| 企业软件热点文章 | |
| Java内存结构与模型结构分析 | Oracle触发器的语法详解 |
NOR和NAND
NOR和NAND都是闪存技术的一种,NOR是Intel公司开发的,它有点类似于内存,允许通过地址直接访问任何一个内存单元,缺点是:密度低(容量小),写入和擦除的速度很慢。NAND是东芝公司开发的,它密度高(容量大),写入和擦除的速度都很快,但是必须通过特定的IO接口经过地址转换之后才可以访问,有些类似于磁盘。
我们现在广泛使用的U盘,SD卡,SSD都属于NAND类型,厂商将flash memory封装成为不同的接口,比如Intel的SSD就是采用了SATA的接口,访问与普通SATA磁盘一样,还有一些企业级的闪存卡,比如FusionIO,则封装为PCIe接口。
SLC和MLC
SLC是单极单元,MLC是多级单元,两者的差异在于每单元存储的数据量(密度),SLC每单元只存储一位,只包含0和1两个电压符,MLC每单元可以存储两位,包含四个电压符(00,01,10,11)。显然,MLC的存储容量比SLC大,但是SLC更简单可靠,SLC读取和写入的速度都比MLC更快,而且SLC比MLC更耐用,MLC每单元可擦除1w次,而SLC可擦除10w次,所以,企业级的闪存产品一般都选用SLC,这也是为什么企业级产品比家用产品贵很多的原因。
SSD的技术特点
SSD与传统磁盘相比,第一是没有机械装置,第二是由磁介质改为了电介质。在SSD内部有一个FTL(Flash Transalation Layer),它相当于磁盘中的控制器,主要功能就是作地址映射,将flash memory的物理地址映射为磁盘的LBA逻辑地址,并提供给OS作透明访问。
SSD没有传统磁盘的寻道时间和延迟时间,所以SSD可以提供非常高的随机读取能力,这是它的最大优势,SLC类型的SSD通常可以提供超过35000的IOPS,传统15k的SAS磁盘,最多也只能达到160个IOPS,这对于传统磁盘来说几乎就是个天文数字。SSD连续读的能力相比普通磁盘优势并不明显,因为连续读对于传统磁盘来说,并不需要寻道时间,15k的SAS磁盘,连续读的吞吐能力可以达到130MB,而SLC类型的SSD可以达到170-200MB,我们看到在吞吐量方面,SSD虽然比传统磁盘高一些,但优势虽然并不明显。
SSD的写操作比较特殊,SSD的最小写入单元为4KB,称为页(page),当写入空白位置时可以按照4KB的单位写入,但是如果需要改写某个单元时,则需要一个额外的擦除(erase)动作,擦除的单位一般是128个page(512KB),每个擦除单元称为块(block)。如果向一个空白的page写入信息时,可以直接写入而无需擦除,但是如果需要改写某个存储单元(page)的数据,必须首先将整个block读入缓存,然后修改数据,并擦除整个block的数据,最后将整个block写入,很显然,SSD改写数据的代价很高,SSD的这个特性,我们称之为erase-before-write。
经过测试,SLC SSD的随即写性能可以达到3000个左右的IOPS,连续写的吞吐量可以达到170MB,这个数据还是比传统磁盘高出不少。但是,随着SSD的不断写入,当越来越多的数据需要被改写时,写的性能就会逐步下降。经过我们的测试,SLC在这个方面要明显好于MLC,在长时间写入后,MLC随机写IO下降得非常厉害,而SLC表现则比较稳定。为了解决这个问题,各个厂商都有很多策略来防止写性能下降的问题。
wear leveling
因为SSD存在“写磨损”的问题,当某个单元长时间被反复擦写时(比如Oracle redo),不仅会造成写入的性能问题,而且会大大缩短SSD的使用寿命,所以必须设计一个均衡负载的算法来保证SSD的每个单元能够被均衡的使用,这就是wear leveling,称为损耗均衡算法。
Wear leveling也是SSD内部的FTL实现的,它通过数据迁移来达到均衡损耗的目的。Wear leveling依赖于SSD中的一部分保留空间,基本原理是在SSD中设置了两个block pool,一个是free block pool(空闲池),一个是数据池(data block pool),当需要改写某个page时(如果写入原有位置,必须先擦除整个block,然后才能写入数据),并不写入原有位置(不需要擦除的动作),而是从空闲池中取出新的block,将现有的数据和需要改写的数据合并为新的block,一起写入新的空白block,原有的block被标识为invalid状态(等待被擦除回收),新的block则进入数据池。后台任务会定时从data block中取出无效数据的block,擦除后回收到空闲池中。这样做的好处在于,一是不会反复擦写同一个block,二是写入的速度会比较快(省略了擦除的动作)。
Wear leveling分为两种:动态损耗均衡和静态损耗均衡,两者的原理一致,区别在于动态算法只会处理动态数据,比如数据改写时才会触发数据迁移的动作,对静态数据不起作用,而静态算法可以均衡静态数据,当后台任务发现损耗很低的静态数据块时,将其迁移到其他数据库块上,将这些块放入空闲池中使用。从均衡的效果来看,静态算法要好于动态算法,因为几乎所有的block都可以被均衡的使用,SSD的寿命会大大延长,但是静态算法的缺点是当数据迁移时,可能会导致写性能下降。
写入放大
因为SSD的erase-before-write的特性,所以就出现了一个写入放大的概念,比如你想改写4K的数据,必须首先将整个擦除块(512KB)中的数据读出到缓存中,改写后,将整个块一起写入,这时你实际写入了512KB的数据,写入放大系数是128。写入放大最好的情况是1,就是不存在放大的情况。
Wear leveling算法可以有效缓解写入放大的问题,但是不合理的算法依然会导致写入放大,比如用户需要写入4k数据时,发现free block pool中没有空白的block,这时就必须在data block pool中选择一个包含无效数据的block,先读入缓存中,改写后,将整个块一起写入,采用wear leveling算法依然会存在写入放大的问题。
通过为SSD预留更多空间,可以显著缓解写入放大导致的性能问题。根据我们的测试结果,MLC SSD在长时间的随机写入后,性能下降很明显(随机写IOPS甚至降低到300)。如果为wear leveling预留更多空间,就可以显著改善MLC SSD在长时间写操作之后的性能下降问题,而且保留的空间越多,性能提升就越明显。相比较而言,SLC SSD的性能要稳定很多(IOPS在长时间随机写后,随机写可以稳定在3000 IOPS),我想应该是SLC SSD的容量通常比较小(32G和64G),而用于wear leveling的空间又比较大的原因。
数据库IO特点分析
IO有四种类型:连续读,随机读,随机写和连续写,连续读写的IO size通常比较大(128KB-1MB),主要衡量吞吐量,而随机读写的IO size比较小(小于8KB),主要衡量IOPS和响应时间。数据库中的全表扫描是连续读IO,索引访问则是典型的随机读IO,日志文件是连续写IO,而数据文件则是随机写IO。
数据库系统基于传统磁盘访问特性来设计,最大特点是日志文件采用sequential logging,数据库中的日志文件,要求必须在事务提交时写入到磁盘,对响应时间的要求很高,所以设计为顺序写入的方式,可以有效降低磁盘寻道花费的时间,减少延迟时间。日志文件的顺序写入,虽然是物理位置是连续的,但是并不同于传统的连续写类型,日志文件的IO size很小(通常小于4K),每个IO之间是独立的(磁头必须抬起来重新寻道,并等待磁盘转动到相应的位置),而且间隔很短,数据库通过log buffer(缓存)和group commit的方式(批量提交)来达到提高IO size的大小,并减少IO的次数,从而得到更小的响应延迟,所以日志文件的顺序写入可以被认为是“连续位置的随机写入”,更关注IOPS,而不是吞吐量。
数据文件采用in place uddate的方式,意思是数据文件的修改都是写入到原来的位置,数据文件不同于日志文件,并不会在事务commit时写入数据文件,只有当数据库发现dirty buffer过多或者需要做checkpoint动作时,才会刷新这些dirty buffer到相应的位置,这是一个异步的过程,通常情况下,数据文件的随机写入对IO的要求并不是特别高,只要满足checkpoint和dirty buffer的要求就可以了。
SSD的IO特点分析
1.随机读能力非常好,连续读性能一般,但比普通SAS磁盘好。
2.不存在磁盘寻道的延迟时间,随机写和连续写的响应延迟差异不大。
3.erase-before-write特性,造成写入放大,影响写入的性能。
4.写磨损特性,采用wear leveling算法延长寿命,但同时会影响读的性能。
5.读和写的IO响应延迟不对等(读要大大好于写),而普通磁盘读和写的IO响应延迟差异很小。
6.连续写比随机写性能好,比如1M顺序写比128个8K的随即写要好很多,因为随即写会带来大量的擦除。
基于SSD的上述特性,如果将数据库全部放在SSD上,可能会有以下的问题:
1.日志文件sequential logging会反复擦写同一位置,虽然有损耗均衡算法,但是长时间写入依然会导致性能下降。
2.数据文件in place update会产生大量的随机写入,erase-before-write会产生写入放大。
3.数据库读写混合型应用,存在大量的随机写入,同时会影响读的性能,产生大量的IO延迟。
基于SSD的数据库优化法则:
基于SSD的优化就是解决erase-before-write产生的写入放大的问题,不同类型的IO分离,减少写操作带来的性能影响。
1.将sequential logging修改为In-page logging,避免对相同位置的反复擦写。
2.通过缓存写入的方式将大量的in-place update随机写入合并为少量顺序写入。
3.利用SSD随机读写能力高的特点,减少写增加读,从而达到整体性能的提升。
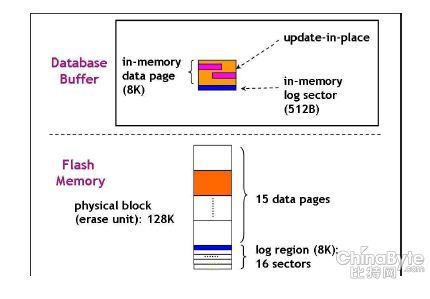
In-page logging
In-page logging是基于SSD对数据库sequential logging的一种优化方法,数据库中的sequential logging对传统磁盘是非常有利的,可以大大提高响应时间,但是对于SSD就是噩梦,因为需要对同一位置反复擦写,而wear leveling算法虽然可以平衡负载,但是依然会影响性能,并产生大量的IO延迟。所以In-page logging将日志和数据合并,将日志顺序写入改为随机写入,基于SSD对随机写和连续写IO响应延迟差异不大的特性,避免对同一位置反复擦写,提高整体性能。
In-page logging基本原理:在data buffer中,有一个in-memory log sector的结构,类似于log buffer,每个log sector是与data block对应的。在data buffer中,data和log并不合并,只是在data block和log sector之间建立了对应关系,可以将某个data block的log分离出来。但是,在SSD底层的flash memory中,数据和日志是存放在同一个block(擦除单元),每个block都包含data page和log page。
当日志信息需要写入的时候(log buffer空间不足或者事务提交),日志信息会写入到flash memory对应的block中,也就是说日志信息是分布在很多不同的block中的,而每个block内的日志信息是append write,所以不需要擦除的动作。当某个block中的log sector写满的时候,这时会发生一个动作,将整个block中的信息读出,然后应用block中的log sector,就可以得到最新的数据,然后整个block写入,这时,block中的log sector是空白的。
在in-page logging方法中,data buffer中的dirty block是不需要写入到flash memory中的,就算dirty buffer需要被交换出去,也不需要将它们写入flash memory中。当需要读取最新的数据,只要将block中的数据和日志信息合并,就可以得到最新的数据。
In-page logging方法,将日志和数据放在同一个擦除单元内,减少了对flash相同位置的反复擦写,而且不需要将dirty block写入到flash中,大量减少了in-place update的随机写入和擦除的动作。虽然在读取时,需要做一个merge的操作,但是因为数据和日志存放在一起,而且SSD的随机读取能力很高,in-page logging可以提高整体的性能。
SSD作为写cache-append write
SSD可以作为磁盘的写cache,因为SSD连续写比随机写性能好,比如:1M顺序写比128个8K的随机写要好很多,我们可以将大量随机写合并成为少量顺序写,增加IO的大小,减少IO(擦除)的次数,提高写入性能。这个方法与很多NoSQL产品的append write类似,即不改写数据,只追加数据,需要时做合并处理。
基本原理:当dirty block需要写入到数据文件时,并不直接更新原来的数据文件,而是首先进行IO合并,将很多个8K的dirty block合并为一个512KB的写入单元,并采用append write的方式写入到一个cache file中(保存在SSD上),避免了擦除的动作,提高了写入性能。cache file中的数据采用循环的方式顺序写入,当cache file空间不足够时,后台进程会将cache file中的数据写入到真正的数据文件中(保存在磁盘上),这时进行第二次IO合并,将cache file内的数据进行合并,整合成为少量的顺序写入,对于磁盘来说,最终的IO是1M的顺序写入,顺序写入只会影响吞吐量,而磁盘的吞吐量不会成为瓶颈,将IOPS的瓶颈转化为吞吐量的瓶颈,从而提升了整体系统能力。
读取数据时,必须首先读取cache file,而cache file中的数据是无序存放的,为了快速检索cache file中的数据,一般会在内存中为cache file建立一个索引,读取数据时会先查询这个索引,如果命中查询cache file,如果没有命中,再读取data file(普通磁盘),所以,这种方法实际不仅仅是写cache,同时也起到了读cache的作用。
但是这种方法并不适合日志文件的写cache,虽然日志文件也是append write,但是因为日志文件的IO size比较小,而且必须同步写入,无法做合并处理,所以性能提升有限。
SSD作为读cache-flashcache
因为大部分数据库都是读多写少的类型,所以SSD作为数据库flashcache是优化方案中最简单的一种,它可以充分利用SSD读性能的优势,又避免了SSD写入的性能问题。实现的方法有很多种,可以在读取数据时,将数据同时写入SSD,也可以在数据被刷出buffer时,写入到SSD。读取数据时,首先在buffer中查询,然后在flashcache中查询,最后读取datafile。
SSD作为flashcache与memcache作为数据库外部cache的最大区别在于,SSD掉电后数据是不丢失的,这也引起了另外一个思考,当数据库发生故障重启后,flashcache中的数据是有效还是无效?如果是有效的,那么就必须时刻保证flashcache中数据的一致性,如果是无效的,那么flashcache同样面临一个预热的问题(这与memcache掉电后的问题一样)。目前,据我所知,基本上都认为是无效的,因为要保持flashcache中数据的一致性,非常困难。
flashcache作为内存和磁盘之间的二级cache,除了性能的提升以外,从成本的角度看,SSD的价格介于memory和disk之间,作为两者之间的一层cache,可以在性能和价格之间找到平衡。
总结
随着SSD价格不断降低,容量和性能不断提升,SSD取代磁盘只是个时间问题。