Remote procedure call (RPC)
Remote procedure call (RPC)
(using the .NET client)
Prerequisites
This tutorial assumes RabbitMQ isinstalled and running on localhoston standard port (5672). In case you use a different host, port or credentials, connections settings would require adjusting.
Where to get help
If you're having trouble going through this tutorial you can contact usthrough the mailing list.
In the second tutorial we learned how to use Work Queues to distribute time-consuming tasks among multiple workers.
But what if we need to run a function on a remote computer and wait for the result? Well, that's a different story. This pattern is commonly known asRemote Procedure Call or RPC.
In this tutorial we're going to use RabbitMQ to build an RPC system: a client and a scalable RPC server. As we don't have any time-consuming tasks that are worth distributing, we're going to create a dummy RPC service that returns Fibonacci numbers.
Client interface
To illustrate how an RPC service could be used we're going to create a simple client class. It's going to expose a method named call which sends an RPC request and blocks until the answer is received:
var rpcClient = new RPCClient(); Console.WriteLine(" [x] Requesting fib(30)"); var response = rpcClient.Call("30"); Console.WriteLine(" [.] Got '{0}'", response); rpcClient.Close();
A note on RPC
Although RPC is a pretty common pattern in computing, it's often criticised. The problems arise when a programmer is not aware whether a function call is local or if it's a slow RPC. Confusions like that result in an unpredictable system and adds unnecessary complexity to debugging. Instead of simplifying software, misused RPC can result in unmaintainable spaghetti code.
Bearing that in mind, consider the following advice:
- Make sure it's obvious which function call is local and which is remote.
- Document your system. Make the dependencies between components clear.
- Handle error cases. How should the client react when the RPC server is down for a long time?
When in doubt avoid RPC. If you can, you should use an asynchronous pipeline - instead of RPC-like blocking, results are asynchronously pushed to a next computation stage.
Callback queue
In general doing RPC over RabbitMQ is easy. A client sends a request message and a server replies with a response message. In order to receive a response we need to send a 'callback' queue address with the request:
var corrId = Guid.NewGuid().ToString(); var props = channel.CreateBasicProperties(); props.ReplyTo = replyQueueName; props.CorrelationId = corrId; var messageBytes = Encoding.UTF8.GetBytes(message); channel.BasicPublish("", "rpc_queue", props, messageBytes); // ... then code to read a response message from the callback_queue ...
Message properties
The AMQP protocol predefines a set of 14 properties that go with a message. Most of the properties are rarely used, with the exception of the following:
- deliveryMode: Marks a message as persistent (with a value of 2) or transient (any other value). You may remember this property from the second tutorial.
- contentType: Used to describe the mime-type of the encoding. For example for the often used JSON encoding it is a good practice to set this property to: application/json.
- replyTo: Commonly used to name a callback queue.
- correlationId: Useful to correlate RPC responses with requests.
Correlation Id
In the method presented above we suggest creating a callback queue for every RPC request. That's pretty inefficient, but fortunately there is a better way - let's create a single callback queue per client.
That raises a new issue, having received a response in that queue it's not clear to which request the response belongs. That's when the correlationId property is used. We're going to set it to a unique value for every request. Later, when we receive a message in the callback queue we'll look at this property, and based on that we'll be able to match a response with a request. If we see an unknown correlationId value, we may safely discard the message - it doesn't belong to our requests.
You may ask, why should we ignore unknown messages in the callback queue, rather than failing with an error? It's due to a possibility of a race condition on the server side. Although unlikely, it is possible that the RPC server will die just after sending us the answer, but before sending an acknowledgment message for the request. If that happens, the restarted RPC server will process the request again. That's why on the client we must handle the duplicate responses gracefully, and the RPC should ideally be idempotent.
Summary
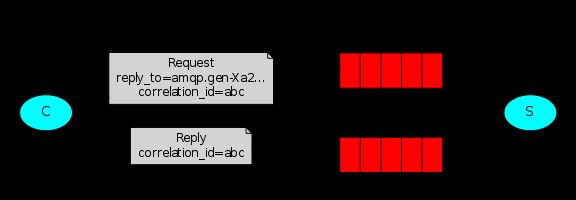
Our RPC will work like this:
- When the Client starts up, it creates an anonymous exclusive callback queue.
- For an RPC request, the Client sends a message with two properties: replyTo, which is set to the callback queue and correlationId, which is set to a unique value for every request.
- The request is sent to an rpc_queue queue.
- The RPC worker (aka: server) is waiting for requests on that queue. When a request appears, it does the job and sends a message with the result back to the Client, using the queue from thereplyTo field.
- The client waits for data on the callback queue. When a message appears, it checks thecorrelationId property. If it matches the value from the request it returns the response to the application.
Putting it all together
The Fibonacci task:
private static int fib(int n) { if (n == 0 || n == 1) return n; return fib(n - 1) + fib(n - 2); }
We declare our fibonacci function. It assumes only valid positive integer input. (Don't expect this one to work for big numbers, and it's probably the slowest recursive implementation possible).
The code for our RPC server RPCServer.cs looks like this:
class RPCServer { public static void Main() { var factory = new ConnectionFactory() { HostName = "localhost" }; using (var connection = factory.CreateConnection()) { using (var channel = connection.CreateModel()) { channel.QueueDeclare("rpc_queue", false, false, false, null); channel.BasicQos(0, 1, false); var consumer = new QueueingBasicConsumer(channel); channel.BasicConsume("rpc_queue", false, consumer); Console.WriteLine(" [x] Awaiting RPC requests"); while (true) { string response = null; var ea = (BasicDeliverEventArgs)consumer.Queue.Dequeue(); var body = ea.Body; var props = ea.BasicProperties; var replyProps = channel.CreateBasicProperties(); replyProps.CorrelationId = props.CorrelationId; try { var message = Encoding.UTF8.GetString(body); int n = int.Parse(message); Console.WriteLine(" [.] fib({0})", message); response = fib(n).ToString(); } catch (Exception e) { Console.WriteLine(" [.] " + e.Message); response = ""; } finally { var responseBytes = Encoding.UTF8.GetBytes(response); channel.BasicPublish("", props.ReplyTo, replyProps, responseBytes); channel.BasicAck(ea.DeliveryTag, false); } } } } } private static int fib