//
Gobblin采集kafka数据 - Syn良子 - 博客园
http://www.cnblogs.com/cssdongl/p/6121382.html
我这里额外配置了一个job.schedule让gobblin三分钟检查一次kafka的所有topic是否有新增,然后抽取任务就会三分钟一次定时执行.这里用的Gobblin自带的Quartz定时器.
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处
找时间记录一下利用Gobblin采集kafka数据的过程,话不多说,进入正题
一.Gobblin环境变量准备
需要配置好Gobblin0.7.0工作时对应的环境变量,可以去Gobblin的bin目录的gobblin-env.sh配置,比如
export GOBBLIN_JOB_CONFIG_DIR=~/gobblin/gobblin-config-dir
export GOBBLIN_WORK_DIR=~/gobblin/gobblin-work-dir
export HADOOP_BIN_DIR=/opt/cloudera/parcels/CDH-5.4.0-1.cdh5.4.0.p0.27/lib/hadoop/bin
也可以去自己当前用户bashrc下配置,当然,确保JAVA_HOME也已经配置.
这里配置的Gobblin的配置文件目录和工作目录以及执行MR需要用到的hadoop bin目录
二.Gobblin Standalone模式配置和使用
顾名思义,就是在部署Gobblin的单节点上来采集kafka数据,没有用到Hadoop MR,配置过程如下
首先去GOBBLIN_JOB_CONFIG_DIR下,新建一个gobblinStandalone.pull配置文件,配置如下
job.name=GobblinKafkaQuickStartjob.group=GobblinKafkajob.description=Gobblin quick start job for
Kafkajob.lock.enabled=falsejob.schedule=0 0/3 * * * ?kafka.brokers=datanode01
:9092source.class=gobblin.source.extractor.extract.kafka.KafkaSimpleSourceextract.namespace=gobblin.extract.kafkawriter.builder.class=gobblin.writer.SimpleDataWriterBuilderwriter.file
.path.type=tablenamewriter.destination.type=HDFSwriter.output.format=txtdata.publisher.type=gobblin.publisher.BaseDataPublishermr.job.max.mappers=1metrics.reporting.file.enabled=truemetrics.log.dir=${env:GOBBLIN_WORK_DIR}/metricsmetrics.reporting.file.suffix=txtbootstrap.with.offset=earliest
这里需要配置好抽取数据的kafka broker以及一些gobblin的工作组件,如source,extract,writer,publisher等,不明白的可以参考Gobblin wiki,很详细.
我这里额外配置了一个job.schedule让gobblin三分钟检查一次kafka的所有topic是否有新增,然后抽取任务就会三分钟一次定时执行.这里用的Gobblin自带的Quartz定时器.
ok,配置好以后进入Gobblin根目录,启动命令如:
bin/gobblin-standalone.sh –conffile $GOBBLIN_JOB_CONFIG_DIR/gobblinStandalone.pull start
我这里GOBBLIN_JOB_CONFIG_DIR有多个pull文件,因此需要指明,如果GOBBLIN_JOB_CONFIG_DIR下只有一个配置文件,那么直接bin/gobblin-standalone.sh start
即可执行
最终抽取过来的数据会输出到GOBBLIN_WORK_DIR/job-output 中去.
三.Gobblin MapReduce模式配置和使用
这次配置Gobblin会使用MapReduce来抽取kafka数据到Hdfs,新建gobblin-mr.pull文件,配置如下
job.name=GobblinKafkaToHdfsjob.group=GobblinToHdfs1job.description=Pull data from kafka to hdfs use Gobblinjob.lock.enabled=falsekafka.brokers=datanode01:9092source.class=gobblin.source.extractor.extract.kafka.KafkaSimpleSourceextract.namespace=gobblin.extract.kafkatopic.whitelist
=jsonTest
writer.builder.class=gobblin.writer.SimpleDataWriterBuildersimple.writer.delimiter=\nsimple.writer.prepend.size=falsewriter.file.path.type=tablenamewriter.destination.type=HDFSwriter.output.format=txtwriter.partitioner.class
=
gobblin.example.simplejson.TimeBasedJsonWriterPartitioner
writer.partition.level
=
hourly
writer.partition.pattern
=yyyy/MM/dd
/
HH
writer.partition.columns
=
time
writer.partition.timezone
=Asia/
Shanghai
data.publisher.type
=
gobblin.publisher.TimePartitionedDataPublisher
mr.job.max.mappers=1metrics.reporting.file.enabled=truemetrics.log.dir=/gobblin-kafka/metricsmetrics.reporting.file.suffix=txtbootstrap.with.offset=earliestfs.uri
=master:
8020
writer.fs.uri=${fs.uri}state.store.fs.uri=${fs.uri}mr.job.root.dir=/gobblin-kafka/workingstate.store.dir=/gobblin-kafka/state-storetask.data.root.dir=/jobs/kafkaetl/gobblin/gobblin-kafka/task-datadata.publisher.final.dir=/gobblintest/job-output
注意标红部分的配置第一行,我这里加了topic过滤,只对topic名称为jsonTest的主题感兴趣
因为需求是需要将gobblin的topic数据按照每天每小时来进行目录分区,具体分区目录需要根据kafka record中的时间字段来
我这里record是json格式的,时间字段格式如{…"time":"2016-10-12 00:30:20"…},因此需要继承Gobblin的TimeBasedWriterPartitioner来重写子类方法按照时间字段对hdfs的目录分区
以下配置需要注意
fs.uri
=master:
8020
改成自己的集群的hdfs地址
writer.partition.columns
=
time
这里的time和json中的时间字段保持一致即可
writer.partition.level
hourly
表示hdfs分区到小时
writer.partition.pattern
=yyyy/MM/dd
/
HH
表示最终需要在hdfs分区的目录格式(按照自己的最终分区需求自定义即可)
writer.partitioner.class
=
gobblin.example.simplejson.TimeBasedJsonWriterPartitioner
重写的hdfs按照json时间字段分区的子类,代码我提交到github了,参考如下链接
https://github.com/cssdongl/gobblin/blob/master/gobblin-example/src/main/java/gobblin/example/simplejson/TimeBasedJsonWriterPartitioner.java
将扩展后的类加入Gobblin相应的模块,我这里是放入gobblin-example模块中去了,重新build,build有问题的话请参考这篇文章
上面配置文件最后的那些路径都是hdfs路径,请确保Gobblin有读写权限
随后启动命令
bin/gobblin-mapreduce.sh --conf $GOBBLIN_JOB_CONFIG_DIR/gobblin-mr.pull
运行成功后,hdfs会出现如下目录,jsonTest是按照对应topic名称生成的,如下图

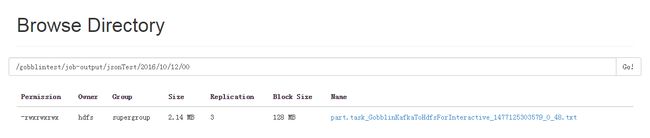
注意MR模式配置Quartz定时调度我试了好几次不起作用,因此如果需要定时执行抽取的话请利用外部的工具,比如Linux的crontab或者Oozie或者Azkaban都是可以的.
四.Gobblin使用总结
1>先熟悉Gobblin官方wiki,写的很详细
2>github上fork一个源代码仔细阅读下source,extract,partioner这块儿的代码
3>使用中遇到问题多研究Gobblin的log和Hadoop的log.
参考资料:
http://gobblin.readthedocs.io/en/latest/case-studies/Kafka-HDFS-Ingestion/
http://gobblin.readthedocs.io/en/latest/user-guide/Partitioned-Writers/
http://gobblin.readthedocs.io/en/latest/developer-guide/IDE-setup/
http://gobblin.readthedocs.io/en/latest/user-guide/FAQs/