Oracle corrupt block(坏块) 详解
转自:http://blog.csdn.net/tianlesoftware/article/details/5024966
一. 坏块说明
1.1 相关链接
在看坏块之前,先看几个相关的链接,在后面的说明中,会用到链接中的一些内容。
http://blog.csdn.net/tianlesoftware/article/details/6645809
http://blog.csdn.net/tianlesoftware/article/details/6106178
Current online Redo 和 Undo 损坏的处理方法
http://blog.csdn.net/tianlesoftware/article/details/6261475
http://blog.csdn.net/tianlesoftware/article/details/5015164
http://blog.csdn.net/tianlesoftware/article/details/5006580
http://blog.csdn.net/tianlesoftware/article/details/6684505
http://blog.csdn.net/tianlesoftware/article/details/6654786
MOS 上的相关文档:
RMAN: Block-Level Media Recovery - Concept & Example [ID 144911.1]
FAQ:Physical Corruption [ID 403747.1]
MasterNote for Handling Oracle Database Corruption Issues [ID 1088018.1]
HandlingOracle Block Corruptions in Oracle7/8/8i/9i/10g/11g [ID 28814.1]
ExtractingData from a Corrupt Table using ROWID Range Scans in Oracle8 and higher [ID61685.1]
官网的链接:
ValidatingDatabase Files and Backups
http://download.oracle.com/docs/cd/E11882_01/backup.112/e10642/rcmvalid.htm#CHDCEHFD
Performing Block Media Recovery
http://download.oracle.com/docs/cd/E11882_01/backup.112/e10642/rcmblock.htm#CHDCBIIB
老熊的一篇文章:
http://www.laoxiong.net/how_to_mark_corruption_block_and_recovery.html
1.2 block corruption 分类
For purposes of the paper we will categorize corruption under three general areasand give best practices for prevention, detection and repair for each:
Memory corruption
Logical corruption(soft corruption)
Media corruption(Physicalcorruption)
Physicalor structural corruption can be defined as damage to internal data structureswhich do not allow Oracle software to find user data within the database. Logical corruption involves Oracle beingable to find the data, but the data values are incorrect as far as the end useris concerned.
Physica lcorruption due to hardware or software can occur in two general places -- inmemory (including various IO buffers and the Oracle buffer cache) or on disk.Operator error such as overwriting a file can also be defined as a physicalcorruption. Logical corruption on theother hand is usually due to end-user error or non-robust(?) applicationdesign. A small physical corruption such as a single bit flip may be mistakenfor a logical error.
1.3 查看blockcorruption
可以通过v$database_block_corruption 查看database 的corruption。 官网对该视图的定义如下:
V$DATABASE_BLOCK_CORRUPTION displaysinformation about database blocks that were corrupted after the last backup.
SYS@dave2(db2)>desc v$database_block_corruption
Name Null? Type
------------------------------------------------- ----------------------------
FILE# NUMBER
BLOCK# NUMBER
BLOCKS NUMBER
CORRUPTION_CHANGE# NUMBER
CORRUPTION_TYPE VARCHAR2(9)
SYS@dave2(db2)> select * fromv$database_block_corruption;
no rows selected
这里没有坏块,为了演示这个效果,我用BBED 制造一个坏块,然后在用bbed 恢复过来。
先确定block:
SYS@dave2(db2)> select * from dvd;
JOB
--------------------------------------------------------------------------------
DMM is DBA!
dmme like Oracle!
SYS@dave2(db2)>select
2 rowid,
3 dbms_rowid.rowid_relative_fno(rowid)rel_fno,
4 dbms_rowid.rowid_block_number(rowid)blockno,
5 dbms_rowid.rowid_row_number(rowid) rowno
6 from dvd;
ROWID REL_FNO BLOCKNO ROWNO
------------------ ---------- --------------------
AAAN9hAAGAAAAAcAAA 6 28 0
AAAN9hAAGAAAAAcAAB 6 28 1
用bbed 修改block 28:
[oracle@db2 ~]$ bbed parfile=/u01/bbed.par
Password:
BBED: Release 2.0.0.0.0 - LimitedProduction on Mon Aug 15 22:15:10 2011
Copyright (c) 1982, 2005, Oracle. All rights reserved.
*************!!! For Oracle Internal Use only !!! ***************
BBED> set dba 6,28
DBA 0x0180001c(25165852 6,28)
BBED> map
File: /u01/app/oracle/oradata/dave2/dave01.dbf(6)
Block: 28 Dba:0x0180001c
------------------------------------------------------------
KTBData Block (Table/Cluster)
struct kcbh, 20 bytes @0
struct ktbbh, 96 bytes @20
struct kdbh, 14 bytes @124
struct kdbt[1], 4 bytes @138
sb2kdbr[2] @142
ub1freespace[8005] @146
ub1rowdata[37] @8151
ub4tailchk @8188
BBED> d /voffset 0 count 128
File: /u01/app/oracle/oradata/dave2/dave01.dbf(6)
Block: 28 Offsets: 0 to 127 Dba:0x0180001c
-------------------------------------------------------
06a20000 1c008001 f4a90780 00000104 l.¢......ô©......
f5b40000 01000000 61df0000 f4a90780 lõ´......aß..ô©..
00000000 03003200 19008001 03001000 l......2.........
3b0a0000 00000000 00000000 00800000 l;...............
dda90780 00000000 00000000 00000000 lݩ..............
00000000 00000000 00000000 00000000 l................
0000000000000000 00000000 00000000 l ................
00000000 00000000 00000000 00010200 l................
<16 bytes per line>
BBED> modify /x 12345678 offset 0
File: /u01/app/oracle/oradata/dave2/dave01.dbf(6)
Block: 28 Offsets: 0to 127 Dba:0x0180001c
------------------------------------------------------------------------
12345678 1c008001 f4a90780 00000104 f5b4000001000000 61df0000 f4a90780
00000000 03003200 19008001 03001000 3b0a000000000000 00000000 00800000
dda90780 00000000 00000000 00000000 0000000000000000 00000000 00000000
00000000 00000000 00000000 00000000 0000000000000000 00000000 00010200
<32 bytes per line>
BBED> sum apply
Check value for File 6, Block 28:
current = 0x5ab7, required = 0x5ab7
SYS@dave2(db2)>alter system flush buffer_cache;
System altered.
SYS@dave2(db2)> select * from dvd;
select * from dvd
*
ERROR at line 1:
ORA-01578: ORACLE data block corrupted(file # 6, block # 28)
ORA-01110: data file 6:'/u01/app/oracle/oradata/dave2/dave01.dbf'
这里提示块有错误,我们查看下一下:v$database_block_corruption:
SYS@dave2(db2)> select * fromv$database_block_corruption;
no rows selected
这里显示为空,但是我们之前看该视图的定义的时候,说是自上次备份以来的坏块。所以这里我们验证一下:
RMAN> backup validate datafile 6;
Starting backupat 15-AUG-11
using target database control file insteadof recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: sid=141 devtype=DISK
channel ORA_DISK_1: starting full datafilebackupset
channel ORA_DISK_1: specifying datafile(s)in backupset
input datafile fno=00006 name=/u01/app/oracle/oradata/dave2/dave01.dbf
channel ORA_DISK_1: backup set complete,elapsed time: 00:00:02
Finished backup at 15-AUG-11
在次select 查询:
SYS@dave2(db2)> select * from v$database_block_corruption;
FILE# BLOCK# BLOCKSCORRUPTION_CHANGE# CORRUPTIO
---------- ---------- ---------------------------- ---------
6 15 1 0 CORRUPT
6 28 1 0 CORRUPT
这次就查询到结果了。 视图显示block的状态为corrupt。 对于该类型,共有一下几种:
(1)ALL ZERO:Block header on disk contained only zeros. The block may be valid ifit was never filled and if it is in an Oracle7 file. The buffer will bereformatted to the Oracle8 standard for an empty block.
(2)FRACTURED: Block header looks reasonable, but the front and back of the blockare different versions.
(3)CHECKSUM: optional check value shows that the block is not self-consistent.It is impossible to determine exactly why the check value fails, but itprobably fails because sectors in the middle of the block are from differentversions.
(4)CORRUPT: Block is wrongly identified or is not a data block (for example,the data block address is missing)
(5)LOGICAL: Specifies the range is for logically corrupt blocks.CORRUPTION_CHANGE# will have a nonzero value.
现在用BBED还原block:
BBED> revert
All changes made in this session will berolled back. Proceed? (Y/N) y
Reverted file'/u01/app/oracle/oradata/dave2/dave01.dbf', block 28
Warning: contents of previous BIFILE willbe lost. Proceed? (Y/N) y
BBED> sum apply
Check value for File 6, Block 28:
current = 0xb4f5, required = 0xb4f5
在次查询,block 正常:
SYS@dave2(db2)> alter system flushbuffer_cache;
System altered.
SYS@dave2(db2)> select * from dvd;
JOB
--------------------------------------------------------------------------------
DMM is DBA!
dmme like Oracle!
但是注意我们的v$database_block_corruption 视图:
SYS@dave2(db2)> select * fromv$database_block_corruption;
FILE# BLOCK# BLOCKSCORRUPTION_CHANGE# CORRUPTIO
---------- ---------- ---------------------------- ---------
6 15 1 0 CORRUPT
6 28 1 0 CORRUPT
corruption block的信息还存在里面。 之前经过该视图和备份有关,我们用rman validate 一下datafile,之后就ok了。
RMAN> backup validate datafile 6;
Starting backupat 15-AUG-11
using channel ORA_DISK_1
channel ORA_DISK_1: starting full datafilebackupset
channel ORA_DISK_1: specifying datafile(s)in backupset
input datafile fno=00006name=/u01/app/oracle/oradata/dave2/dave01.dbf
channel ORA_DISK_1: backup set complete,elapsed time: 00:00:01
Finished backup at 15-AUG-11
SYS@dave2(db2)>select * from v$database_block_corruption;
FILE# BLOCK# BLOCKSCORRUPTION_CHANGE# CORRUPTIO
---------- ---------- ---------------------------- ---------
6 15 1 0 CORRUPT
--说明,我们修改的是block 28,它已经消失了。block 15 不是我们这本次测试修改的。 它是历史遗留问题。这里就不讨论了。
如果用rmanvalidate 之后还没有消失,可能是oracle的bug,参考:
V$Database_Block_CorruptionDoes not clear after Block Recover Command [ID 422889.1]
1.4 使用RMAN 验证和recover corruption
之前有整理相关的文章,参考:
http://blog.csdn.net/tianlesoftware/article/details/6460464
RMAN的默认validate 只验证物理坏块,不验证逻辑坏块。
验证所有datafile 和归档是否有物理坏块:
RMAN>backup validate database archivelogall;
或者
RMAN>backup validate database;
验证所有datafile 和归档的物理坏块和逻辑坏块:
RMAN>backup validate check logicaldatabase archivelog all;
或者:
RMAN>backup validate check logicaldatabase;
注意: 如果加上了archivelog all,就必须要有归档文件存在。
在Oracle 11g里还可以单独验证某一个数据块:
RMAN>VALIDATE DATAFILE 1 BLOCK 10;
对于物理坏块,我们可以通过recover database 或者recover datafile 来解决,但是对于逻辑坏块这种方法就不行。 在后面单独讲到逻辑坏块时有说明。对于逻辑坏块可以尝试对对象进行重建,如重建索引,重建表在导入数据。
对于物理坏块,如果不使用recover,那么块上的data 基本是丢失的。 我们可以采用相关的event或者通过rowid来跳过block,导出数据。 要保证块上数据不丢失,就需要通过RMAN有效的备份来进行recover。
相关的recover 命令如下:
RMAN>blockrecover datafile 6 block 15;
或者:
RMAN> blockrecover corruption list;
该命令recover 的所有block 来自v$database_block_corruption视图。
RMAN : Block-Level Media Recovery - Concept& Example [ID 144911.1]
二. Memory Corruption
2.1 Background
Oracle allocates both shared and private memory. Shared memory is allocated when an Oracle instance starts and all processes(or threads) connecting to an Oracle database can access it. Oracle softwaredefines how this shared resource is accessed to prevent multiple processes fromsimultaneously writing to the same address. It also has to recover any incomplete changes made to memory by aprocess that dies abnormally. The amountof shared memory allocated is static in size and is only freed when theinstance is shut down. Private memory isallocated and freed as needed by each process (or thread) at the OS level.
Corruptionis more likely to occur within shared memory than private memory so we focusattention to the structures and algorithms used within shared memory (alsoknown as the Oracle SGA).
The SGA is divided into four portions - fixed, variable,Database Buffer cache, and Redo log buffer. A diagram appears below.
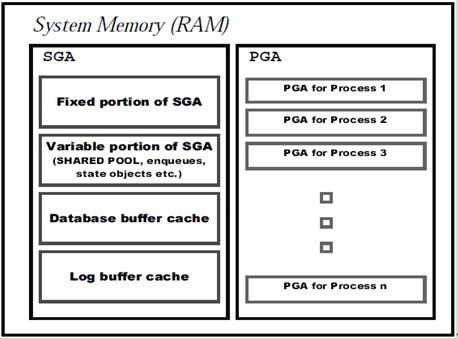
2.2 Definition
Memory corruption can be defined as inconsistencies in the data structures that arerelated to handling memory. Thisinconsistency could appear in any of the different parts of memory discussedabove. As discussed in the sectionabove, corruption in memory can be caused either in the SGA or the PGA.
Onlycorruption in the database buffer cache portion of the SGA can potentially leadto data loss.
Thisis termed as ‘Cache corruption’ and is discussed in detail below. Corruption in theother parts of SGA do not result in loss of data, but can still cause theinstance to crash. On the otherhand, a corruption in the PGA causes only the corresponding process tocrash. If this process is updating ablock in the buffer cache when this happens, then the background process, PMONdoes the necessary recovery on the block being changed by this process. SMON and otherprocesses will rollback any other uncommitted data.
2.3 Cache corruption
TheOracle buffer cache is a mechanism where frequently accessed blocks are storedin memory for quicker access. The cache also maintains older versions of blocksfor consistent read purposes. If thereis a corruption in this part of memory then there is a possibility of loss ofdata.
Theforeground processes read Oracle blocks from the disk into the buffercache. There arecertain checks done on the data block when it is read from the disk.
For example, one of the checks is to compare the Incarnation Number (INC) andSequence Number (SEQ) data structures from the header of the data block withthe INCSEQ structure in the footer to make sure that the block versions match.This is done to avoid reading a block from disk whose header is corrupt.
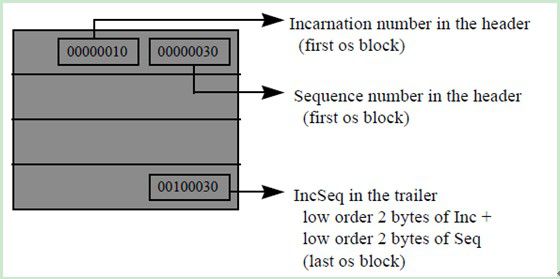
The structuresdiscussed above is specific to version 7.
2.4 Causes
In general, memory corruption is usually identified by abackground or shadow process whenever ittries to access the part of memory that is corrupted. Cache corruption, which might cause a loss ofdata, is usually caught by:
(1)the shadow process when trying to read or update a block in memory,
(2)by the background process, DBWR, when trying to write a dirtied block frommemory to disk,
(3)by the background process, PMON, while performing block recovery.
Common causes include:
(1)Operatingsystem bugs causing bad reads or bad writes
(2)Hardware issues
(3)Oracle bug
(4)Non-Oracle program attaching and illegally writing to the sameshared memory address
2.5 Prevention
There is very little that can be done from the user’s perspective to prevent memorycorruption. An INIT.ORA parameter, DB_BLOCK_CHECKSUM can be set to true.
This enables another check where the block checksum is calculated and compared withthe checksum stored in the block header. If they aredifferent then the block is considered corrupt on disk, and the block is notread into memory. This prevents corrupt blocks from entering the cache.When a block is changed and being written to disk from memory, DBWR calculatesa new checksum for the block by summing up its contents and writes it in theblock header.
There is a CPU overhead associated with this parameter since the checksum is calculated every time a block is read and written.
A similar parameter, LOG_BLOCK_CHECKSUM, can be set totrue in the INIT.ORA for verifying the records written to the redo log buffer. This extra test prevents bad redo from beingapplied to a block in cache during recovery. There is CPU overhead for reasons similar to the DB_BLOCK_CHECKSUM.
The best form of corruption prevention from occurring in a production environmentis to test the hardware, operating system, database, application and so on forbugs before rolling them into production. This is also true when introducing new hardware, patches and upgrades.
2.6 Detection
Memorycorruption can be detected from errors in the operating system logs indicatingany kind of memory problems. These canalso be found from the Oracle ALERT.LOG by certain ORA-600 errors. The first argument ofthe ORA-600 could be from 17000 through 17999 in case of memory corruption.
Somecache corruption can be detected by ORA-600s in the range from 2000 through8000. One thing to remember is that notall ORA-600s imply memory corruption.
对于memory corruption的错误提示,是ORA-600的第一个参数值从17000到17999或者2000到8000. 这里只是一种可能,并不完全肯定。
http://blog.csdn.net/tianlesoftware/article/details/6645809
2.7 Repair
| Location |
Data loss |
Repair |
| SGA - Buffer cache |
Probable data loss |
⇒ If the corrupt block has been written to disk, then the object to which the block belongs to has to be repaired by methods discussed under Media corruption. ⇒ SHUTDOWN and STARTUP the instance ⇒ To diagnose the causes for the corruption, call Oracle support with appropriate files listed below the table. |
| SGA - Redo buffer |
No data loss |
⇒ SHUTDOWN and STARTUP the instance. ⇒ To diagnose the causes for the corruption, call Oracle support with appropriate files listed below the table |
| SGA - Shared SQL Area |
No data loss |
⇒ SHUTDOWN and STARTUP the instance. ⇒ To diagnose the causes for the corruption, call Oracle support with appropriate files listed below the table |
| PGA |
No data loss |
⇒ To diagnose the causes for the corruption, call Oracle support with appropriate files listed below the table |
To diagnose the cause of the corruption, call Oracle support with the followinginformation:
(1)INIT.ORA file
(2)ALERT.LOG
(3)Trace files for any ORA-600s found in the directory specified by theINIT.ORA parameter, USER_DUMP_DEST
(4)Heap dump : this can be obtained by executing the following commandin SVRMGR or SQLDBA:
SQL>ALTER SESSION SET EVENTS ‘IMMEDIATE TRACE NAME HEAPDUMP, LEVEL 10’;
This creates a trace file in the USER_DUMP_DEST.
(5)Reproducibletest case
(6)Thorough history of events that led to the corruption
(7)Record any noticeable changes to the environment such as newINIT.ORA parameters, new code, patches, and upgrades.
三. Logical Corruption (soft corruption)
LogicalCorruption can be defined as a situation where the actual data is not corruptedin a data block but a query results in a wrong set of data due to a problem inthe way data was loaded into the database or due to a misexecution of theoptimizer path. A logical corruption is not an inconsistencyin a data block but an inconsistency in the result of a query.
逻辑坏块通常不是data block的不一致,而是查询结果的不一致。
Forexample, a query that is expected to fetch 5 rows might result in 10 rowsbecause the data in the table was duplicated due to the lack of a primary orunique key.
比如我们查询5行记录,实际却返回10行。
3.1 Causes
Badapplication design that lacks validation or proper integrity checks OptimizerBugs (in rare cases)
通常是应用设计不完善或者是优化器的bug造成。
3.2 Prevention
The only kind of prevention methodology for avoiding user errors is to test thatapplications return valid results thoroughly before implementing them inproduction environments.
There cannot be a way to prevent logical corruption caused due to optimizer problemsunless the appropriate patches are applied or the database is upgraded to themost recent version.
3.3 Detection
When logical corruption is caused by user errors, they are more difficult to detectthan those caused by optimizer problems. In case of user errors, the user should have a good knowledge of theapplication that is being run to identify inconsistencies in the queryresults. In the case of optimizerproblems, inconsistencies may be accompanied by changes in the query executionplan leading to a different response time.
Also one may notice, invalid results only when using the cost based optimizer rather than the rule based optimizer. Other changes inthe query path can be caused by changing the optimizer mode, specifying a different optimizer hint, dropping or creatingindexes, or analyzing objects to generate new statistics.
3.4 Repair
Whenthese problems are caused by user errors, they can be fixed by making theapplication more robust.
解决这个问题需要完善系统的设计。
Fo rexample, if invalid data is successfully inserted into a table because of alack of integrity checking , then constraints should be created and the invaliddata will have to be found and deleted. In case of optimizer problems, contactWorldwide Customer Support Services to determine if this is a bug with anavailable patch.
They will need to be provided with the query, EXPLAIN PLAN and potentially theexport dump of the tables involved.
四. Media Corruption(physical corruption )
Media corruption can be defined as a situation where an inconsistency has occurred inthe data block structures in the physical disk as a result of mediafailures. Media failures are failuresthat are caused due to hardware problems, operating system problems, controllerproblems, logical volume problems, and so on. As a result of a media corruption, the data in the corrupted block islost.
物理坏块通常是block上的不一致,造成物理坏块的原因可能是硬件故障,操作系统问题,控制器问题,逻辑卷问题等。 对于物理坏块,其block上的数据会丢失。
MediaCorruption could occur in different parts of the database and the detection,prevention and repair are different depending on the object that iscorrupted. The following are differentobjects that could be corrupted:
物理坏块可以存在数据库的不同部分,对应不同部分的处理方法也不一样,具体可以以下下几种:
∗ Control file
∗ Redo log file
∗ Data file The block could belong to one of the following categoriesin case of data file corruption:
(1)File header block
(2)Data dictionary object (SYSTEM tablespace)
(3)Undo header and Undo blocks (ROLLBACK tablespace)
(4)Sort blocks (TEMP tablespace)
(5)Data/Index blocks (DATA/INDEX tablespace)
=>Tables
=>Clusters
=>Indexes
4.1 Control filecorruption
TheControl file is the file that has the structural information of thedatabase. The control file hasinformation such as the database name, names and locations of the data filesand the redo log files belonging to the database, the creation timestamp of thedatabase, log sequence information, checkpoint information and so on.
控制文件包含了数据库的一些结构信息。
The control file can be dumped in asciiformat by executing the command:
ALTERSESSION SET EVENTS ‘IMMEDIATE TRACE NAME CONTROLF LEVEL 10’;
This command creates a trace file in the location defined by the INIT.ORA parameter,USER_DUMP_DEST.
可以dump 控制文件。 有关控制文件的更多内容参考我的blog:
http://blog.csdn.net/tianlesoftware/article/details/4974440
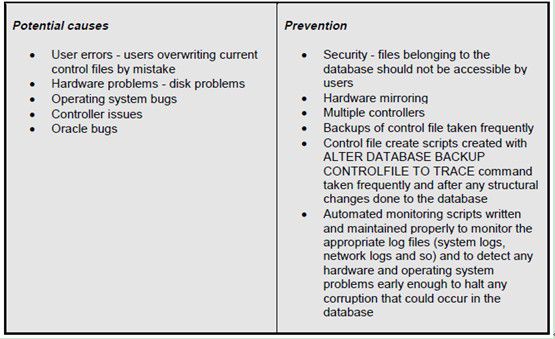
Whenany of the mirrors (Oracle’s multiplexing) of the control file is corrupted,critical information about the database cannot be accessed which will result ina database crash. The following tablesexplain the potential causes, detection, prevention and repair of a corruptionin the current control file.
虽然控制文件有冗余,但是任何一个控制文件出现损坏都会导致db crash。
4.1.1 Causes and Prevention
4.1.2 Detectionand Repair
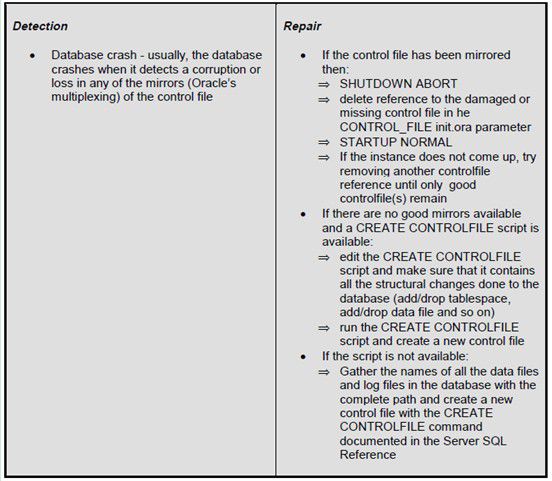
控制文件通常有三个,任何一个出现corrupt都会使db crash。 这种情况下,可以修改初始话参数,使用其他的几个控制来启动db,如果能启动,就ok。不能启动,就需要重建控制文件来解决。 关于控制文件的重建,我上面贴的链接里有。
4.2 Redo log file corruption
Redolog files are critical in protecting a database from failures. The changes made to data in a database arerecorded in the redo log files.
redo 是在db failures来进行恢复的,所有的事务操作都会记录到redolog里。
When there is a failure which prevents data from being written to the data files ondisk from memory, the changes can be obtained from the redo log files. When a data file is corrupted, a backup froman earlier day can be restored and the changes from that day onwards can beapplied to the data file from the redo log files.
The redo log files are used only when a database is recovered from a failure. There are two kinds of redo log files: Onlineredo log files and Archived redo log files. Archived redo log files are the spooled copies of the online redo logfiles.
Corruption could occur in an online redo log file or an archived redo log file. If a corruption occurs on an online redo logfile, the instance crashes if there are no mirrors of the redo log file or ifthe mirrors are corrupted as well. Ifthe corruption occurs in an archived redo log file, the database is notaffected unless a backup is restored and recovery is being done for which it isneeded.
corruption 可能发生在online log 或archived log。 如果发生在online log,并且log 没有镜像或者镜像log也出现了坏块,这种情况下,db 会crash。 如果出现在归档文件上,仅当使用备份进行恢复时才会有影响。
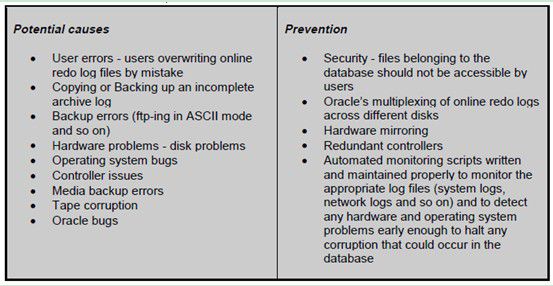
4.2.1 Causes and Prevention
4.2.2 Detectionand Repair
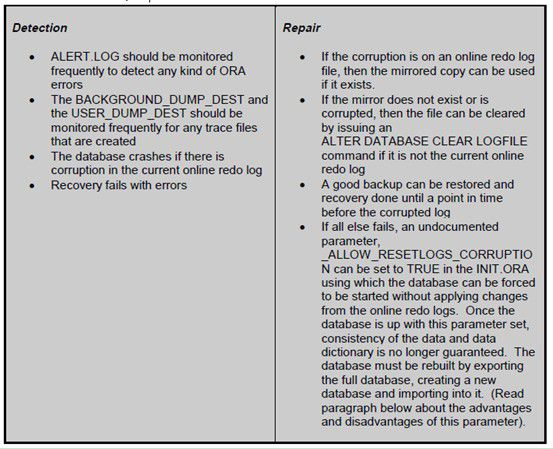
Forcing the database tostartup using _ALLOW_RESETLOGS_CORRUPTION:
This parameter is undocumented and unsupported.
The_allow_resetlogs_corruptionshould only be done as a last resort. Usually when a database is opened witheither the RESETLOGS or NORESETLOGS option, the status and checkpointstructures in all the file headers of all data files are checked to make surethat they are consistent. Once this ischecked, the redo logs are zeroed out in case of RESETLOGS. When the _ALLOW_RESETLOGS_CORRUPTIONparameter is set, the file header checks are bypassed. This means that we do not make sure that thefiles are consistent and open the database. It will potentially cause some lost data and lost data integrity. The database should be rebuilt since data andthe data dictionary could be corrupt in ways that are not immediatelydetectable. This could lead to futureoutages or put the database in a state where it cannot be salvaged at all. There is no guarantee that this will work.
Advantages
nsome circumstances, database can be brought up even when no valid backups areavailable
Disadvantages
(1)The database will not be in aconsistent state once the undocumented parameter is used and so it has to berebuilt by doing a full database export, recreate the database and a fulldatabase import.
(2)Not guaranteed to work
关于online redocorrupt,曾经整理过,参考:
Current online Redo 和 Undo 损坏的处理方法
http://blog.csdn.net/tianlesoftware/article/details/6261475
http://blog.csdn.net/tianlesoftware/article/details/6106178
4.3 Data file corruption
The data files are the physical storage unit of data stored in a database. Each data file ismade up of data blocks which can be divided into 5 different types (in thecontext of media corruption):
(1)File header blocks : File header block is the first Oracle block inevery data file in an Oracle database. This block keeps track of a lot of information about the data file thatit belongs to.
(2)Data Dictionary blocks : SYSTEM tablespace consists of datadictionary objects. Data dictionaryobjects are objects that keep track of information stored in the database suchas the information about the tablespaces, information about the data files,information of amount of free space in each tablespace.
(3)Undo header and Undo blocks: ROLLBACK tablespace consists ofrollback segments that are made up of undo header blocks and undo blocks. These blocks are used to undo a transactionwhen it fails or when the user executes a ROLLBACK command.
(4)Sort blocks: TEMP tablespace consists of temp segments that are madeup of sort blocks. Sorts are usually done in memory where they are allocated asize specified by the INIT.ORA parameter, SORT_AREA_SIZE amount of space. If the sort is so huge that it cannot fit inthe allocated space in memory, then temp segments are created in the user’stemporary tablespace for doing the sort on disk.
(5)Data blocks: DATA tablespace consists of tables, clusters andindexes.
The following tables explain the potential causes of data file corruption and alsothe different ways to prevent data file corruption.
4.3.1 Causes and Prevention
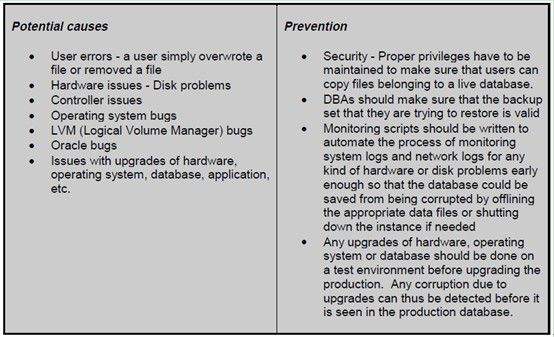
Now that we have discussed the causes and the prevention, let us discuss thedetection and repair which is different for corruption in different blocks.
4.3.2 File header block
Fileheader block is the first Oracle block in a data file. This block keeps track of information aboutthe data file itself (i.e., file metadata) including different checkpointstructures (explained below), status of the file (e.g., hot backup in progress,hot backup ended, media recovery required, instance recovery required), andresetlogs information (information on the time when the database has beenbrought with resetlogs option most recently).
File header block 是data file的第一个block。 它保存了datafile的一些信息。
Checkpointingis the process of writing the blocks that have been changed in memory to disk.The control file and the data file headers are updated after every checkpointis done in the database. This is anautomatic action executed by the background process called the Database Writer(DBWR). This can also be forced bycertain user commands such as a normal SHUTDOWN, a normal OFFLINE of atablespace and so on.
checkpoint进程会将已经变更的block从内存写如磁盘。 每次执行checkpoint时,dbwr 进程会更新controlfile 和 datafileheaders。 当normal shutdown 或者normal offline tablespace时,也会更新control file 和datafile headers.
Thedata file header block keeps track of the most recent checkpoint informationwhich denotes that all blocks in this data file that has been changed beforethis checkpoint has been written to disk from memory and so a failure in thememory will not affect the data in this data file before the checkpoint.
datafile header 保存了最近一次checkpoint的信息,它表示该checkpint 之前已经改变的block已经从内存写入磁盘了。 当memory 发生错误时,不会影响该checkpoint 之前的data。
Whena file header block is corrupted, the information stored in this block cannotbe accessed which means that the objects in the data file cannot be accessedeither. The following tables give anidea of the potential causes for a corruption in a file header block and theprevention, detection and repair of the same.
当 fileheader block 发生corrupted时,存储在该block里的信息无法读取,那么的data file 也就无能读取。

在我的blog 里的示例四,就是使用bbed修改data file header的:
http://blog.csdn.net/tianlesoftware/article/details/6684505
4.3.3 Data dictionary object (SYSTEM tablespace)
Datadictionary objects are objects that reside in the SYSTEM tablespace which hascritical information about the objects in the database and their relationshipsand attributes.
Data dictionary 对象存放在system 表空间,它保存了数据库中对象的重要信息,如对象之间的关系和属性等。
Data dictionary objects found in the systemtablespace are described below:
SYSTEM 表空间下的data dictionary objects 有如下几种:
1)Objects created by the script SQL.BSQ run by the CREATEDATABASE command found under $ORACLE_HOME/dbs directory. There are certain tables, indexes andclusters that cannot be dropped and recreated in the SYSTEM tablespace. These are the tables that are used whenbringing up the database. They arecalled the bootstrap objects and are found in the SQL.BSQ. It is not an easy task to locate datadictionary objects that can be dropped and recreated since the relationsbetween the different objects could result in an inconsistent database if wedrop the wrong object.
datadictionary 是在创建数据库时通过$ORACLE_HOME/dbs/sql.bsq脚本创建的,并且这些核心的表,索引和clusters 不能被drop 和recreate。 他们在db 启动时使用。
2) Views createdon the fixed data structures (V$ views).
3)SYSTEM rollback segment created after the databasecreation. If the corruption is in this segment, then the most recentbackup should be restored and a point in time recovery should be done on thedatabase up to the time when the corruption could have occurred.
system rollback segment 在数据库创建之后创建。 关于systemrollback segment在我的blog里有说明:
Current online Redo 和 Undo 损坏的处理方法
http://blog.csdn.net/tianlesoftware/article/details/6261475
4)Compatibility segment (this is the only segment of type ‘CACHE’ in the SYSTEMtablespace). The Compatibility segment is a segment that keeps track of thefeatures being used in the database which will be used when the database isbeing downgraded to an earlier version. This segment is used to make sure thatthe features being used in the current version are disabled before beingdowngraded to the earlier version. Ifthe compatibility segment has a corruption then, the database can be brought upby shutting down and starting it up. Ifthe problem is still not fixed call Oracle support with appropriate trace filesand the alert.log.
The supported way of fixing data dictionary corruption is to restore from a backupand roll forward using the archived redo logs.

4.3.4 Undo header and Undo blocks (ROLLBACK tablespace)
Rollback segments are undo segments that have information about the transaction that hasbeen executed so that it can be rolled back in case of failure of thetransaction or when the user asks for the transaction to be rolled backexplicitly.
They are made up of undo header blocks and undo blocks which are required to accessundo information to provide for consistent reads and transactionconsistency. If the rollback segment iscorrupted, the transaction consistency of the data blocks (including datadictionary objects) can be jeopardized.

The corruption found when undoing atransaction could fall under three categories :
在以下三种情况下,可以会出现corruption:
(1)belongs to the object (table/index/cluster) that has the data onwhich the transaction was executed (data block)
(2)belongs to the undo block that is being used to undo the transaction(undo header)
(3)belongs to the undo segment header block of the segment where theundo block is found (undo block)
对于第一种情况,出现corruption 的位置是data block。
Thefirst case where the corruption is in the object to which the activetransaction belongs to, we have to identify the object first. This can be done by setting an event in theINIT.ORA as follows:
event= “10015 trace name context forever, level 10”
这种情况的坏块是active transaction,当我们重启DB后,会进行相关的transaction recover(Rolling Back)。 当recover 完成,就可以正常访问对应的block了。 相关文章参考:
http://blog.csdn.net/tianlesoftware/article/details/6547891
Oracle 实例恢复时 前滚(roll forward) 后滚(rollback) 问题
http://blog.csdn.net/tianlesoftware/article/details/6286330
Thisevent traces the undo segment recovery when the database is started, the eventputs out a trace in the directory specified by the INIT.ORA parameter,USER_DUMP_DEST. This trace file containsa transaction table for each of the rollback segments that are onlined in thedatabase. The trace file has a messagethat says ‘error recovering tx(#, #) object #’. Tx(#, #) refers to thetransaction information and the object # is the object id of the object thathas a corruption.
设置event时候,会dump DB 启动是的undo segment recovery,在trace里会有‘error recovering tx(#, #) object#’信息,其中Tx(#, #)指的是事务信息,object #是corruption 的对象id。找到对象ID 后可以通过如下SQL查询:
The following query gives the name of theobject that is corrupted:
SQL>SELECTOWNER, OBJECT_NAME, OBJECT_TYPE, STATUS FROM SYS.DBA_OBJECTS WHERE OBJECT_ID = <object #_from_tracefile>;
对于第二种情况和第三种情况的处理,参考我的blog:
Current online Redo 和 Undo 损坏的处理方法
http://blog.csdn.net/tianlesoftware/article/details/6261475
4.3.5 Sort blocks (TEMP tablespace)
Sortsare usually done in the part of memory allocated from the SGA. This is defined by the INIT.ORA parameterSORT_AREA_SIZE. If the sort space neededfor a sort is so big that it cannot fit in the sort area defined in memory,then it is done on disk by creating segments called the Temporary segments.
当SORT_AREA_SIZE 指定的sort 空间不够时,会在磁盘上创建一个temporary segments来作为排序使用。 建议每个用户指定自己的temporary tablespace。
Itis advisable to create a separate tablespace called the TEMP tablespace. After creating this tablespace, alter theusers to use this as their temporary tablespace by executing the followingcommand:
ALTERUSER user_name TEMPORARY TABLESPACE TEMP;
This way, the temporary segments created by any user will be in the TEMP tablespaceand it provides easy manageability.
Detection
· Usually thissegment is never corrupted since they are reformatted every time they get used
Repair
· Tempsegments are reused frequently
· If problempersists, either move or drop and recreate the temp tablespace
4.3.6 Data/Index blocks (DATA/INDEX tablespace)
Whena data block is corrupted, when it belongs to a table segment, cluster segmentor an index segment, the detection mechanisms are the same:
datablock的corrupt可以出现在table segment,cluster segment和index segment。
可以通过以下方法来检测corruption:
(1)DBVERIFY can be used to detect the corrupted blocks in thedata file
(2)ANALYZE command run on the objects give errors (ANALYZE<table/cluster/index> <table/cluster/index_name> VALIDATESTRUCTURE;) When an ANALYZE (with CASCADE option) is run on a table or cluster,it cross verifies the index and data/cluster blocks along with the integritychecks done for the block.
(3)DB_BLOCK_CHECKSUM can be set to TRUE in the INIT.ORA file.When a block is changed and being written to disk from memory, DBWR calculatesa checksum for the block by summing up its contents and writes it in the blockalong with it on disk. The next time when the block is being read by theforeground process, it calculates the checksum again for the block that isbeing read and compared with the checksum already written in the block ondisk. If both are different then theblock has been corrupted on disk and so the block is not read into memory sothat it prevents cache corruption. There is an overhead associated with this parameter since thechecksum is calculated each time it is read and written.
(4)Events 10210, 10211, 10212 can be set in the INIT.ORA file todetect software corrupt blocks. When there is a corruption in a block, it is not detecteduntil the block is being updated. So any SELECTs on a corrupted block is executed until it is marked assoftware corrupt. When the events areset in the INIT.ORA, the blocks are checked for integrity by comparing certaindata structures and once there is an inconsistency found, the seq or the sequence of the block is set to 0 in theblock header representing that the block is software corrupt.
The events can be set as follows:
event= “10210 trace name context forever, level 10” (for data blocks)
event= “10211 trace name context forever, level 10” (for index blocks)
event= “10212 trace name context forever, level 10” (for cluster blocks)
(5)Users receiving ORA-1578 when trying to access an object. The query from DBA_EXTENTS given in pg# 30shows that the error is on a table, cluster or index in the data tablespace,SQL语句如下:
SQL>selectsegment_type, segment_name from sys.dba_extents where file_id =<file_id_from_ora-1578> and <block_id_from_ora-1578> betweenblock_id and (block_id+blocks-1);
(6)ALERT.LOG shows ORA-1578 or ORA-600s with the first argument in therange of 2000 to 8000
4.3.6.1 Tables
Whena data block is corrupted in a table, it should be understood that the data inthe corrupted block is lost. The onlyway to not lose any data from the table is to restore from a valid backup andrecover until a point in time before the corruption occurred.
datablock 坏块通常意味着数据的丢失,如果要保证没有数据丢失,需要通过有效的备份进行恢复。这块参考1.4节。
方法一:Event method
Event10231 can be set to skip corrupted blocks on full table scans in the INIT.ORAfile. The object can be exported aftersetting this event. This is notguaranteed to work for every kind of corruption.
This works only when the block is soft corrupted(逻辑坏块), sequence is set to 0. The event can be set as follows:
event= “10231 trace name context forever, level 10”
对于table上的逻辑坏块,并且sequence 设置为0,可以设置10231 event,当全表扫描时,可以跳过corruption,从而读取数据。
方法二:ROWID method
Extractthe data that does not belong to the corrupted block using ROWIDs. Every row inevery table in an Oracle database has a ROWID column which is usually not displayedunless SELECTed explicitly.
通过rowid,我们可以抽取出非corrupted block上的数据。关于ROWID的更多内容,参考我的Blog:
http://blog.csdn.net/tianlesoftware/article/details/5020718
(1)通过函数构建ROWID
函数参数如下:
function ROWID_CREATE(rowid_type IN number,
object_number INnumber,
relative_fno IN number,
block_number IN number,
row_number IN number)
return ROWID;
-- rowid_type - type(restricted=0/extended=1)
-- object_number - data objectnumber
-- relative_fno - relative filenumber
-- block_number - block numberin this file
-- row_number - row number inthis block
这些参数可以通过如下方式获取:
ROWID_TYPE:
Thisis 1 because we are using the extended rowid format.
RELATIVE_FNO:
Thisshould have been available when you came to this article. It can also be foundfrom the DBA_EXTENTS view given the absolute file number and block number ofthe corrupt block:
SQL>SELECTtablespace_name, relative_fno, segment_type, owner, segment_name, partition_nameFROM dba_extents WHERE file_id = <AFN> AND <BL> between block_id and block_id + blocks-1;
OBJECT_NUMBER:
For a non-partitioned table, select the DATA_OBJECT_ID from DBA_OBJECTS for theproblem table:
SQL>SELECT data_object_id FROM dba_objectsWHERE object_name = '<TABLE-NAME>' AND owner = '<TABLE-OWNER>' ;
Note that a partitionedtable has an object number for each partition.
--注意,对于分区表,每个分区有一个对象id:
Select the DATA_OBJECT_ID from DBA_OBJECTSthus:
SQL>SELECTdata_object_id FROM dba_objects WHERE object_name = '<TABLE-NAME>' ANDowner = '<TABLE-OWNER>' AND subobject_name = '<PARTITION-NAME>' ;
相对与普通表,普通表多了一个subojbect_name 条件。
BLOCK_NUMBER andROW_NUMBER:
Theblock number of the corrupt block should be available before you came to thisarticle. (Eg: It is reported in an ORA-1578 error, or as a Page Number byDBVerify).
Fora ROWID range scan we generally want to select all rows BEFORE the corruptblock, then all rows AFTER the corrupt block. The first row in a block is rowzero (0) and so we want all rowids LESS THAN "Block <BL> row 0"and then GREATER THAN OR EQUAL TO "Block <BL>+1 row 0".
(2)创建ROWID
You can now create the rowid strings to use in a predicate thus:
现在可以创建rowid:
The "LOW_RID"is the lowest rowid INSIDE the corrupt block:
SQL>SELECT dbms_rowid.rowid_create(1,<DATA_OBJECT_ID>,<RFN>,<BL>,0)LOW_RID from DUAL;
The "HI_RID" isthe first rowid AFTER the corrupt block:
SQL>SELECT dbms_rowid.rowid_create(1,<DATA_OBJECT_ID>,<RFN>,<BL>+1,0)HI_RID from DUAL;
(3)重建数据
Itis now possible to use CREATE TABLE AS SELECT or INSERT ... SELECT to get datawithout accessing the corrupt block using a query of the form:
根据刚才查询的rowid,跳过corrupt block来进行createtable 或者insert 操作:
SQL>CREATE TABLE salvage_table AS SELECT/*+ ROWID(A) */ * FROM <owner.tablename> A WHERE rowid <'<low_rid>' ;
SQL>INSERT INTO salvage_table SELECT /*+ROWID(A) */ * FROM <owner.tablename> A WHERE rowid >='<hi_rid>';
注意hint里的A是表的别名。
Fora table partition then only the problem partition need be selected from byusing the PARTITION(xxx) option in the FROM clause:
对于分区表,仅需要对问题分区进行处理:
SQL>CREATE TABLE salvage_table AS SELECT/*+ ROWID(A) */ * FROM <owner.tablename> PARTITION(<partition_name>) A WHERE rowid < '<lo_rid>';
SQL>INSERT INTO salvage_table SELECT /*+ROWID(A) */ * FROM <owner.tablename> PARTITION (<partition_name>) AWHERE rowid >= '<hi_rid>';
注意: 采用上面这种rowid的方法,不能处理含有LONG字段的表,对于LONG字段的表,只能使用带有where 条件的export/import.
If the corrupt block is the table segment header, this method won't work. You stillhave the option of using any indexes on the corrupt table to extract the data.
如果是块头出现corrupt,那么这个方法不使用。 当块头出现问题,整个块的data 都不可读取。 如果是非块头,我们可以使用这种方法挽回更多的数据。
Use the following query to determine if the affected block is thesegment header :
可以使用如下SQL判断是否是块头block:
SQL>selectfile_id,block_id,blocks,extent_id from dba_extents where owner='<owner>'and segment_name='<table_name>' and segment_type='TABLE' order by extent_id;
FILE_ID BLOCK_ID BLOCKS EXTENT_ID
--------- --------- --------- ---------
8 94854 20780 0 <- EXTENT_IDZERO is segment header
方法三: Index method
If there are any indexes on the corrupt table then it is possible to get someinformation about what data was in the corrupt block from the index. Thisrequires selecting indexed columns from the table for rowids in the corruptblock. We already know the ROWID range covered by the corrupt block from theSELECT dbms_rowid.rowid_create ... statements above.
To extract the column data use one of the following forms of select statement:
If the columns requiredat NOT NULLable you can use a fast full scan:
如果列是非空的,可是使用fast full scan:
SQL>SELECT/*+ INDEX_FFS(X <index_name>) */ <index_column1>,<index_column2> ... FROM<tablename> X WHERE rowid >= '<low_rid>' AND rowid < '<hi_rid>' ;
If the columns required are NULLable thenyou cannot use an index fast full scan and must use a range scan. This requiresyou to know a minimum possible value for the leading index column to ensure youenable the index scan:
如果列是可以null的,那么必须使用range scan:
SQL>SELECT /*+ INDEX(X<index_name>) */ <index_column1>, <index_column2> ... FROM <tablename> X WHERE rowid >= '<low_rid>' ANDrowid < '<hi_rid>' AND <index_column1> >=<min_col1_value>;
Using this technique for all indexes on the table may be able to retrieve some of thedata. See <View:DBA_IND_COLUMNS> for which columns make up each index.
关于第二和第三中方法,MOS上有示例:
ExtractingData from a Corrupt Table using ROWID Range Scans in Oracle8 and higher [ID61685.1]
4.3.6.2 Clusters
Clusters can be defined as a way to store more than one tables physically together sincethe tables have some common columns. Bystoring the related rows from multiple tables together, the access time can bereduced.
For example, if a cluster is formed with the EMP and DEPT tables, the cluster blocklooks like:
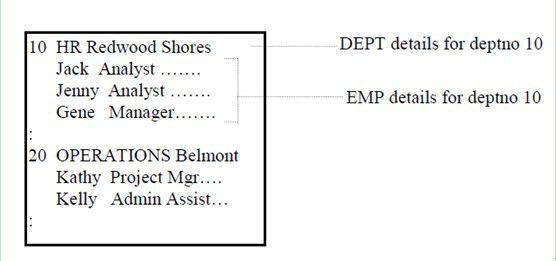
A query that runs across EMP and DEPT will have to access just one block to getboth tables’ rows. The IO is less andthe access time is less too.
The detection and repair for a cluster block corruption is similar to that of atable block corruption but the only difference is that when there is acorruption in a cluster block, all the objects that make up the cluster has tobe fixed.
4.3.6.3 indexes
Detection
·(1) DBVERIFY gives the corrupted blockinformation
·(2)ALERT.LOG shows corruption errors
·(3)Users running queries against theindex get ORA-1578 on the index
·(4)ORA-600 with first argument in the rangebetween 2000 and 8000
Repair
·(1) Drop and recreate the indexsegment
·(2)Restore from a valid backup and recover
索引上的corrupt block 是比较好处理的,因为可以对索引进行重建,所以不会造成data lose。
五. dbms_repair 包与坏块
Oracle从8i 开始提供了DBMS_REPAIR包,该包可以用来发现、标识并修改数据文件中的坏块。dbms_repair包没有进行授权,只有sys用户可以执行。
任何工具都不是万能的,使用这个包的同时会带来数据丢失、表和索引返回数据不一致,完整性约束破坏等其他问题。因此当出现错误时,应当首先从物理备份或逻辑备份恢复,使用dbms_repair只是在没有备份的情况下使用的一种手段,这种方式一般都会造成数据的丢失。
dbms_repair包的工作原理比较简单,是将检查到的坏块标注出来,使随后的dml操作跳过该块,同时,dbms_repair包还提供了用于保存索引中包含的标注为坏块中的键值,以及修复freelist和segment bitmap的过程。
官网的说明:
DBMS_REPAIR Examples
http://download.oracle.com/docs/cd/B28359_01/server.111/b28310/repair004.htm#ADMIN11828
Using the DBMS_REPAIR Package
http://download.oracle.com/docs/cd/B28359_01/server.111/b28310/repair003.htm#ADMIN11815
yangtingkun的blog:
DBMS_REPAIR的使用
http://yangtingkun.itpub.net/post/468/9121
5.1 准备工作
create tablespace block datafile '/u01/block.dbf' size 5M;
create table DMM tablespace block as select * from all_tables;
commit;
CREATE INDEX indx_dmm on DMM(TABLE_NAME);
select count(*) from DMM;
COUNT(*)
----------
12896
5.2.创建管理表
SQL> conn sys/admin as sysdba;
已连接。
SQL> execDBMS_REPAIR.ADMIN_TABLES('REPAIR_TABLE',1,1,'USERS');
PL/SQL procedure successfully completed
SQL> execDBMS_REPAIR.ADMIN_TABLES('ORPHAN_TABLE',2,1,'USERS');
PL/SQL procedure successfully completed
5.3 检查坏块:dbms_repair.check_object
Set serveroutput on;
DECLARE
cc NUMBER;
BEGIN
DBMS_REPAIR.check_object (schema_name => 'SYS', -- 注意此处是用户名
object_name => 'DMM',
corrupt_count => cc);
DBMS_OUTPUT.put_line ( TO_CHAR (cc));
END;
正常情况下输入为0。 如果有坏块,可以在创建的REPAIR_TABLE中查看块损坏信息:
/* Formatted on 2009-12-17 13:18:19 (QP5v5.115.810.9015) */
SELECT object_name,
relative_file_id,
block_id,
marked_corrupt,
corrupt_description,
repair_description,
CHECK_TIMESTAMP
FROM repair_table;
注意:在8i下,check_object只会检查坏块,MARKED_CORRUPT为false,故需要进行 定位坏块(fix_corrupt_blocks) ,修改MARKED_CORRUPT为true,同时更新CHECK_TIMESTAMP。
9i以后经过check_object,MARKED_CORRUPT的值已经标识为TRUE了。所以可以直接进行第四步了。
5.4 .定位坏块:dbms_repair.fix_corrupt_blocks
只有将坏块信息写入定义的REPAIR_TABLE后,才能定位坏块。
/* Formatted on 2009-12-17 13:29:01 (QP5v5.115.810.9015) */
DECLARE
cc NUMBER;
BEGIN
DBMS_REPAIR.fix_corrupt_blocks (schema_name => 'SYS',
object_name => 'DMM',
fix_count => cc);
DBMS_OUTPUT.put_line (a => TO_CHAR (cc));
END;
5.5 .跳过坏块
我们前面虽然定位了坏块,但是,如果我们访问table:
SQL> select count(*) from SYS.DMM;
ORA-01578: ORACLE 数据块损坏(文件号14,块号154)
ORA-01110: 数据文件 14: 'D: /BLOCK.DBF'
还是会得到错误信息。 这里需要用skip_corrupt_blocks来跳过坏块:
/* Formatted on 2009-12-17 13:30:17 (QP5v5.115.810.9015) */
exec dbms_repair.skip_corrupt_blocks(schema_name => 'SYS',object_name => 'DMM',flags => 1);
SQL> select count(*) from SYS.DMM;
COUNT(*)
----------
12850
丢失了12896-12850=46行数据。
5.6.处理index上的无效键值;dump_orphan_keys
/* Formatted on 2009-12-17 13:34:55(QP5 v5.115.810.9015) */
DECLARE
cc NUMBER;
BEGIN
DBMS_REPAIR.dump_orphan_keys (schema_name => 'SYS',
object_name => 'INDX_DMM',
object_type => 2,
repair_table_name => 'REPAIR_TABLE',
orphan_table_name => 'ORPHAN_TABLE',
key_count => CC);
END;
通过以下命令可以知道丢失行的信息:
SQL> SELECT * FROM ORPHAN_TABLE;
我们根据这个结果来考虑是否需要rebuild index.
5.7重建freelist:rebuild_freelists
/* Formatted on 2009-12-17 13:37:57(QP5 v5.115.810.9015) */
exec dbms_repair.rebuild_freelists(schema_name => 'SYS',object_name => 'DMM');