Hadoop系列之实验环境搭建
实验环境基本配置
硬件:硬盘单节点50GB,1G内存,单核。
操作系统:CentOS6.4 64bit
Hadoop:2.20 64bit(已编译)
JDK:jdk1.7
磁盘分区:
| / |
5GB |
| /boot |
100MB |
| /usr |
5GB |
| /tmp |
500MB |
| swap |
2GB |
| /var |
1GB |
| /home |
剩余空间 |
Linux系统安装配置
无桌面(Minimal)
Base SystemàBase, Compatibility libraries, Performance Tools, Perl Support
Developmentà Development Tools
LanguagesàChinese Support
创建Hadoop用户
Useradd Hadoop
Passwd Hadoop
网络配置
修改ip
vim /etc/sysconfig/network-scripts/ifcfg-eth0
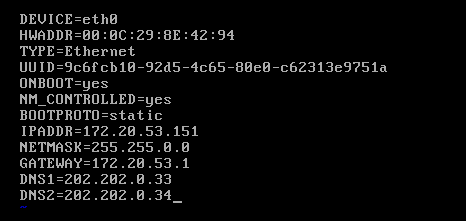
保存并重启网络service network restart
修改主机名
Vim /etc/sysconfig/network
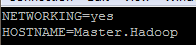
主机名和IP绑定
Vim /etc/host

关闭防火墙
查看状态service iptables status
关闭防火墙service iptables stop
查看防火墙开机启动状态 chkconfig iptables –list
关闭防火墙开机启动 chkconfig iptables off
关闭SELinux
Vim /etc/sysconfig/selinux

Setenforce 0
Getenforce
SSH免登陆设置
使用hadoop用户生成公钥和私钥:ssh-keygen –t rsa
将授权发送给Slave1..5:ssh-copy –i Slave1
同样,也将Slave1…5对Master进行免密登录
为了保证S1到Master通信,同样配置S1到Master免登陆
安装JDK
将jdk1.7解压缩到/usr/local/目录下,并改名为jdk
修改/etc/profile文件

| 主机名 |
IP |
安装的软件 |
运行的进程 |
| Master |
172.20.52.151 |
jdk、hadoop |
NameNode、DFSZKFailoverController |
| Slave1 |
172.20.52.171 |
jdk、hadoop |
ResourceManager |
| Slave2 |
172.20.52.21 |
jdk、hadoop、 |
NameNode、DFSZKFailoverController |
| Slave3 |
172.20.53.37 |
jdk、hadoop、zookeeper |
DataNode、NodeManager、JournalNode、QuorumPeerMain |
| Slave4 |
172.20.53.174 |
jdk、hadoop、zookeeper |
DataNode、NodeManager、JournalNode、QuorumPeerMain |
| Slave5 |
172.20.53.177 |
jdk、hadoop、zookeeper |
DataNode、NodeManager、JournalNode、QuorumPeerMain |
JournalNode负责数据同步,QuorumPeerMain是zk的进程。
namenode节点上/usr/hadoop/tmp/dfs/name/current/ 目录下存放了fsimage文件,块位置信息不会保存在fsimage中,块位置信息并不是由namenode来维护的,而是以块列表的形式放在datanode上。
而datanode节点上/usr/hadoop/tmp/dfs/data/current/ 目录下存放了文件块
Zookeeper的安装
zk用于协调管理数据节点,可以进行master选举,负载均衡,分布式锁等。
在S3,S4,S5节点上安装zookeeper:
-
S3上使用root用户登录,把zookeeper解压到/usr/local/下:
tar -zxvf zookeeper-3.4.5.tar.gz -C /usr/local/
-
进入到zookeeper目录下,对它进行配置。
-
将conf目录下的zoo_sample.cfg重命名为zoo.cfg:
mv zoo_sample.cfg zoo.cfg,用来zookeeper启动时读取
-
在/usr/local/ zookeeper-3.4.5/data创建文件myid,写入服务器id:1
-
修改zoo.cfg中日志存放路径到/usr/local/ zookeeper-3.4.5/data(记得创建data目录并创建myid文件),如下:

-
在文件最后添加如下信息:
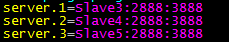
服务器ID:server.1
Zookeeper运行的主机:Slave3..5
通信端口:2888
选举端口:3888
-
将配置好的zookeeper用scp发送给S4,S5
scp –r /usr/local/ zookeeper-3.4.5/ root@Slave4: /usr/local/ zookeeper-3.4.5/
scp –r /usr/local/ zookeeper-3.4.5/ root@Slave5: /usr/local/ zookeeper-3.4.5/
别忘了修改myid文件中的服务器号
-
启动三个节点的zk:
调用bin目录下的zkServer.sh脚本命令:./ zkServer.sh start

-
查看状态./ zkServer.sh status
三个节点只有一个为leader,其余为follower
安装hadoop
将编译好的hadoop-2.2.0.tar.gz上传至Master,用root用户解压到/usr目录下,改名为hadoop
-
在hadoop目录下创建tmp文件夹(可省略)
mkdir tmp
-
设置hadoop目录的所有者为hadoop:
chown –R Hadoop:hadoop Hadoop
-
将hadoop添加到环境变量中vim /etc/profile

其余几个节点也如此配置。
配置hadoop
-
配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
修改/usr/Hadoop/etc/Hadoop/目录下的配置文件
-
配置hadoop运行环境,修改hadoo-env.sh:

-
修改core-site.xml
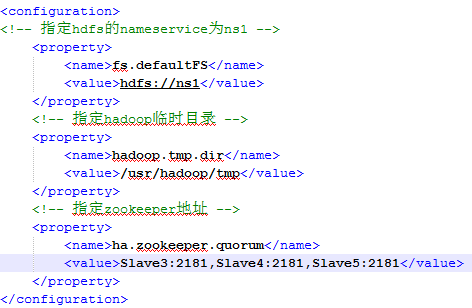
Hadoop.tmp.dir参数虽然称为临时目录,其实保存的是以后hdfs的数据,nameservice指定了该HDFS集群的名称为ns1
-
修改hdfs-site.xml文件
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>Master:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>Master:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>Slave1:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>Slave1:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://Slave3:8485;Slave4:8485;Slave5:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/hadoop/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
</configuration>
-
重命名mapred-site.xml.template为mapred-site.xml并配置如下

说明MR框架运行在yarn之上
-
配置子节点文件:slaves
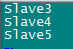
DN为S3,S4,S5
-
将配置好的hadoop复制到其他节点上(root)
scp –r /usr/Hadoop/ Slave1:/usr/Hadoop/
复制后应修改权限:chown –R Hadoop:hadoop Hadoop
启动hadoop
-
启动zookeeper:
bin/ zkServer.sh start
-
启动journalnode(在Master上启动所有journalnode)
cd /usr/hadoop
sbin/hadoop-daemons.sh start journalnode 通过ssh协议同时启动多个进程
(运行jps命令检验,多了JournalNode进程)
-
格式化HDFS
在Master上执行命令:hadoop namenode –format
此时将Master中tmp目录拷贝到Slave1的/usr/Hadoop/下:
scp –r /usr/Hadoop/tmp Slave1:/usr/Hadoop/ 这里面存放了fsimage和edits文件
-
格式化ZK(在Master上执行):hdfs zkfc –formatZK
此时,在S3..S5节点上的zk的bin目录下执行./zkCli.sh命令,可以发现多出hadoop-ha的目录用于保存数据。
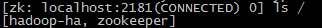
-
启动HDFS(在Master上执行):
sbin/start-dfs.sh
如果一个NameNode挂掉,重新启动要使用命令sbin/Hadoop-deamon.sh start namenode,要保证两个NameNode要ssh免密码登录。
-
在Slave2上启动yarn:sbin/start-yarn.sh yarn的web管理界面端口为8088
注:
关于修改虚拟机网卡
-
修改 /etc/udev/rules.d/70-persistent-net.rules 文件
删除掉 关于 eth0 的信息。修改 第二条 eth1 的网卡的名字为 eth0.
-
修改 /etc/sysconfig/network-scripts/ifcfg-eth0 中mac地址为 /etc/udev/rules.d/70-persistent-net.rules 修改后的eth0的mac地址。