主要模块
- requests模块。使用requests模块来获取http响应
- gevent模块。使用gevent开启多个协程,加快爬取速度
- re模块或beautifulsoup模块。正则表达式解析与beautifulsoup解析两种解析方式我都会写出来。
- csv模块。用于将数据导出至csv文件内
分析过程
1.要爬取的页面的URL地址为:http://www.tianqihoubao.com/aqi/。首先访问该页面(如下图)获取所有城市a标签的href属性,知道了各个城市的api,就可以接着爬取每个城市具体的空气质量了。

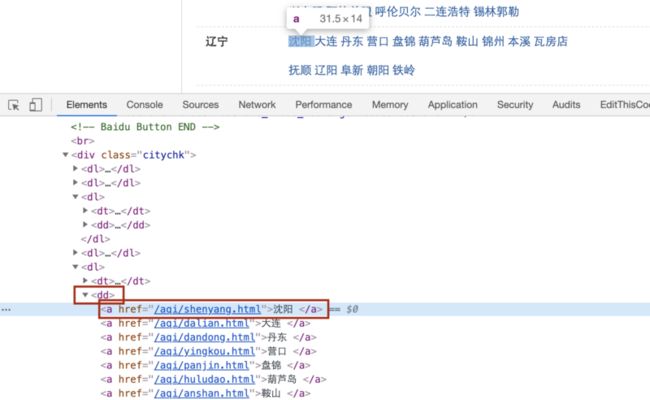
2.打开chrome的调试页面,可以看到,a标签在dd标签下,而且整个页面,只有dd标签下只要a标签没有其他标签了。所以正则匹配或使用BS4查找元素时,都可以先找dd标签,再找下面的a标签的href属性。(整个页面只有这里有dd标签,所以要查找dd标签)
3.找到每个城市的url后,再点击去看,发现是月份选择,这里是2020年3月为例,点进去。可以看到,找到了我们需要的空气质量信息。接下来就看如何从页面中将天气信息提取出来。


4.打开chrome调试工具。可以看到,需要的空气质量信息,在tr标签下的td标签内,而且每个tr标签对应一天的空气质量信息,那么就可以首先查找tr标签,然后取出td标签内的空气质量信息。(整个页面只有这里有tr标签,所以要查找tr标签)

代码如下
1.先写一下使用re正则解析的完整代码。我的思路是:先获取所有城市的a标签中的href属性,然后在URL最后拼接出想获取的月份,这里我获取的是2020年前3个月的。最后开启10个协程,对每个城市新建一个文件,写入抓取的空气质量数据。如果需要将所有文件合成一个的话,可以执行我单列出来的那段代码。
import time
import csv
import re
import gevent
from gevent import monkey,pool
monkey.patch_all()
import requests
# 存储城市url
city_url = []
# 存储要查看的时间范围
weather_date = []
# task列表
task_list = []
def func(url):
"""获取html页面"""
response = requests.get(url)
# 判断是否请求成功
if response.status_code != 200:
print("请求失败")
print(response.headers)
return
html = response.content.decode("gbk")
response.close()
return html
def get_city_url_list(url):
"""获取城市url列表"""
try:
html = func(url)
except Exception as e:
return
city_list = re.findall(r"(.*?) ", html, re.S)
for i in city_list:
# cities = re.findall(r'', i)
cities = re.findall(r'(.*?)', i)
for j in cities:
# city_url.append('http://www.tianqihoubao.com' + j)
city_url.append(j)
def get_day_weather_data(urlname):
"""获取每个城市的2019全年与2020年之间的天气情况,并存储为csv文件
urlname:tuple,第一项为url,第二项为name
f:文件描述符
"""
with open(r".\2020年1-3月\%s.csv" % urlname[1], "w", newline='') as f:
name = urlname[1]
for i in weather_date:
new_url = re.sub(r"\.html", "-"+i+".html", urlname[0])
print(new_url)
html = func('http://www.tianqihoubao.com' + new_url)
# 失败的话尝试3次
# times = 0
# while times < 3:
# try:
# html = func('http://www.tianqihoubao.com' + new_url)
# break
# except Exception as e:
# time.sleep(2)
# times += 1
# if times == 3:
# return
row_list = re.findall(r"(.*?) ", html, re.S)
for j in row_list[1:]:
aqi_data = re.findall(r"\s*(.*?)\s*", j, re.S)
# 2. 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
csv_writer.writerow([name]+aqi_data)
if __name__ == "__main__":
get_city_url_list("http://www.tianqihoubao.com/aqi/")
# print(city_url)
# for i in city_url[41:]:
# print(i)
# 处理标签变为201903这种格式
date_list = [str(i) for i in range(1, 4)]
for i in date_list:
if len(i) < 2:
i = "0" + i
weather_date.append("2020"+i)
# print(weather_date)
# with open(r"全国城市天气2.csv", "w") as f:
# for i in city_url:
# get_day_weather_data(i, f)
# 多协程生成csv文件
task_pool = pool.Pool(10)
for i in city_url:
task_pool.apply_async(get_day_weather_data, args=(i,))
task_pool.join() import os
# 如果需要将所有文件合成为一个的话,执行这段代码
path = 'D:\\Pycharm Projects\\天气数据爬取\\2020年1-3月'
pathnames = []
for (dirpath, dirnames, filenames) in os.walk(path):
for filename in filenames:
print()
pathnames += [os.path.join(path, filename)]
print(pathnames)
with open(r".\weather_data_202001-03.csv", "w") as f:
for i in pathnames:
with open(i, "r") as g:
data = g.read()
f.write(data)2.后来我又学习了一下beautulsoup模块,解析html页面很简单,我写的抓取a标签href属性部分的代码如下:
# http://www.tianqihoubao.com/aqi/
with open("123.html", "r") as f:
soup = BeautifulSoup(f, "html.parser")
# 找到所有dd标签
l1 = soup.find_all('dd')
for i in l1:
# 找到每个dd标签下的所有a标签
l2 = i.find_all('a')
for j in l2:
# 打印出每个a标签的href属性
print(j['href'])3.最后说下我的感受。关于re与beautifulsoup两个模块,我更习惯于用re模块,re给我的感觉就是:虽然写起来有点难度,但是抓数据时想抓哪里就抓哪里,比如我上面匹配到的数据中间有空格换行等,使用正则表达式可以在抓取的时候就将这些剔除掉,而beautifulsoup我目前还没有找到比较好的方法。大家可以自行尝试,对代码部分有疑问可以直接在文章下面评论,我看到后会立即回复。