(4) PIVOT 和 UPIVOT 的使用
最近项目中用到了行转列,使用SQL SERVER 提供的PIVOT实现起来非常容易。
官方解释:详见这里
可以使用 PIVOT 和 UNPIVOT 关系运算符将表值表达式更改为另一个表。
PIVOT 通过将表达式某一列中的唯一值转换为输出中的多个列来旋转表值表达式,并在必要时对最终输出中所需的任何其余列值执行聚合。UNPIVOT 与 PIVOT 执行相反的操作,将表值表达式的列转换为列值。
其实PIVOT 就是行转列,UNPIVOT就是列转行。
PIVOT 的完整语法为:
SELECT <非透视的列>,
[第一个透视的列] AS <列名称>,
[第二个透视的列] AS <列名称>,
...
[最后一个透视的列] AS <列名称>,
FROM
(<生成数据的 SELECT 查询>)
AS <源查询的别名>
PIVOT
(
<聚合函数>(<要聚合的列>)
FOR
[<包含要成为列标题的值的列>]
IN ( [第一个透视的列], [第二个透视的列],
... [最后一个透视的列])
) AS <透视表的别名>
<可选的 ORDER BY 子句>;
UNPIVOT的完整语法相对简单一些为:
SELECT <其他列>,<虚拟列别名>,<列值别名>
UNPIVOT(
<列值别名>
FOR <虚拟列别名>
IN(<第一个真实列>,<第二个真实列>....)
) AS <表别名>
我们来看一个简单PIVOT的例子,项目有如下要求:根据用户输入的查询月份,统计所有设备房间此月的告警次数,界面报表要求如下格式:
| 设备房间 | 告警A次数 | 告警B次数 | 告警C次数 |
| XXX | 10 | 1 | 2 |
| ZZZ | 1 | 0 | 5 |
例如:数据库中有如下表和数据:
--机房表 create table t_DevRoom ( RoomId int identity(1,1), RoomName nvarchar(50), constraint [Pk_DevRoom_RoomId] primary key clustered(RoomId), constraint [Uq_DevRoom_RoomName] unique (RoomName) ) go --告警类型 create table t_AlarmType ( TypeId int, TypeName nvarchar(20) not null, constraint [Pk_AlarmType_TypeId] primary key clustered(TypeId), constraint [Uq_AlarmType_TypeName] unique (TypeName) ) go --告警表 create table t_Alarm ( AlarmId int identity(1,1), RoomId int not null, AlarmType int not null, AlarmDt datetime not null, constraint [Pk_Alarm_AlarmId] primary key clustered(AlarmId), constraint [Fk_Alarm_RoomId] foreign key (RoomId) references t_DevRoom(RoomId) on delete cascade, constraint [Fk_Alarm_AlarmType] foreign key (AlarmType) references t_AlarmType(TypeId) on delete cascade ) go insert into t_DevRoom values ('机房A') insert into t_DevRoom values ('机房B') insert into t_DevRoom values ('机房C') insert into t_AlarmType values (1,'空调告警') insert into t_AlarmType values (2,'烟雾告警') insert into t_AlarmType values (3,'设备告警') insert into t_Alarm values(1,1,'2013-01-01') insert into t_Alarm values(1,1,'2013-01-02') insert into t_Alarm values(1,2,'2013-01-02') insert into t_Alarm values(1,3,'2013-01-03') insert into t_Alarm values(1,3,'2013-01-04') insert into t_Alarm values(2,2,'2013-01-01') insert into t_Alarm values(2,2,'2013-01-02') insert into t_Alarm values(2,3,'2013-01-02') insert into t_Alarm values(2,3,'2013-01-03') insert into t_Alarm values(2,3,'2013-01-04')
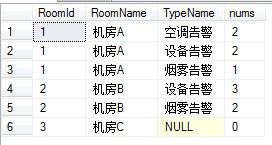
有了上面的临时数据,我们可以查询一下2013年1月份所有机房的告警次数:
select R.RoomId,R.RoomName,count(A.AlarmType) as nums,T.TypeName from t_DevRoom as R left join t_Alarm as A on R.RoomId=A.RoomId left join t_AlarmType AS T on A.AlarmType=T.TypeId WHERE datepart(year,A.AlarmDt)=2013 AND datepart(month,A.AlarmDt)=1 or A.AlarmDt is null group by R.RoomId,R.RoomName,T.TypeName order by RoomId
结果如下:
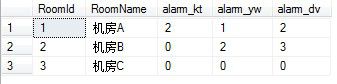
我们来把这个结果集PIVOT一下,以符合我们的界面要求,我们根据语法格式进行这样修改:
select RoomId,RoomName, alarm_kt=isnull([空调告警],0), alarm_yw=isnull([烟雾告警],0), alarm_dv=isnull([设备告警],0) from ( select R.RoomId,R.RoomName,T.TypeName,count(A.AlarmType) as nums from t_DevRoom as R left join t_Alarm as A on R.RoomId=A.RoomId left join t_AlarmType AS T on A.AlarmType=T.TypeId WHERE datepart(year,A.AlarmDt)=2013 AND datepart(month,A.AlarmDt)=1 or A.AlarmDt is null group by R.RoomId,R.RoomName,T.TypeName ) as temp pivot ( min(nums) for TypeName IN([空调告警],[烟雾告警],[设备告警]) ) as temp2 order by RoomId
查询结果如下:
至于 UNPIVOT 与PIVOT正好相反,也来看个例子,此例子来自于网上:
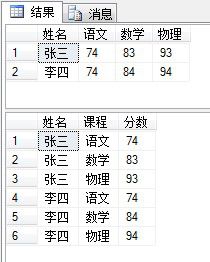
create table t_score ( 姓名 varchar(10), 语文 int, 数学 int, 物理 int ) go insert into t_score values('张三',74,83,93) insert into t_score values('李四',74,84,94) select * from t_score
select 姓名,课程,分数 from t_score unpivot ( 分数 for 课程 in([语文],[数学],[物理]) ) as t go
执行结果如下: