前言
相信每一个技术人员都有周期性获取技术资讯的诉求,而获取的方式也多种多样。例如,用资讯类APP,进行RSS订阅,参加行业大会,深入技术社区,订阅期刊杂志、公众号,等等,都是可选的方式。这些方式看到信息的成本都很低,有“开箱即得”的感觉。但缺点也很明显,有点像“大班课”,可以满足一类人的需求,但难较好地满足每个参与者的个性化诉求。通过这些方式,要想真正拿到自己所需要的信息的成本并不低(虽然智能推荐在往满足个性化诉求方面迭代,但离期待仍有较大的差距)。对于个性化诉求,最简单的方式就是你感兴趣哪方面的内容就去逐一主动检索或者浏览,但这种方式的成本显然太高。
核心的问题是,上面的两大类路径,都不是很懂你(了解你的意图和诉求)。而你需要一个既懂你,成本又不是太高的方式。
一、对于技术资讯获取DIY的框架性思考
相信在当前相当一段时期内,最适合的个性化资讯获取方式仍然是工具+人工相组合的方式。相比纯工具的算法推荐,一些付费资讯渠道已经在(智能)工具的基础上,对信息进行了人工的筛选、加工处理,质量会更好。如果你是程序员,自己编写一些小爬虫,在其中注入自己的喜好与智慧,不失为一种懂你且成本不高的方式。而且通过这种方式,你将获得很好的自我掌控感。本文中,笔者就着重介绍这种方式。值得提醒的是,本文所涉内容,仅为学习讨论技术,切勿用作非法用途。
具体来说,分为四部分(如图1.1所示):

图1.1
第一,自己控制消息来源
你可以根据自己的经验积累,在合法合规的前提下来选取消息来源。这个选择的维度可以很多样,包括质量可靠性、信息的前瞻性、兴趣匹配度、研究方向匹配度、信息生产频率、信息的新颖度,等等。
第二,自己编写采集和筛选算法
选定了一些采集渠道,你就可以自己编写采集和筛选算法了。采集周期、筛选规则、所需内容项,等等,都可以自己控制。如果你对数据处理、人工智能等很了解,相信还有更多的发挥空间。
第三,自己控制阅读和交互体验
由于阅读是一个长期的过程,对于优质的体验其实有着很强的需求。难受的阅读体验是非常不利于信息的快速获取的,甚至会打消获取信息的兴趣。比如,下面这两张图,图1.2左边是某头条的资讯界面,右边是微信读书的阅读界面。

图1.2
相形之下,作为阅读者,我个人更喜欢微信阅读的简洁,而不太喜欢某头条那些次要元素的干扰。
第四,自己控制迭代优化
自己既是消费者也一定程度是信息流通控制者的好处就是:自己可以站在结果环节对信息获取全流程进行自主评价,回溯作用到前面的环节,从而形成正向作用闭环。
这么做有什么收益呢?
首先,是获得有价值的信息。
这一点无需多言。
其次,有助于信息获取能力的提升。
就拿技术人员来说,这么做可以更高效地、持续地获取满足个性化诉求的高价值信息,在对外部技术世界持续保持关注中获得持续性地成长与提升。
1)关于信息来源:你将自己总结出一份最有价值的信息的来源渠道列表,提高信息的获取效率,能以较快的速度接触到相对可靠的信息。
2)关于信息处理:你将沉淀出自己的一份或简单或复杂的信息采集和筛选算法,提升信息的鉴别能力,增强信息处理的能力。
3)关于信息体验:你将获得适合你自己的信息获取、阅读、交互体验,增强阅读兴趣和减少疲劳。
第三,有助于进行技术探索,提升技术应用能力。
在这个过程中,实际上也是自己在运用技术解决实际问题的探索过程,可以作为技术甚至产品建构探索的实验田。比如说,Flutter这一技术有很多公司在进行尝试和应用,但是你所做的项目暂时还是用的Electron做的,目前并没有迁移到Flutter的打算。那么如果你对Flutter感兴趣的话,完全可以把采集到的技术资讯尝试用Flutter做成一个APP,先试水一下怎么用(只是举个“栗子”,如果你恰好真感兴趣的话,后面有彩蛋一枚,继续往下看准能找到)。这样就相当于是先期业余做了一些储备和实践。
二、对于技术资讯获取DIY的实践探索
上面啰嗦了这么多,还是讲点实在的吧。咱们来真实地爬取点技术资讯。要抓取的内容存在形式是多种多样的,有的被内容服务端直接渲染到了HTML页面上,有的则是在页面中通过JavaScript请求数据,然后再渲染出来的。
首先来看第一种。
1、HTML页面中内容的抓取
第一步,信息来源的选择。
要不我们就比较有代表性的互联网公司BAT里随便找一家吧,看看他们都有些什么高价值的技术资讯。不如就选那个比较高调(非常乐于向业界分享自己技术)的阿里巴巴,因为高调的可能比较好找。他们有个云栖社区,里面有个栏目叫阿里技术(https://yq.aliyun.com/articles/721143),这是一个一直在有规律更新,而且文章质量不错的栏目,界面如下所示。

图2.1
第二步,信息的采集和筛选。
假设我们准备爬取最近一周阿里技术这个栏目下都有些什么新的文章发布。我们主要获取其标题、文章链接地址、发布时间和文章简介,希望只抓取最近7天内发布的文章。即期望爬取出来的结果如图2.2所示。
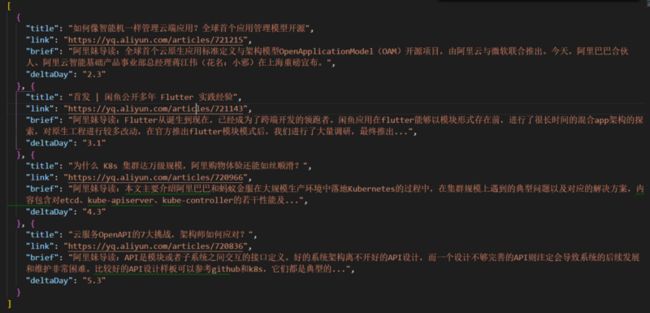 图2.2
图2.2
目标清楚了,下一步就是怎么实现,笔者选择使用Node.js。这里需要介绍用到的两个工具:request-promise(https://www.npmjs.com/package/request-promise)和cheerio(https://www.npmjs.com/package/cheerio)。所以首先你需要用 yarn init 命令创建一个项目,再用 yarn add request request-promise cheerio 命令安装上这几个依赖模块。
关于request-promise,官方介绍是:
The simplified HTTP request client 'request' with Promise support. Powered by Bluebird.
通过request-promise,可以很轻易地抓到页面的HTML,如下所示:
const rp = require('request-promise');
rp(' // 略去了地址
.then(function (htmlString) {
// Process html...
})
.catch(function (err) {
// Crawling failed...
});
抓到HTML后,我们还是希望对其进行处理,把其中的我们所需要的标题、文章链接地址和文章简介等信息提取出来。这时需要用到另一个工具——cheerio。用它与request-promise结合,可以让对于抓取到的HTML的处理基本上像用jQuery那样进行。因为cheerio实现了jQuery的核心子集。两者结合后的用法如下:
`const rp = require('request-promise');
const cheerio = require('cheerio');
const targetURL = ' // 略去了地址
const options = {
uri: targetURL,
transform: (body) => {
return cheerio.load(body);
}
};
function getArticles() {
rp(options)
.then(($) => {
// Process html like you would with jQuery...
console.log($('title').text());
})
.catch((err) => {
// Crawling failed or Cheerio choked...
});
}
// 入口
getArticles();
`
上面代码中,
console.log($('title').text())
会log出来页面title标签内部的文字,就像使用jQuery操作页面DOM一样。
接着我们就可以用Chrome打开阿里技术(https://yq.aliyun.com/articles/721143)页面,借助Chrome DevTools轻而易举找到文章的标题所对应的HTML元素(如图2.3所示)。进而通过将上述代码中的
console.log($('title').text())
这一行替换为:
console.log console.log($('.yq-new-item h3 a').eq(1).text())($('.yq-new-item h3 a').eq(1).text())
从而log出来其中一篇技术资讯文章的标题。

图2.3
举一反三,用同样的方法可以获取到文章链接地址和文章简介。但是,我们还想获取到每篇文章的发布时间,但是当前页面中并没有,怎么办呢?点进去每篇文章的链接,我们发现文章内部是有这个信息的(如图2.4)。于是,实现思路就有了。每抓取到一篇文章的链接之后,再针对抓到的链接地址再进行一次抓取,把该篇文章中的发布时间也抓取出来。
 图2.4
图2.4
另外,因为Promise在代码中用多了之后,看起有点丑陋,所以我们将之改成用async和await的方式实现。并且把抓取到的信息写入到一个JSON文件(result.json)中。最终实现的演示代码如下:
/**
* 爬取技术资讯学习举例1
*/
const fs = require('fs');
const rp = require('request-promise');
const cheerio = require('cheerio');
const targetURL = 'https://xxxxxxxxxxxxxx'; // 略去了地址
const maxDeltaDay = 7;
/**
* 抓取目标网页中的技术资讯
* @param {string} url - 抓取的目标网页的网址
* @param {number} maxDeltaDay - 抓取距离当前时间多少天以内的资讯
*/
async function getArticles(url, maxDeltaDay) {
const options = generateOptions(url);
const $ = await rp(options);
const elements = $('.yq-new-item h3 a');
// 拿到包含文章标题、链接等的标签
const result = [];
const promises = [];
elements.map((index, el) => {
const $el = $(el);
const linkObj = {};
// 获取标题和链接
linkObj.title = $el.text();
const link = $el.attr('href');
linkObj.link = `https://yq.aliyun.com${link}`;
// 处理文章简介
let brief = $el.parent().parent().find('.new-desc-two').text();
brief = brief.replace(/\s*/g, '');
linkObj.brief = brief;
promises.push(
getDeltaDay(linkObj.link).then((deltaDay) => {
if (deltaDay < maxDeltaDay) {
linkObj.deltaDay = deltaDay;
result.push(linkObj);
}
})
);
});
Promise.all(promises).then(() => {
if (result.length) {
console.log(result);
result.sort((a, b) => {
return a.deltaDay - b.deltaDay;
})
fs.writeFileSync('./result.json', JSON.stringify(result));
}
});
}
/**
* 生成用于发起request-promise抓取用的options参数
* @param {string} url - 抓取的目标地址
*/
function generateOptions(url) {
return {
uri: url,
transform: (body) => {
return cheerio.load(body);
}
};
}
/**
* 抓取文章的发布时间
* @param {string} url - 文章的地址
*/
async function getDeltaDay(url) {
const options = generateOptions(url);
const $ = await rp(options);
const $time = $('.yq-blog-detail .b-time');
const dateTime = $time.text();
let deltaDay = (new Date() - new Date(dateTime)) / (24 * 60 * 60 * 1000);
deltaDay = deltaDay.toFixed(1);
return deltaDay;
}
// 入口
getArticles(targetURL, maxDeltaDay);
其中,getDeltaDay函数就是用来处理发布时间抓取的。我们最终的目的不是抓取该文章的发布时间,而是看该发布时间距离当前时间之间的差值是不是在7天之内。当然,如果想进一步筛选的话,你还可以抓取到阅读量、点赞量、收藏量等来进行判断。
2、数据接口中内容的抓取
上面这个是对于静态HTML页面上数据的抓取。下面再来看第二种,对于接口中数据的抓取。这里以对知名技术社区掘金的数据抓取为例。
 图2.5
图2.5
如图2.5所示,掘金的资讯分了推荐、后端、前端、Android、iOS、人工智能、开发工具、代码人生、阅读等多个类目。通过Chrome DevTools查看网络请求我们发现,页面中的文章列表数据是通过https://web-api.juejin.im/que...。且每个类目下的文章列表数据都是来自这同一个接口,只是请求的时候,Request Payload中的variables下的category(类目ID)字段不一样,如图2.6、图2.7所示。

图2.6
 图2.7
图2.7
所以,整体思路就是,建立一个类目名称和类目ID的map,使用不同的类目ID逐一去调用上述接口。具体的抓取工具仍然采用上面用过的request-promise。由于事先同样并不复杂,所以不做过多解释,直接贴上代码:
/**
* 爬取技术资讯学习举例2
*/
const rp = require('request-promise');
const fs = require('fs');
// 类目对应的ID
const categoryIDMap= {
'推荐': '',
'后端': '5562b419e4b00c57d9b94ae2',
'前端': '5562b415e4b00c57d9b94ac8',
'Android': '5562b410e4b00c57d9b94a92',
'iOS': '5562b405e4b00c57d9b94a41',
'人工智能': '57be7c18128fe1005fa902de',
'开发工具': '5562b422e4b00c57d9b94b53',
'代码人生': '5c9c7cca1b117f3c60fee548',
'阅读': '5562b428e4b00c57d9b94b9d'
};
/**
* 生成request-promise用到的options参数
* @param {string} categoryID - 类目ID
*/
function generateOptions(categoryID) {
return {
method: 'POST',
uri: ' // 略去了地址
body: {
'operationName': '',
'query': '',
'variables': {
'tags': [],
'category': categoryID,
'first': 20,
'after': '',
'order': 'POPULAR'
},
'extensions': {
'query': {
'id': '653b587c5c7c8a00ddf67fc66f989d42'
}
}
},
json: true,
headers: {
'X-Agent': 'Juejin/Web'
},
}
};
/**
* 获取某一类目下的资讯数据
* @param {string} categoryID - 类目ID
*/
async function getArtInOneCategory(categoryID, categoryName) {
const options = generateOptions(categoryID);
const res = await rp(options);
const data = res.data.articleFeed.items.edges;
let currentCategoryResult = [];
data.map((item) => {
const linkObj = {};
const {
title,
originalUrl,
updatedAt,
likeCount
} = item.node;
linkObj.title = title;
linkObj.link = originalUrl;
linkObj.likeCount = likeCount;
linkObj.category = categoryName;
let deltaDay = (new Date() - new Date(updatedAt)) / (24 * 60 * 60 * 1000);
deltaDay = deltaDay.toFixed(1);
if (deltaDay < 7) {
linkObj.deltaDay = deltaDay;
currentCategoryResult.push(linkObj);
}
});
return currentCategoryResult;
}
/**
* 获取所有类目下的资讯数据
*/
function getAllArticles() {
const promises = [];
let result = [];
Object.keys(categoryIDMap).map((key) => {
const categoryID = categoryIDMap[key];
promises.push(getArtInOneCategory(categoryID, key).then((res) => {
result = result.concat(res);
}));
});
Promise.all(promises).then(() => {
fs.writeFileSync('./result2.json', JSON.stringify(result));
});
}
// 入口
getAllArticles();
抓取到的结果如图2.8所示,主要抓取了标题、链接、点赞数、类目以及发布距离当前的时间差(天为单位):
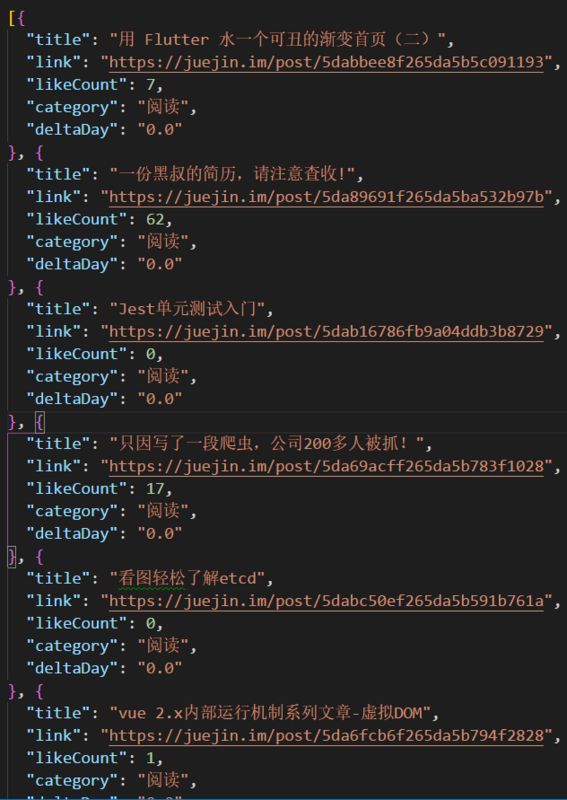
图2.8
3、微信公众号内容的抓取
除了上述两类内容的抓取外,还有一类资讯的抓取可能也是比较常遇到的,就是对于微信公众号内容的抓取。比如,以对于“xx早读课”这一公众号的抓取为例。微信公众号的内容如果直接从微信平台抓,需要登录,估计很容易被封号。因此,可以尝试另一种方法——通过搜狗搜索所提供的对于微信公众号的搜索结果进行抓取。
首先,通过https://weixin.sogou.com/weixin?type=1&s_from=input&query=%E5%89%8D%E7%AB%AF%E6%97%A9%E8%AF%BB%E8%AF%BE&ie=utf8&_sug_=y&_sug_type_=&w=01019900&sut=6202&sst0=1571574212479&lkt=0%2C0%2C0检索得到该公众号的英文ID。如图2.9所示。
 图2.9
图2.9
接着用该公众号英文ID搜索该公众号的最新文章,并通过点击“搜索工具”弹出的筛选面板中选择“一周内”,过滤出最近一周的文章(如图2.10所示)。之所以要用英文ID是为了让搜出来的结果只来自于该公众号,信息更为纯粹。
 图2.10
图2.10
不过,很遗憾,这些数据都是服务器直接渲染在了HTML页面中,而不是从接口中返回来的。而且,在呈现这些信息之前,还得经过图2.10所示的几步交互操作。所以不能像上面两种方法那样抓取数据。具体实现上可以采用可以puppeteer。puppeteer 是一个Chrome官方出品的headless Chrome node库。它提供了一系列的API, 可以在无UI的情况下调用Chrome的功能, 适用于爬虫、自动化处理等各种场景(如自动化测试),详细的使用可以参考官方文档(https://github.com/GoogleChrome/puppeteer)。篇幅所限,这里就不展开介绍具体实现了。值得注意的是,搜狗搜索做了很多反爬虫的工作,所以需要注意:
1)在puppteer的lunch的时候,需要加上headless: false选项,避免要你输入验证码。如下所示:
const browser = await puppeteer.launch({
headless: false
});
2)抓取次数宜尽量少,否则当你频繁抓取时,对方就会要求你输入验证码,这时候抓取工作就无法继续了。
即便你注意了这两点,你仍然可能遇到被识别为爬虫的情况。所以,权当是对puppeteer的学习尝试吧,毕竟这个工具功能还挺强大的,在前端自动化测试等领域,大有可为。
三、延申性的思考
上面对于信息的采集做了一些具体的介绍。对于信息可以做进一步的加工处理,以便更好地自己进行学习和研究,这里提供一点思路。

图3.1
如图3.1所示,通过后台服务从消息来源池里采集到数据之后,可以把数据建立一个库存储起来,提供一些数据服务接口供前端业务使用。你可以对数据进行处理、加工,可视化出来,比如直接以前端Web页面的形式呈现,也可以做一个原生的APP。甚至加上一些反馈渠道,对信息进行评价,从而从评价数据反推消息来源渠道的质量。
至于根据喜好来控制阅读和交互体验方面,一般来说,有一些共同的准则。比如,简洁的整体风格,突出内容本身的沉浸式、无打扰感受;合适的字号、行间距;优美的字体;可调、护眼的背景颜色;操作的流畅性;提供互动渠道,让阅读过程中有人共同参与而不孤独。这方面感兴趣的话可以参考下这篇文章对于微信阅读的分析(http://www.woshipm.com/evaluating/977491.html),这里不过多赘述。
总结
本文首先分析一些常见资讯获取方式的优缺点,分享了进行技术资讯获取DIY的框架性思考,阐明了其价值。然后借助三个具体的抓取案例剖析了抓取思路,并做了部分演示性的代码举例。最后就该主题进行了延申行的思考,基于此可以DIY出来一款简单的产品,甚至一个系统。
末了,关于Flutter的彩蛋找到了吗?(在图2.2中第二条信息哦)