HashedWheelTimer 原理
HashedWheelTimer 是根据
Hashed and Hierarchical Timing Wheels: Data Structures
for the Efficient Implementation of a Timer Facility
这篇论文做出来的.
HashedWheelTimer 主要用来高效处理大量定时任务, 他的原理如图
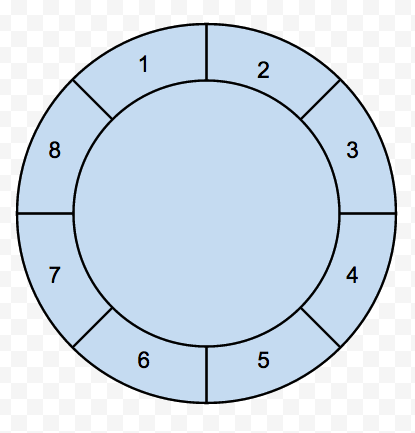
可以将 HashedWheelTimer 理解为一个 Set<Task>[] 数组, 图中每个槽位(slot)表示一个 Set<Task>
HashedWheelTimer 有两个重要参数
tickDuration: 每 tick 一次的时间间隔, 每 tick 一次就会到达下一个槽位
ticksPerWheel: 轮中的 slot 数
上图就是一个 ticksPerWheel = 8 的时间轮, 假如说 tickDuration = 100 ms, 则 800ms 可以走完一圈
在 timer.start() 以后, 便开始 tick, 每 tick 一次, timer 会将记录总的 tick 次数 ticks
我们加入一个新的超时任务时, 会根据超时的任务的超时时间与时间轮开始时间算出来它应该在的槽位.
例如 timer.newTask(new Task(10, TimeUnit.SECONDS));
表示加入一个 10s 后超时的任务, 那么, 先计算他应该在的槽位
// deadline = 当前时间 + 任务延迟 - timer启动时间 = timer启动到任务结束的时间 long deadline = System.currentTime() + timeout - timerStartTime; // calculated = tick 次数 long calculated = deadline / tickDuration; // tick 目前已经 tick 过的次数 final long ticks = Math.max(calculated, tick); // Ensure we don't schedule for past. // 算出任务应该插入的 wheel 的 slot, slotIndex = tick 次数 & mask, mask = wheel.length - 1, 默认即为 511 stopIndex = (int) (ticks & mask); // 计算剩余的轮数, 只有 timer 走够轮数, 并且到达了 task 所在的 slot, task 才会过期 remainingRounds = (calculated - tick) / wheel.length;
其中 stopIndex 为它所在的槽位
remainingRounds 为它从 timer 启动时应该经过的轮数
当 timer tick 到 task 所在的槽位, 并且这个槽位的 remainingRounds <= 0 , 则说明这个 task 超时, 然后执行超时任务, 否则 remainingRounds--
------------------------------------------------------
为什么要使用时间轮的环形结构? 因为环形结构可以根据超时时间的 hash 值(这个 hash 值实际上就是ticks & mask)将 task 分布到不同的槽位中, 当 tick 到那个槽位时, 只需要遍历那个槽位的 task 即可知道哪些任务会超时(而使用线性结构, 你每次 tick 都需要遍历所有 task), 所以, 我们任务量大的时候, 相应的增加 wheel 的 ticksPerWheel 值, 可以减少 tick 时遍历任务的个数.
详细代码参考 Netty 的实现: https://github.com/netty/netty/blob/master/common/src/main/java/io/netty/util/HashedWheelTimer.java