UVa OJ 140 - Bandwidth (带宽)
Time limit: 3.000 seconds
限时3.000秒
Problem
问题
Given a graph (V,E) where V is a set of nodes and E is a set of arcs in VxV, and an ordering on the elements in V, then the bandwidth of a node v is defined as the maximum distance in the ordering between v and any node to which it is connected in the graph. The bandwidth of the ordering is then defined as the maximum of the individual bandwidths. For example, consider the following graph:
给定一个图(V,E),其中V为顶点的集合,E为边的集合,属于VxV。给定V中元素的一种排序,那么顶点v的带宽定义如下:在当前给定的排序中,与v距离最远的且与v有边相连的顶点与v的距离。给定排序的带宽定义为各顶点带宽的最大值。例如考虑如下图:
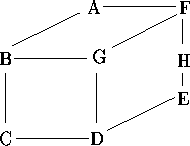
This can be ordered in many ways, two of which are illustrated below:
此图可以给出多种排序,其中两个排序图示如下:
![]()
For these orderings, the bandwidths of the nodes (in order) are 6, 6, 1, 4, 1, 1, 6, 6 giving an ordering bandwidth of 6, and 5, 3, 1, 4, 3, 5, 1, 4 giving an ordering bandwidth of 5.
对于给出的这两个排序,它们各结点的带宽分别是(按排序顺序):6, 6, 1, 4, 1, 1, 6, 6,排序带宽为6,以及5, 3, 1, 4, 3, 5, 1, 4,排序带宽为5。
Write a program that will find the ordering of a graph that minimises the bandwidth.
写一个程序,找出该图的一种排序使其带宽最小。
Input
输入
Input will consist of a series of graphs. Each graph will appear on a line by itself. The entire file will be terminated by a line consisting of a single#. For each graph, the input will consist of a series of records separated by `;'. Each record will consist of a node name (a single upper case character in the the range `A' to `Z'),followed by a `:' and at least one of its neighbours. The graph will contain no more than 8 nodes.
输入由一系列的图构成。每个图独占一行。一个仅包含“#”字符的一行输入标志整个输入文件结束。对于每个图的输入,都包含一系列由“;”隔开的记录。每个记录包含一个结点名(一个大写字母,范围是“A”到“Z”),接着是一个“:”,然后是一些该结点的邻居结点。图中不会包含超过8个结点。
Output
输出
Output will consist of one line for each graph, listing the ordering of the nodes followed by an arrow (->) and the bandwidth for that ordering. All items must be separated from their neighbours by exactly one space. If more than one ordering produces the same bandwidth, then choose the smallest in lexicographic ordering, that is the one that would appear first in an alphabetic listing.
每个图对应一行输出,列出排序的结点,然后是一个箭头(->)以及该排序的带宽值。所有项都应由一个空格与它相邻的项隔开。如果同一个带宽有多种排序方法,取字母序最小的一种排序,也就是取字母表排在前面的一种排序。
Sample input
示例输入
A:FB;B:GC;D:GC;F:AGH;E:HD
#
Analysis
分析
典型的优化问题,一个可行解就是一个排序,目标函数就是解的带宽。但ACM的优化问题一定是使用确定性算法的(与包含随机元素的现代优化算法如遗传、粒子相对),确定性优化算法就那么几种,贪心、动态规划、单纯行(解线性规划)还有就是暴力。注意到题中专门强调:图不会超过8个结点,结点的名字都是从“A”到“Z”,相同带宽的排序取字典序靠前等,所有的线索都指向了一种算法:暴力搜索。
从要求的“字典序”得到启发:全排列生成算法。剩下的问题就是以何种数据结构来存储,以便快速的查找顶点和计算带宽。对于一种顶点的排序,要查找指定顶点所在的位置,最快的方法就是使用标记数组。由于题中限定的顶点的取值范转:“A”到“Z”,因此用一个26个元素的数组即可记录每个顶点在排序中的位置。
记下顶点的位置后,需要用最快的方式查出每个顶点到它的邻居的距离,这实际就是在当前排序中找出相距最远的一条边。因此只要遍历图中所有的边,计算其在当前排序中的距离,并记录最远的距离即可。图可以用边的集合来表示图,每个边用两个顶点来表示。由于是无向图,因此可使边的两个顶点程左小右大排序,然后保证无重边即可。
Solution
解答
#include "stdafx.h"
#include <algorithm>
#include <iostream>
#include <vector>
#include <string>
typedef std::pair<char, char> NODEPAIR;
typedef std::vector<char>::iterator NODE_ITER;
typedef std::string::iterator STR_ITER;
typedef std::vector<NODEPAIR>::iterator GRAPH_ITER;
int main(void)
{
char idxTbl[32]; // 从顶点编号到其在某种排序中的位置的对应表
std::string strLine; // 存储一行输入的字符串
for (; std::getline(std::cin, strLine) && strLine[0] != '#'; ) {
std::vector<NODEPAIR> graph; // 数组中每个元素为一条边,用一对顶点的编号表示
std::vector<char> nodes; // 记录一种顶点的排序
// 为方便判断一行输入的结束,在行层添加分号
strLine.push_back(';');
// 循环处理当前输入行的每一个字符
for (STR_ITER i = strLine.begin(); i != strLine.end(); ++i) {
// 用所有边的顶点对来表示图,nFrom是冒号前的顶点,nTo是冒号后的顶点
char nFrom = *i - 'A'; // 每个顶点的编号为其字母的ASCII码-'A'
// 有些顶点只出现在冒号前,有些只出现在冒号后,因此nFrom和nTo都需添加
nodes.push_back(nFrom);
// 遍历冒号后面直到分号的顶点,这些顶点用nTo表示
for (i += 2; *i != ';'; ++i) {
char nTo = *i - 'A'; // 每个顶点的编号为其字母的ASCII码-'A'
nodes.push_back(nTo);
// 保证添加到图中的顶点对(边)中编号较小的顶点在前,避免无向图的重复边
if (nFrom > nTo)
graph.push_back(NODEPAIR(nFrom, nTo));
else if (nFrom < nTo)
graph.push_back(NODEPAIR(nTo, nFrom));
}
}
// 对图的所有顶点对(边)排序去重
std::sort(graph.begin(), graph.end());
graph.erase(std::unique(graph.begin(), graph.end()), graph.end());
// 对顶点数组排序去重,作为第一种排序(升序最小)
std::sort(nodes.begin(), nodes.end());
nodes.erase(std::unique(nodes.begin(), nodes.end()), nodes.end());
std::vector<char> minOrder; // 记录具有最小带宽的排序
char nMinBw = char(nodes.size()); // 记录具有最小的带宽,初始化为数组长度
for (bool bNext = true; bNext; ) { // 遍历所有排序
char nCnt = 0, nOrderBw = 0;
// 扫描一遍当前的排序,求出每一个顶点在当前排序中的位置
for (NODE_ITER i = nodes.begin(); i != nodes.end(); ++i) {
idxTbl[*i] = nCnt++;
}
// 遍历图中的所有顶点对,找出在当前排序中距离最远的顶点对作为当前排序的带宽
for (GRAPH_ITER i = graph.begin(); i != graph.end(); ++i) {
char nCur = char(std::abs(idxTbl[i->first] - idxTbl[i->second]));
if (nCur > nOrderBw)
nOrderBw = nCur;
}
// 如果当前排序的带宽小于已知最小带宽,则更新最小带宽和最小排序
if (nOrderBw < nMinBw) {
nMinBw = nOrderBw;
minOrder = nodes;
}
// 接字母序给出下一种排序
bNext = std::next_permutation(nodes.begin(), nodes.end());
}
// 按格式循环输出最小排序和它的带宽值
for (NODE_ITER i = minOrder.begin(); i != minOrder.end(); ++i) {
std::cout << char(*i + 'A') << ' ';
}
std::cout << "-> " << (int)nMinBw << std::endl;
}
return 0;
}