String 类也是java.lang 包下的一个类,算是日常编码中最常用的一个类了,那么本篇博客就来详细的介绍 String 类。
1、String 类的定义
public final class String
implements java.io.Serializable, Comparable, CharSequence {} 和上一篇博客所讲的 Integer 类一样,这也是一个用 final 声明的常量类,不能被任何类所继承,而且一旦一个String对象被创建, 包含在这个对象中的字符序列是不可改变的, 包括该类后续的所有方法都是不能修改该对象的,直至该对象被销毁,这是我们需要特别注意的(该类的一些方法看似改变了字符串,其实内部都是创建一个新的字符串,下面讲解方法时会介绍)。接着实现了 Serializable接口,这是一个序列化标志接口,还实现了 Comparable 接口,用于比较两个字符串的大小(按顺序比较单个字符的ASCII码),后面会有具体方法实现;最后实现了 CharSequence 接口,表示是一个有序字符的集合,相应的方法后面也会介绍。
2、字段属性
/**用来存储字符串 */
private final char value[];
/** 缓存字符串的哈希码 */
private int hash; // Default to 0
/** 实现序列化的标识 */
private static final long serialVersionUID = -6849794470754667710L;一个 String 字符串实际上是一个 char 数组。
3、构造方法
String 类的构造方法很多。可以通过初始化一个字符串,或者字符数组,或者字节数组等等来创建一个 String 对象。

String str1 = "abc";//注意这种字面量声明的区别,文末会详细介绍
String str2 = new String("abc");
String str3 = new String(new char[]{'a','b','c'});4、equals(Object anObject) 方法
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}String 类重写了 equals 方法,比较的是组成字符串的每一个字符是否相同,如果都相同则返回true,否则返回false。
5、hashCode() 方法
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}String 类的 hashCode 算法很简单,主要就是中间的 for 循环,计算公式如下:
s[0] 31^(n-1) + s[1]31^(n-2) + ... + s[n-1]
s 数组即源码中的 val 数组,也就是构成字符串的字符数组。这里有个数字 31 ,为什么选择31作为乘积因子,而且没有用一个常量来声明?主要原因有两个:
①、31是一个不大不小的质数,是作为 hashCode 乘子的优选质数之一。
②、31可以被 JVM 优化,31 * i = (i << 5) - i。因为移位运算比乘法运行更快更省性能。
6、charAt(int index) 方法
public char charAt(int index) {
//如果传入的索引大于字符串的长度或者小于0,直接抛出索引越界异常
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];//返回指定索引的单个字符
}我们知道一个字符串是由一个字符数组组成,这个方法是通过传入的索引(数组下标),返回指定索引的单个字符。
7、compareTo(String anotherString) 和 compareToIgnoreCase(String str) 方法
我们先看看 compareTo 方法:
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}源码也很好理解,该方法是按字母顺序比较两个字符串,是基于字符串中每个字符的 Unicode 值。当两个字符串某个位置的字符不同时,返回的是这一位置的字符 Unicode 值之差,当两个字符串都相同时,返回两个字符串长度之差。
compareToIgnoreCase() 方法在 compareTo 方法的基础上忽略大小写,我们知道大写字母是比小写字母的Unicode值小32的,底层实现是先都转换成大写比较,然后都转换成小写进行比较。
### 8、concat(String str) 方法
该方法是将指定的字符串连接到此字符串的末尾。
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}首先判断要拼接的字符串长度是否为0,如果为0,则直接返回原字符串。如果不为0,则通过 Arrays 工具类(后面会详细介绍这个工具类)的copyOf方法创建一个新的字符数组,长度为原字符串和要拼接的字符串之和,前面填充原字符串,后面为空。接着在通过 getChars 方法将要拼接的字符串放入新字符串后面为空的位置。
注意:返回值是 new String(buf, true),也就是重新通过 new 关键字创建了一个新的字符串,原字符串是不变的。这也是前面我们说的一旦一个String对象被创建, 包含在这个对象中的字符序列是不可改变的。
9、indexOf(int ch) 和 indexOf(int ch, int fromIndex) 方法
indexOf(int ch),参数 ch 其实是字符的 Unicode 值,这里也可以放单个字符(默认转成int),作用是返回指定字符第一次出现的此字符串中的索引。其内部是调用 indexOf(int ch, int fromIndex),只不过这里的 fromIndex =0 ,因为是从 0 开始搜索;而 indexOf(int ch, int fromIndex) 作用也是返回首次出现的此字符串内的索引,但是从指定索引处开始搜索。
public int indexOf(int ch) {
return indexOf(ch, 0);//从第一个字符开始搜索
}public int indexOf(int ch, int fromIndex) {
final int max = value.length;//max等于字符的长度
if (fromIndex < 0) {//指定索引的位置如果小于0,默认从 0 开始搜索
fromIndex = 0;
} else if (fromIndex >= max) {
//如果指定索引值大于等于字符的长度(因为是数组,下标最多只能是max-1),直接返回-1
return -1;
}
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {//一个char占用两个字节,如果ch小于2的16次方(65536),绝大多数字符都在此范围内
final char[] value = this.value;
for (int i = fromIndex; i < max; i++) {//for循环依次判断字符串每个字符是否和指定字符相等
if (value[i] == ch) {
return i;//存在相等的字符,返回第一次出现该字符的索引位置,并终止循环
}
}
return -1;//不存在相等的字符,则返回 -1
} else {//当字符大于 65536时,处理的少数情况,该方法会首先判断是否是有效字符,然后依次进行比较
return indexOfSupplementary(ch, fromIndex);
}
}10、split(String regex) 和 split(String regex, int limit) 方法
split(String regex) 将该字符串拆分为给定正则表达式的匹配。split(String regex , int limit) 也是一样,不过对于 limit 的取值有三种情况:
①、limit > 0 ,则pattern(模式)应用n - 1 次
String str = "a,b,c";
String[] c1 = str.split(",", 2);
System.out.println(c1.length);//2
System.out.println(Arrays.toString(c1));//{"a","b,c"}②、limit = 0 ,则pattern(模式)应用无限次并且省略末尾的空字串
String str2 = "a,b,c,,";
String[] c2 = str2.split(",", 0);
System.out.println(c2.length);//3
System.out.println(Arrays.toString(c2));//{"a","b","c"}③、limit < 0 ,则pattern(模式)应用无限次
String str2 = "a,b,c,,";
String[] c2 = str2.split(",", -1);
System.out.println(c2.length);//5
System.out.println(Arrays.toString(c2));//{"a","b","c","",""}下面我们看看底层的源码实现。对于 split(String regex) 没什么好说的,内部调用 split(regex, 0) 方法:
public String[] split(String regex) {
return split(regex, 0);
}重点看 split(String regex, int limit) 的方法实现:
public String[] split(String regex, int limit) {
/* 1、单个字符,且不是".$|()[{^?*+\\"其中一个
* 2、两个字符,第一个是"\",第二个大小写字母或者数字
*/
char ch = 0;
if (((regex.value.length == 1 &&
".$|()[{^?*+\\".indexOf(ch = regex.charAt(0)) == -1) ||
(regex.length() == 2 &&
regex.charAt(0) == '\\' &&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 &&
((ch-'a')|('z'-ch)) < 0 &&
((ch-'A')|('Z'-ch)) < 0)) &&
(ch < Character.MIN_HIGH_SURROGATE ||
ch > Character.MAX_LOW_SURROGATE))
{
int off = 0;
int next = 0;
boolean limited = limit > 0;//大于0,limited==true,反之limited==false
ArrayList list = new ArrayList<>();
while ((next = indexOf(ch, off)) != -1) {
//当参数limit<=0 或者 集合list的长度小于 limit-1
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next));
off = next + 1;
} else {//判断最后一个list.size() == limit - 1
list.add(substring(off, value.length));
off = value.length;
break;
}
}
//如果没有一个能匹配的,返回一个新的字符串,内容和原来的一样
if (off == 0)
return new String[]{this};
// 当 limit<=0 时,limited==false,或者集合的长度 小于 limit是,截取添加剩下的字符串
if (!limited || list.size() < limit)
list.add(substring(off, value.length));
// 当 limit == 0 时,如果末尾添加的元素为空(长度为0),则集合长度不断减1,直到末尾不为空
int resultSize = list.size();
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).length() == 0) {
resultSize--;
}
}
String[] result = new String[resultSize];
return list.subList(0, resultSize).toArray(result);
}
return Pattern.compile(regex).split(this, limit);
} 11、replace(char oldChar, char newChar) 和 String replaceAll(String regex, String replacement) 方法
①、replace(char oldChar, char newChar) :将原字符串中所有的oldChar字符都替换成newChar字符,返回一个新的字符串。
②、String replaceAll(String regex, String replacement):将匹配正则表达式regex的匹配项都替换成replacement字符串,返回一个新的字符串。
12、substring(int beginIndex) 和 substring(int beginIndex, int endIndex) 方法
①、substring(int beginIndex):返回一个从索引 beginIndex 开始一直到结尾的子字符串。
public String substring(int beginIndex) {
if (beginIndex < 0) {//如果索引小于0,直接抛出异常
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;//subLen等于字符串长度减去索引
if (subLen < 0) {//如果subLen小于0,也是直接抛出异常
throw new StringIndexOutOfBoundsException(subLen);
}
//1、如果索引值beginIdex == 0,直接返回原字符串
//2、如果不等于0,则返回从beginIndex开始,一直到结尾
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}②、 substring(int beginIndex, int endIndex):返回一个从索引 beginIndex 开始,到 endIndex 结尾的子字符串。
13、常量池
在前面讲解构造函数的时候,我们知道最常见的两种声明一个字符串对象的形式有两种:
①、通过“字面量”的形式直接赋值
String str = "hello";
②、通过 new 关键字调用构造函数创建对象
String str = new String("hello");
那么这两种声明方式有什么区别呢?在讲解之前,我们先介绍 JDK1.7(不包括1.7)以前的 JVM 的内存分布:
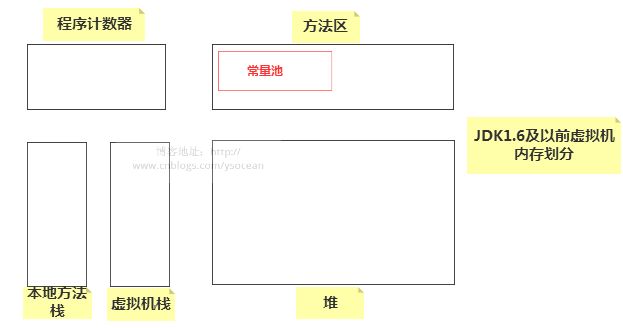
①、程序计数器:也称为 PC 寄存器,保存的是程序当前执行的指令的地址(也可以说保存下一条指令的所在存储单元的地址),当CPU需要执行指令时,需要从程序计数器中得到当前需要执行的指令所在存储单元的地址,然后根据得到的地址获取到指令,在得到指令之后,程序计数器便自动加1或者根据转移指针得到下一条指令的地址,如此循环,直至执行完所有的指令。线程私有。
②、虚拟机栈:基本数据类型、对象的引用都存放在这。线程私有。
③、本地方法栈:虚拟机栈是为执行Java方法服务的,而本地方法栈则是为执行本地方法(Native Method)服务的。在JVM规范中,并没有对本地方法栈的具体实现方法以及数据结构作强制规定,虚拟机可以自由实现它。在HotSopt虚拟机中直接就把本地方法栈和虚拟机栈合二为一。
④、方法区:存储了每个类的信息(包括类的名称、方法信息、字段信息)、静态变量、常量以及编译器编译后的代码等。注意:在Class文件中除了类的字段、方法、接口等描述信息外,还有一项信息是常量池,用来存储编译期间生成的字面量和符号引用。
⑤、堆:用来存储对象本身的以及数组(当然,数组引用是存放在Java栈中的)。
在 JDK1.7 以后,方法区的常量池被移除放到堆中了,如下:
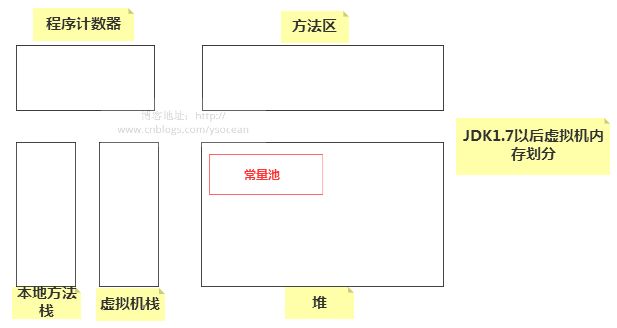
常量池:Java运行时会维护一个String Pool(String池), 也叫“字符串缓冲区”。String池用来存放运行时中产生的各种字符串,并且池中的字符串的内容不重复。
①、字面量创建字符串或者纯字符串(常量)拼接字符串会先在字符串池中找,看是否有相等的对象,没有的话就在字符串池创建该对象;有的话则直接用池中的引用,避免重复创建对象。
②、new关键字创建时,直接在堆中创建一个新对象,变量所引用的都是这个新对象的地址,但是如果通过new关键字创建的字符串内容在常量池中存在了,那么会由堆在指向常量池的对应字符;但是反过来,如果通过new关键字创建的字符串对象在常量池中没有,那么通过new关键词创建的字符串对象是不会额外在常量池中维护的。
③、使用包含变量表达式来创建String对象,则不仅会检查维护字符串池,还会在堆区创建这个对象,最后是指向堆内存的对象。
String str1 = "hello";
String str2 = "hello";
String str3 = new String("hello");
System.out.println(str1==str2);//true
System.out.println(str1==str3);//fasle
System.out.println(str2==str3);//fasle
System.out.println(str1.equals(str2));//true
System.out.println(str1.equals(str3));//true
System.out.println(str2.equals(str3));//true 对于上面的情况,首先 String str1 = "hello",会先到常量池中检查是否有“hello”的存在,发现是没有的,于是在常量池中创建“hello”对象,并将常量池中的引用赋值给str1;第二个字面量 String str2 = "hello",在常量池中检测到该对象了,直接将引用赋值给str2;第三个是通过new关键字创建的对象,常量池中有了该对象了,不用在常量池中创建,然后在堆中创建该对象后,将堆中对象的引用赋值给str3,再将该对象指向常量池。如下图所示:
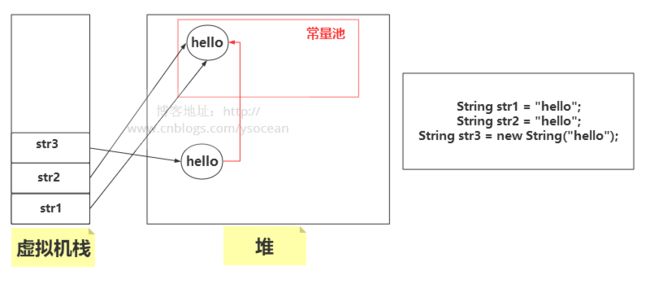
注意:看上图红色的箭头,通过 new 关键字创建的字符串对象,如果常量池中存在了,会将堆中创建的对象指向常量池的引用。我们可以通过文章末尾介绍的intern()方法来验证。
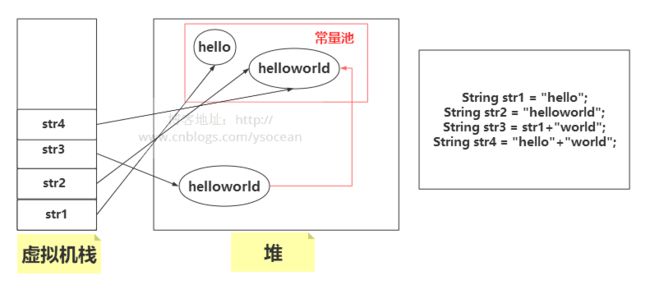
使用包含变量表达式创建对象:
String str1 = "hello";
String str2 = "helloworld";
String str3 = str1+"world";//编译器不能确定为常量(会在堆区创建一个String对象)
String str4 = "hello"+"world";//编译器确定为常量,直接到常量池中引用
System.out.println(str2==str3);//fasle
System.out.println(str2==str4);//true
System.out.println(str3==str4);//fasle str3 由于含有变量str1,编译器不能确定是常量,会在堆区中创建一个String对象。而str4是两个常量相加,直接引用常量池中的对象即可。
14、intern() 方法
这是一个本地方法:
public native String intern();
当调用intern方法时,如果池中已经包含一个与该String确定的字符串相同equals(Object)的字符串,则返回该字符串。否则,将此String对象添加到池中,并返回此对象的引用。
这句话什么意思呢?就是说调用一个String对象的intern()方法,如果常量池中有该对象了,直接返回该字符串的引用(存在堆中就返回堆中,存在池中就返回池中),如果没有,则将该对象添加到池中,并返回池中的引用。
String str1 = "hello";//字面量 只会在常量池中创建对象
String str2 = str1.intern();
System.out.println(str1==str2);//true
String str3 = new String("world");//new 关键字只会在堆中创建对象
String str4 = str3.intern();
System.out.println(str3 == str4);//false
String str5 = str1 + str2;//变量拼接的字符串,会在常量池中和堆中都创建对象
String str6 = str5.intern();//这里由于池中已经有对象了,直接返回的是对象本身,也就是堆中的对象
System.out.println(str5 == str6);//true
String str7 = "hello1" + "world1";//常量拼接的字符串,只会在常量池中创建对象
String str8 = str7.intern();
System.out.println(str7 == str8);//true15、String 真的不可变吗?
前面我们介绍了,String 类是用 final 关键字修饰的,所以我们认为其是不可变对象。但是真的不可变吗?
每个字符串都是由许多单个字符组成的,我们知道其源码是由 char[] value 字符数组构成。
public final class String
implements java.io.Serializable, Comparable, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0 value 被 final 修饰,只能保证引用不被改变,但是 value 所指向的堆中的数组,才是真实的数据,只要能够操作堆中的数组,依旧能改变数据。而且 value 是基本类型构成,那么一定是可变的,即使被声明为 private,我们也可以通过反射来改变。
String str = "vae";
//打印原字符串
System.out.println(str);//vae
//获取String类中的value字段
Field fieldStr = String.class.getDeclaredField("value");
//因为value是private声明的,这里修改其访问权限
fieldStr.setAccessible(true);
//获取str对象上的value属性的值
char[] value = (char[]) fieldStr.get(str);
//将第一个字符修改为 V(小写改大写)
value[0] = 'V';
//打印修改之后的字符串
System.out.println(str);//Vae通过前后两次打印的结果,我们可以看到 String 被改变了,但是在代码里,几乎不会使用反射的机制去操作 String 字符串,所以,我们会认为 String 类型是不可变的。
那么,String 类为什么要这样设计成不可变呢?我们可以从性能以及安全方面来考虑:
安全
引发安全问题,譬如,数据库的用户名、密码都是以字符串的形式传入来获得数据库的连接,或者在socket编程中,主机名和端口都是以字符串的形式传入。因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变字符串指向的对象的值,造成安全漏洞。
保证线程安全,在并发场景下,多个线程同时读写资源时,会引竞态条件,由于 String 是不可变的,不会引发线程的问题而保证了线程。
HashCode,当 String 被创建出来的时候,hashcode也会随之被缓存,hashcode的计算与value有关,若 String 可变,那么 hashcode 也会随之变化,针对于 Map、Set 等容器,他们的键值需要保证唯一性和一致性,因此,String 的不可变性使其比其他对象更适合当容器的键值。
性能
当字符串是不可变时,字符串常量池才有意义。字符串常量池的出现,可以减少创建相同字面量的字符串,让不同的引用指向池中同一个字符串,为运行时节约很多的堆内存。若字符串可变,字符串常量池失去意义,基于常量池的String.intern()方法也失效,每次创建新的 String 将在堆内开辟出新的空间,占据更多的内存
参考文档:
https://docs.oracle.com/javas...
https://segmentfault.com/a/11...
本系列教程持续更新,可以微信搜索「 IT可乐 」第一时间阅读。回复《电子书》有我为大家特别筛选的书籍资料
