hbase 学习(十六)系统架构图
HBase 系统架构图
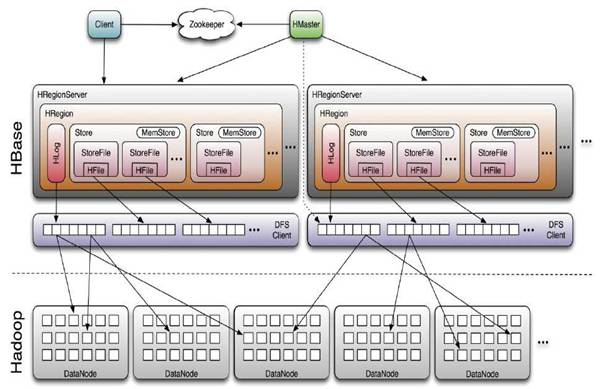
组成部件说明
Client:
使用HBase RPC机制与HMaster和HRegionServer进行通信
Client与HMaster进行通信进行管理类操作
Client与HRegionServer进行数据读写类操作
Zookeeper:
Zookeeper Quorum存储-ROOT-表地址、HMaster地址
HRegionServer把自己以Ephedral方式注册到Zookeeper中,HMaster随时感知各个HRegionServer的健康状况
Zookeeper避免HMaster单点问题
HMaster:
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master在运行
主要负责Table和Region的管理工作:
1 管理用户对表的增删改查操作
2 管理HRegionServer的负载均衡,调整Region分布
3 Region Split后,负责新Region的分布
4 在HRegionServer停机后,负责失效HRegionServer上Region迁移
HRegionServer:
HBase中最核心的模块,主要负责响应用户I/O请求,向HDFS文件系统中读写数据
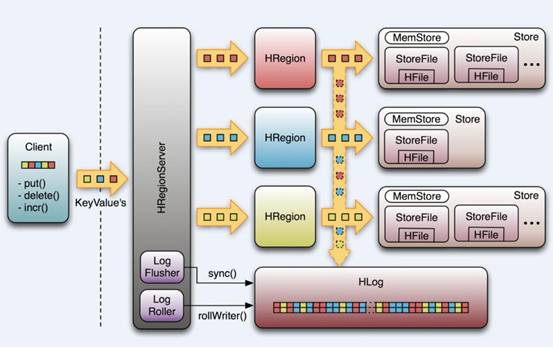
HRegionServer管理一些列HRegion对象;
每个HRegion对应Table中一个Region,HRegion由多个HStore组成;
每个HStore对应Table中一个Column Family的存储;
Column Family就是一个集中的存储单元,故将具有相同IO特性的Column放在一个Column Family会更高效
HStore:
HBase存储的核心。由MemStore和StoreFile组成。
MemStore是Sorted Memory Buffer。用户写入数据的流程:
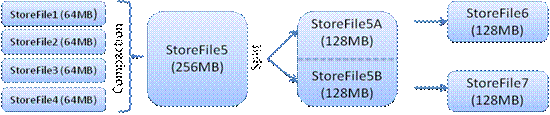
Client写入 -> 存入MemStore,一直到MemStore满 -> Flush成一个StoreFile,直至增长到一定阈值 -> 触发Compact合并操作 -> 多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除 -> 当StoreFiles Compact后,逐步形成越来越大的StoreFile -> 单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个Region,Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。
由此过程可知,HBase只是增加数据,有所得更新和删除操作,都是在Compact阶段做的,所以,用户写操作只需要进入到内存即可立即返回,从而保证I/O高性能。
HLog
引入HLog原因:
在分布式系统环境中,无法避免系统出错或者宕机,一旦HRegionServer意外退出,MemStore中的内存数据就会丢失,引入HLog就是防止这种情况
工作机制:
每个HRegionServer中都会有一个HLog对象,HLog是一个实现Write Ahead Log的类,每次用户操作写入Memstore的同时,也会写一份数据到HLog文件,HLog文件定期会滚动出新,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知,HMaster首先处理遗留的HLog文件,将不同region的log数据拆分,分别放到相应region目录下,然后再将失效的region重新分配,领取到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
HBase存储格式
HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,格式主要有两种:
1 HFile HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile
2 HLog File,HBase中WAL(Write Ahead Log) 的存储格式,物理上是Hadoop的Sequence File
HFile
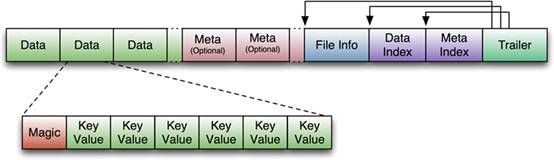
图片解释:
HFile文件不定长,长度固定的块只有两个:Trailer和FileInfo
Trailer中指针指向其他数据块的起始点
File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等
Data Index和Meta Index块记录了每个Data块和Meta块的起始点
Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制
每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询
每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏
HFile里面的每个KeyValue对就是一个简单的byte数组。这个byte数组里面包含了很多项,并且有固定的结构。

KeyLength和ValueLength:两个固定的长度,分别代表Key和Value的长度
Key部分:Row Length是固定长度的数值,表示RowKey的长度,Row 就是RowKey
Column Family Length是固定长度的数值,表示Family的长度
接着就是Column Family,再接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)
Value部分没有这么复杂的结构,就是纯粹的二进制数据
HLog File
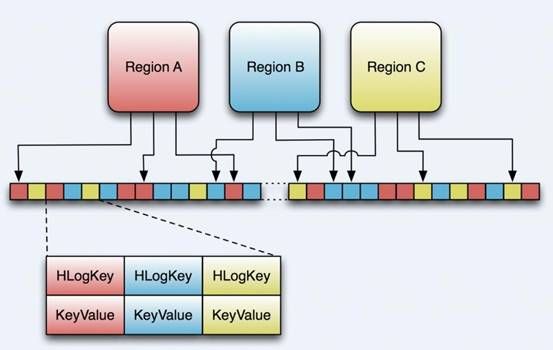
HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是“写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue
结束语:这篇文章是我专门在网上弄下来的,算是hbase部分的终极篇吧,我的服务端的源码系列也要基于这个顺序来开展。