动添加cookie
使用手动的方式来添加cookie。第一次验证不需要cookie,第二次手动添加cookie,观察两者的区别。
不使用cookie
不使用cookie信息,登录一个网站,然后将相应的url复制下来,换到另一个浏览器,观察是否还可以访问。
在这里,我用百度帐号举例,下面的图是我登录百度后个人中心的简单信息:
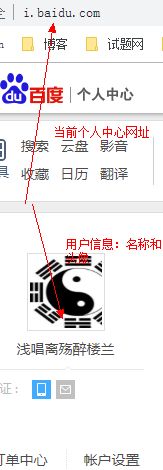
可见,当我登录百度个人中心后,里面显示了我的百度名称和头像等信息。而且,网址i.baidu.com正是我百度个人中心的网址,如果使用这个网址在当前浏览器上,那么无需登录就可以访问到自己的个人中心。
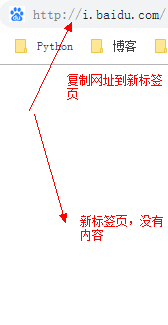
当页面跳转后,又访问到我的个人中心了,这是因为当前浏览器已经将我先前的登录信息“记”下来了,当复制个人中心网址到新标签页时,浏览器会检查是否有相关的cookie,如果有则向服务器发送消息验证相应的session,结果当然也有,所以无需我再次手动登录,浏览器自动登录个人中心成功。
那么此时,为了验证cookie,我将刚才的网址复制在另一个浏览器里面(这里举例IE浏览器)试一试。
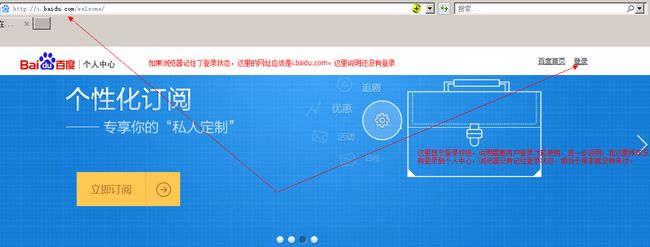
从图中可以看出,IE浏览器没有我登录百度的记录,所以提示需要先登录。说明IE浏览器没有记录cookie,那么就没有我的登录状态信息。
重新回到先的浏览器(这里用的谷歌),打开F12,查看当前登录的cookie信息:
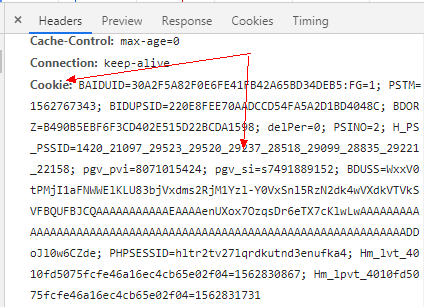
可以看到cookie是一长串的字符。
举例:
书写爬虫代码,模拟浏览器来访问个人中心,这里先不使用cookie,试一试爬虫当前个人中心,为了能更直观地观察,可以将下载下来的页面存入到一个html文件中,然后打开这个文件,查看是否有个人中心的信息。
from urllib import request
if __name__ == '__main__':
# 输入个人中心的url
url = "http://i.baidu.com/"
# 然后打开这个页面
rep = request.urlopen(url)
# 读取并转码
html = rep.read().decode()
# 将这个页面写入到一个1.html文件中
with open("1.html", "w", encoding = "utf - 8") as f:
f.write(html)
可以在文件夹中看到新生成的名为1.html的文档文件,打开这个页面,发现它与在IE浏览器的页面相似,并没有记录登录的信息,说明没有登录:
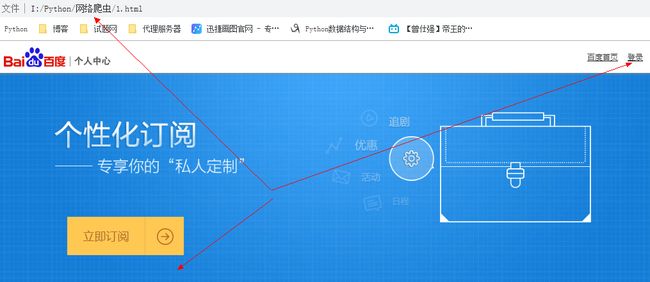
可见,就算是使用当前的浏览器,只要没有cookie信息,那么就不会记录登录的信息,需要重新验证登录。
使用cookie登录
之前我没有使用cookie,服务器并没有记住登录的相关信息。
此时,我手动添加cookie来验证服务器是否能根据cookie记住我的登录信息。
我们知道,cookie是在http头部信息中,因此需要用到headers,并将个人中心页面的cookie复制给headers中的cookie属性。这里就需要用到request.Request()来创建Request实例。
from urllib import request
if __name__ == '__main__':
# 还是先前的url
url = "http://i.baidu.com/"
# 构造headers头部信息,以字典的形式构造
# 复制个人中心的cookie信息
headers = {
"cookie" : "BAIDUID=30A2F5A82F0E6FE41FB42A65BD34DEB5:FG=1; PSTM=1562767343; BIDUPSID=220E8FEE70AADCCD54FA5A2D1BD4048C; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; delPer=0; PSINO=2; H_PS_PSSID=1420_21097_29523_29520_29237_28518_29099_28835_29221_22158; pgv_pvi=8071015424; pgv_si=s7491889152; BDUSS=WxxV0tPMjI1aFNWWElKLU83bjVxdms2RjM1Yzl-Y0VxSnl5RzN2dk4wVXdkVTVkSVFBQUFBJCQAAAAAAAAAAAEAAAAenUXox7OzqsDr6eTX7cKlwLwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADDoJl0w6CZde; PHPSESSID=hltr2tv27lqrdkutnd3enufka4; Hm_lvt_4010fd5075fcfe46a16ec4cb65e02f04=1562830867; Hm_lpvt_4010fd5075fcfe46a16ec4cb65e02f04=1562831731"
}
# 创建Request实例
rsp = request.Request(url, headers = headers)
# 打开这个实例
rep = request.urlopen(rsp)
# 读取并转码
html = rep.read().decode()
# 将这个页面存入到2.html文件中
with open("2.html", "w", encoding = "utf - 8") as f:
f.write(html)
运行程序,发现文件夹中多了一个名为2.html的文件。我首先用当前浏览器(谷歌)打开这个html文件。
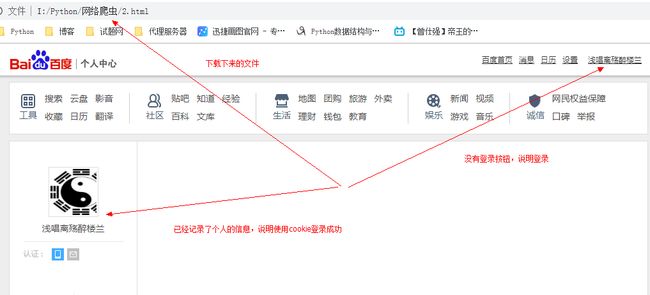
发现该页面正是我登录进百度个人中心的页面,说明手动添加cookie已经成功。
当然,为了更加准确地证实是cookie起作用,我又使用IE浏览器打开这个文档。
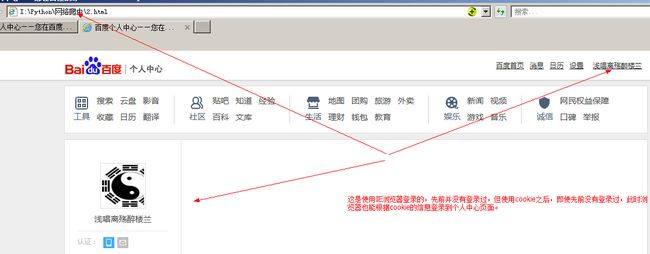
先前我根本就没有用IE登录过百度,此时打开这个文件却已在个人中心,说明IE已经检查到cookie并向服务器确认session的存在,发现确实在这个信息存在,于是也登录成功。
通过以上两个例子可以知道,cookie和session可以给用户带来许多的方便,它不用使用户每次访问相同网站时都需要输入验证信息,大大提高访问效率。
自动获取cookie
- http模块包含一些关于cookie的模块,通过这些模块可以自动使用cookie
- CookieJar
- 管理存储cookie,向传出的http请求添加cookie
- cookie存储在内存中,CookieJar实例回收后cookie消失
- FileCookieJar(fileName, delayLoad = Noe, policy = None)
- 使用文件管理cookie
- fileName为保存cookie的文件
- MozillaCookieJar(fileName, delayLoad = Noe, policy = None)
- 创建与mozilla浏览器cookie.txt兼容的FileCookieJar实例
- LwpCookieJar(fileName, delayLoad = Noe, policy = None)
- 三个模块之间的关系:Cookiejar-->FileCookieJar-->MozillaCookiejar & LwpCookiejar
- 经常使用是模块为CookieJar和FileCookieJar
- 使用cookieJar的流程:
- 打开登录页面后自动通过用户名密码登录
- 自动提取反馈回来的cookie
- 利用提取的cookie登录页面
- CookieJar
这里我用人人网来举例。我先不在人人页面登录,而是通过爬虫代码登录后让程序自动提取登录的cookie,然后使用cookie登录进人人网的个人中心。
首先导入http包中的cookiejar模块,然后分别创建cookiejar实例、cookie管理器、http请求管理器、https请求管理器和opener请求管理器:
from urllib import request, parse
from http import cookiejar
# 创建cookiejar实例
cookie = cookie.CookieJar()
# 创建cookie管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
# 创建http请求管理器
http_handler = request.HTTPHandler()
# 创建https请求管理器
https_handlder = request.HTTPSHandler()
# 创建opener请求管理器
opener = request.build_opener(cookie_handler, http_handler, https_handlder)
打开登录页面,查看源代码,找到