人体姿态估计的过去,现在,未来

因为在ICIP2019上面和两位老师搞了一个关于人体姿态估计以及动作行为的tutorial,所以最近整理了蛮多人体姿态估计方面的文章。所以做了一个总结和梳理,希望能抛砖引玉。
人体姿态估计是计算机视觉中一个很基础的问题。从名字的角度来看,可以理解为对“人体”的姿态(关键点,比如头,左手,右脚等)的位置估计。一般我们可以这个问题再具体细分成4个任务:
单人姿态估计 (Single-Person Skeleton Estimation)
多人姿态估计 (Multi-person Pose Estimation)
人体姿态跟踪 (Video Pose Tracking)
3D人体姿态估计 (3D Skeleton Estimation)
具体讲一下每个任务的基础。首先是单人姿态估计, 输入是一个crop出来的行人,然后在行人区域位置内找出需要的关键点,比如头部,左手,右膝等。常见的数据集有MPII, LSP, FLIC, LIP。其中MPII是2014年引进的,目前可以认为是单人姿态估计中最常用的benchmark, 使用的是PCKh的指标(可以认为预测的关键点与GT标注的关键点经过head size normalize后的距离)。但是经过这几年的算法提升,整体结果目前已经非常高了(最高的已经有93.9%了)。下面是单人姿态估计的结果图(图片来源于CPM的paper):

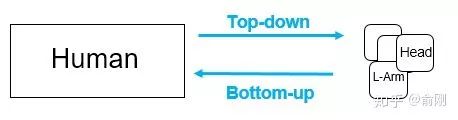
单人姿态估计算法往往会被用来做多人姿态估计。 多人姿态估计的输入是一张整图,可能包含多个行人,目的是需要把图片中所有行人的关键点都能正确的做出估计。 针对这个问题,一般有两种做法,分别是top-down以及bottom-up的方法。 对于top-down的方法,往往先找到图片中所有行人,然后对每个行人做姿态估计,寻找每个人的关键点。 单人姿态估计往往可以被直接用于这个场景。 对于bottom-up,思路正好相反,先是找图片中所有parts (关键点),比如所有头部,左手,膝盖等。 然后把这些parts(关键点)组装成一个个行人。
对于测试集来讲,主要有COCO, 最近有新出一个数据集CrowdPose。下面是CPN算法在COCO上面的结果:

如果把姿态估计往视频中扩展的话,就有了人体姿态跟踪的任务。主要是针对视频场景中的每一个行人,进行人体以及每个关键点的跟踪。这个问题本身其实难度是很大的。相比行人跟踪来讲,人体关键点在视频中的temporal motion可能比较大,比如一个行走的行人,手跟脚会不停的摆动,所以跟踪难度会比跟踪人体框大。目前主要有的数据集是PoseTrack。
同时,如果把人体姿态往3D方面进行扩展,输入RGB图像,输出3D的人体关键点的话,就是3D人体姿态估计。这个有一个经典的数据集Human3.6M。最近,除了输出3D的关键点外,有一些工作开始研究3D的shape,比如数据集DensePose。长线来讲,这个是非常有价值的研究方向。3D人体姿态估计的结果图(来自算法a simple baseline)如下:
 Densepose算法的结果输出:
Densepose算法的结果输出:

过去
这部分主要用于描述在深度学习之前,我们是如何处理人体姿态估计这个问题。从算法角度来讲,这部分的工作主要是希望解决单人的人体姿态估计问题,也有部分工作已经开始尝试做3D的人体姿态估计。可以粗略的方法分成两类。
第一类是直接通过一个全局feature,把姿态估计问题当成分类或者回归问题直接求解 [1][2]。但是这类方法的问题在于精度一般,并且可能比较适用于背景干净的场景。第二类是基于一个graphical model,比如常用pictorial structure model。一般包含unary term,是指对单个part进行feature的representation,单个part的位置往往可以使用DPM (Deformable Part-based model)来获得。 同时需要考虑pair-wise关系来优化关键点之间的关联。基于Pictorial Structure,后续有非常多的改进,要么在于如何提取更好的feature representation [3][4], 要么在于建模更好的空间位置关系[5][6]。
总结一下,在传统方法里面,需要关注的两个维度是: feature representation以及关键点的空间位置关系。特征维度来讲,传统方法一般使用的HOG, Shape Context, SIFT等shallow feature。 空间位置关系的表示也有很多形式,上面的Pictorial structure model可能只是一种。
这两个维度在深度学习时代也是非常至关重要的,只是深度学习往往会把特征提取,分类,以及空间位置的建模都在一个网络中直接建模,所以不需要独立的进行拆解,这样更方便设计和优化。
现在
从2012年AlexNet开始,深度学习开始快速发展,从最早的图片分类问题,到后来的检测,分割问题。在2014年,[7]第一次成功引入了CNN来解决单人姿态估计的问题。因为当时的时代背景,整体网络结构比较简单,同时也沿用了传统骨架的思路。首先是通过slide-window的方式,来对每个patch进行分类,找到相应的人体关键点。因为直接sliding-window少了很多context信息,所以会有很多FP的出现。所以在pipeline上面加上了一个post-processing的步骤,主要是希望能抑制部分FP,具体实现方式是类似一个空间位置的模型。所以从这个工作来看,有一定的传统姿态估计方法的惯性,改进的地方是把原来的传统的feature representation改成了深度学习的网络,同时把空间位置关系当成是后处理来做处理。总体性能在当时已经差不多跑过了传统的姿态估计方法。
2014年的另外一个重要的进展是引入了MPII的数据集。此前的大部分paper都是基于FLIC以及LSP来做评估的,但是在深度学习时代,数据量还是相对偏少(K级别)。MPII把数据量级提升到W级别,同时因为数据是互联网采集,同时是针对activity来做筛选的,所以无论从难度还是多样性角度来讲,都比原来的数据集有比较好的提升。
一直到2016年,随着深度学习的爆发,单人姿态估计的问题也引来了黄金时间。这里需要重点讲一下两个工作,一个工作是Convolutional Pose Machine (CPM)[8],另外一个是Hourglass [9]。
CPM
CPM是CMU Yaser Sheikh组的工作,后续非常有名的openpose也是他们的工作。从CPM开始,神经网络已经可以e2e的把feature representation以及关键点的空间位置关系建模进去(隐式的建模),输入一个图片的patch, 输出带spatial信息的tensor,channel的个数一般就是人体关键点的个数(或者是关键点个数加1)。空间大小往往是原图的等比例缩放图。通过在输出的heatmap上面按channel找最大的响应位置(x,y坐标),就可以找到相应关键点的位置。
这种heatmap的方式被广泛使用在人体骨架的问题里面。这个跟人脸landmark有明显的差异,一般人脸landmark会直接使用回归(fully connected layer for regression)出landmark的坐标位置。这边我做一些解释。首先人脸landmark的问题往往相对比较简单,对速度很敏感,所以直接回归相比heatmap来讲速度会更快,另外直接回归往往可以得到sub-pixel的精度,但是heatmap的坐标进度取决于在spatial图片上面的argmax操作,所以精度往往是pixel级别(同时会受下采样的影响)。 但是heatmap的好处在于空间位置信息的保存,这个非常重要。一方面,这个可以保留multi-model的信息,比如没有很好的context信息的情况下,是很难区分左右手的,所以图片中左右手同时都可能有比较好的响应,这种heatmap的形式便于后续的cascade的进行refinement优化。另外一个方面,人体姿态估计这个问题本身的自由度很大,直接regression的方式对自由度小的问题比如人脸landmark是比较适合的,但是对于自由度大的姿态估计问题整体的建模能力会比较弱。相反,heatmap是比较中间状态的表示,所以信息的保存会更丰富。
后续2D的人体姿态估计方法几乎都是围绕heatmap这种形式来做的(3D姿态估计将会是另外一条路),通过使用神经网络来获得更好的feature representation,同时把关键点的空间位置关系隐式的encode在heatmap中,进行学习。大部分的方法区别在于网络设计的细节。先从CPM开始说起。

整个网络会有多个stage,每个stage设计一个小型网络,用于提取feature,然后在每个stage结束的时候,加上一个监督信号。中间层的信息可以给后续层提供context,后续stage可以认为是基于前面的stage做refinement。这个工作在MPII上面的结果可以达到88.5,在当时是非常好的结果。
Hourglass
在2016年的7月份,Princeton的Deng Jia组放出了另外一个非常棒的人体姿态估计工作,Hourglass。后续Deng Jia那边基于Hourglass的想法做了Associate Embedding,以及后续的CornerNet都是非常好的工作。
Hourglass相比CPM的最大改进是网络结构更简单,更优美。
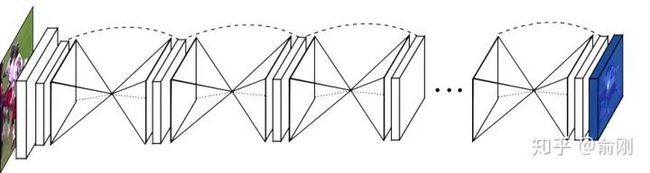
从上图可以看出,网络是重复的堆叠一个u-shape的structure.
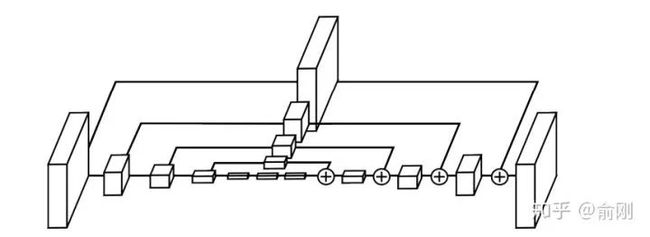
pipeline上面跟CPM很类似。只是结构做了修改。从MPII上的结果来看,也有明显的提升,可以达到90.9的PCKh。
这种u-shape的结构其实被广泛应用于现代化的物体检测,分割等算法中,同时结果上面来讲也是有非常好的提升的。另外,Hourglass这种堆多个module的结构,后续也有一些工作follow用在其他任务上面。
但是Hourglass也是存在一些问题的,具体可以看后续讲解的MSPN网络。
在CPM以及Hourglass之后,也有很多不错的工作持续在优化单人姿态估计算法,比如[10][11]。
2016年的下半年还出现了一个非常重要的数据集: COCO。这个时间点也是非常好的时间点。一方面,MPII已经出现两年,同时有很多非常好的工作,比如CPM, Hourglass已经把结果推到90+,数据集已经开始呈现出一定的饱和状态。另外一方面,物体检测/行人检测方面,算法提升也特别明显,有了很多很好的工作出现,比如Faster R-CNN和SSD。所以COCO的团队在COCO的数据集上面引入了多人姿态估计的标注,并且加入到了2016年COCO比赛中,当成是一个track。从此,多人姿态估计成为学术界比较active的研究topic。正如前面我在“问题”的部分描述的,多人姿态估计会分成top-down以及bottom-up两种模式。我们这边会先以bottom-up方法开始描述。
OpenPose
在2016年COCO比赛中,当时的第一名就是OpenPose [12]。 CMU团队基于CPM为组件,先找到图片中的每个joint的位置,然后提出Part Affinity Field (PAF)来做人体的组装。

PAF的基本原理是在两个相邻关键点之间,建立一个有向场,比如左手腕,左手肘。我们把CPM找到的所有的左手腕以及左手肘拿出来建立一个二分图,边权就是基于PAF的场来计算的。然后进行匹配,匹配成功就认为是同一个人的关节。依次类别,对所有相邻点做此匹配操作,最后就得到每个人的所有关键点。
在当时来讲,这个工作效果是非常惊艳的,特别是视频的结果图,具体可以参考Openpose的Github官网。在COCO的benchmark test-dev上面的AP结果大概是61.8。
Hourglass + Associative Embedding
在2016年比赛的榜单上面,还有另外一个很重要的工作就是Deng Jia组的Associative Embedding[13]。文章类似Openpose思路,使用bottom-up的方法,寻找part使用了Hourglass的方式来做。关键在于行人的组装上面,提出了Associative Embedding的想法。大概想法是希望对每个关键点输出一个embedding,使得同一个人的embedding尽可能相近,不同人的embedding尽可能不一样。
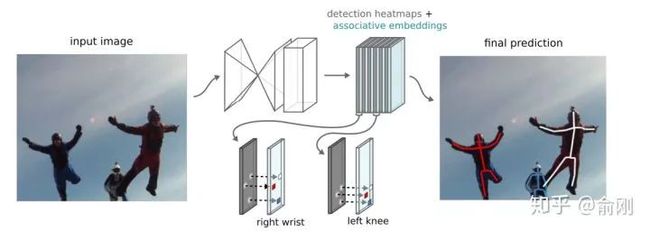
在COCO2016比赛后,这个工作持续的在提升,文章发表的时候,COCO test-dev上面的结果在65.5。
除了Openpose以及Associative Embedding之外,bottom-up还有一个工作非常不错,DeepCut[14]以及DeeperCut[15],他们使用优化问题来直接优化求解人的组合关系。
CPN
后面一部分章节我会重点围绕COCO数据集,特别是COCO每年的比赛来描述多人姿态估计的进展。虽然2016年bottom-up是一个丰富时间点,但是从2017年开始,越来的工作开始围绕top-down展开,一个直接的原因是top-down的效果往往更有潜力。top-down相比bottom-up效果好的原因可以认为有两点。首先是人的recall往往更好。因为top-down是先做人体检测,人体往往会比part更大,所以从检测角度来讲会更简单,相应找到的recall也会更高。其次是关键点的定位精度会更准,这部分原因是基于crop的框,对空间信息有一定的align,同时因为在做single person estimation的时候,可以获得一些中间层的context信息,对于点的定位是很有帮助的。当然,top-down往往会被认为速度比bottom-up会更慢,所以在很多要求实时速度,特别是手机端上的很多算法都是基于openpose来做修改的。不过这个也要例外,我们自己也有做手机端上的多人姿态估计,但是我们是基于top-down来做的,主要原因是我们的人体检测器可以做的非常快。
说完了背景后,在COCO2017年的比赛中,我们的CPN[16]一开始就决定围绕top-down的算法进行尝试。我们当时的想法是一个coarse-to-fine的逻辑,先用一个网络出一个coarse的结果(GlobalNet),然后再coarse的结果上面做refinement (RefineNet)。具体结果如下:
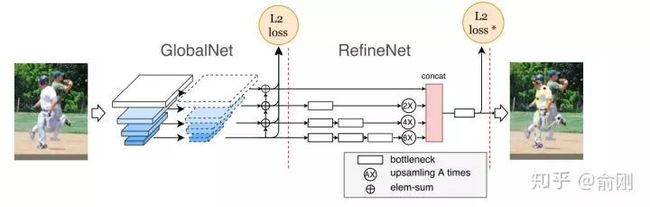
为了处理处理难的样本,我们在loss上面做了一定的处理,最后的L2 loss我们希望针对难的关键点进行监督,而不是针对所有关键点uniform的进行监督,所以我们提出了一个Hard keypoint mining的loss。这个工作最后在COCO test-dev达到了72.1的结果 (不使用额外数据以及ensemble),获得了2017年的COCO骨架比赛的第一名。
另外,这个工作的另外一个贡献是比较完备的ablation。我们给出了很多因素的影响。比如top-down的第一步是检测,我们分析了检测性能对最后结果的影响。物体检测结果从30+提升到40+(mmAP)的时候,人体姿态估计能有一定的涨点(1个点左右),但是从40+提升到50+左右,涨点就非常微弱了(0.1-0.2)。另外,我们对data augmentation,网络的具体结构设计都给出了比较完整的实验结果。另外,我们开始引入了传统的ImageNet basemodel (ResNet50)做了backbone,而不是像Openpose或者Hourglass这种非主流的模型设计结构,所以效果上面也有很好的提升。
MSPN
2018年的COCO比赛中,我们继续沿用top-down的思路。当时我们基于CPN做了一些修改,比如把backbone不停的扩大,发现效果提升很不明显。我们做了一些猜测,原来CPN的两个stage可能并没有把context信息利用好,单个stage的模型能力可能已经比较饱和了,增加更多stage来做refinement可能是一个解决当前问题,提升人体姿态估计算法uppper-bound的途径。所以我们在CPN的globalNet基础上面,做了多个stage的堆叠,类似于Hourglass的结构。

相比Hourglass结构,我们提出的MSPN[17]做了如下三个方面的改进。首先是Hourglass的每个stage的网络,使用固定的256 channel,即使中间有下采样,这种结构对信息的提取并不是很有益。所以我们使用了类似ResNet-50这种标准的ImageNet backbone做为每个stage的网络。另外,在两个相邻stage上面,我们也加入了一个连接用于更好的信息传递。最后,我们对于每个stage的中间层监督信号做了不同的处理,前面层的监督信号更侧重分类,找到coarse的位置,后面更侧重精确的定位。从最后效果上面来看,我们在COCO test-dev上面一举跑到了76.1 (单模型不加额外数据)。
HRNet
之前我们讲的很多人体姿态估计方面的工作,都在围绕context来做工作,如何更好的encode和使用这些context是大家工作的重点。到了2019年, MSRA wang jingdong组出了一个很好的工作,提出了spatial resolution的重要性。在这篇工作之前,我们往往会暴力的放大图片来保留更多信息,同时给出更精准的关键点定位,比如从256x192拉大到384x288。这样对效果提升还是很明显的,但是对于计算量的增加也是非常大的。 HRNet从另外一个角度,抛出了一个新的可能性:
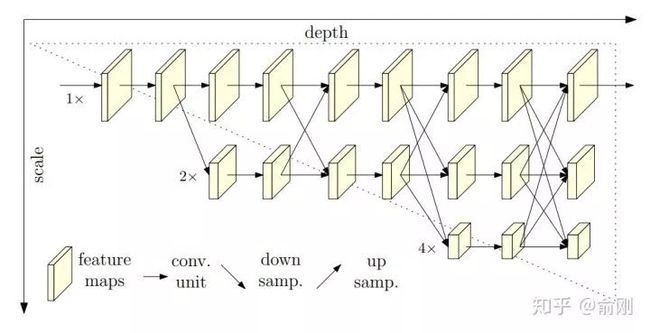
相比传统的下采样的网络结构,这里提出了一种新的结构。分成多个层级,但是始终保留着最精细的spaital那一层的信息,通过fuse下采样然后做上采样的层,来获得更多的context以及语义层面的信息(比如更大的感受野)。从结果上面来看,在COCO test-dev上面单模型可以达到75.5。
到此为止,我们重点讲述了几个多人姿态估计的算法,当然中间穿插了不少我们自己的私货。在多人姿态估计领域还有很多其他很好的工作,因为篇幅问题,这里我们就略过了。
回到2017年,MPII提出了一个新的数据集, PoseTrack,主要是希望能帮忙解决视频中的人体姿态估计的问题,并且在每年的ICCV或者ECCV上面做challenge比赛。 PoseTrack的数据集主要还是来源于MPII的数据集,标注风格也很相近。围绕PoseTrack这个任务,我们重点讲一个工作, Simple Baselines。
Simple Baselines
Simple Baselines [19]是xiao bin在MSRA的工作。提出了一种非常简洁的结构可以用于多人姿态估计以及人体姿态估计的跟踪问题。这里重点讲一下对于PoseTrack的处理方法:
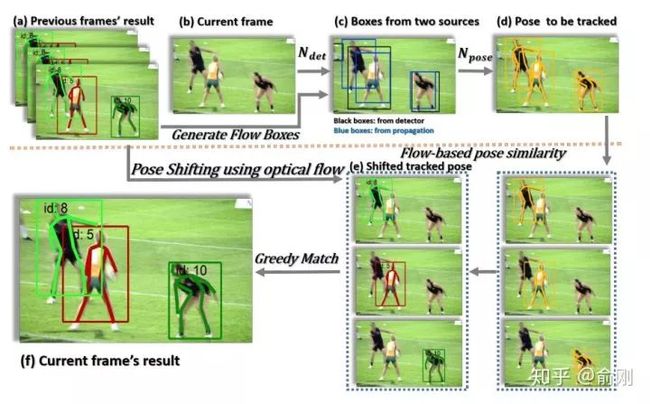
这里有两个细节,首先是会利用上一帧的检测结果,merge到新的一帧,避免检测miss的问题。另外,在两帧间,会使用OKS based相似度来做人体的关联,而不是只是简单的使用框的overlap,这样可以更好的利用每个关键点的temporal smooth的性质。从结果上面来看,这个方法也获得了PoseTrack2018比赛的第一名。
到目前位置,我们描述了单人的姿态估计,多人的姿态估计,以及简单讲了一下视频中的人体姿态跟踪的问题。最后,我们讲一下3D人体姿态估计的问题,这个我觉得这个是目前非常active的研究方向,也是未来的重要的方向。
3D Skeleton
3D人体姿态估计目前我们先限制在RGB输入数据的情况下,不考虑输入数据本身是RGBD的情况。我们大概可以把这个问题分成两个子问题:第一个是出人体的3D关键点。相比之前的2D关键点,这里需要给出每个点的3D位置。 另外一种是3D shape,可以给出人体的3D surface,可以认为是更dense的skeleton信息(比如Densepose, SMPL模型)。
先从3D关键点说起。主要的方法可以分成两类,第一类是割裂的考虑。把3D skeleton问题拆解成2D人体姿态估计,以及从2D关键点预测3D关键点两个步骤。 另外一类是joint的2D以及3D的姿态估计。
大部分的基于深度学习的3D人体骨架工作是从2017年开始的,主要的上下文是因为2D人体姿态估计中CPM以及Hourglass给出了很好的效果,使得3D Skeleton成为可能。
我们先从3D跟2D skeleton割裂的算法开始说起。首先从2017年deva Ramanan组的一个非常有意思的工作【20】开始说起,3D Human Pose Estimation = 2D Pose Estimation + Matching。从名字可以看出,大致的做法。首先是做2D的人体姿态估计,然后基于Nearest neighbor最近邻的match来从training data中找最像的姿态。2D的姿态估计算法是基于CPM来做的。3D的match方法是先把training data中的人体3d骨架投射到2D空间,然后把test sample的2d骨架跟这些training data进行对比,最后使用最相近的2d骨架对应的3D骨架当成最后test sample点3D骨架。当training数据量非常多的时候,这种方法可能可以保证比较好的精度,但是在大部分时候,这种匹配方法的精度较粗,而且误差很大。
随后,也在17年,另外一个非常有意思的工作【21】发表在ICCV2017。同样,从这个工作的名字可以看出,这个工作提出了一个比较simple的baseline,但是效果还是非常明显。方法上面来讲,就是先做一个2d skeleton的姿态估计,方法是基于Hourglass的,文章中的解释是较好的效果以及不错的速度。 基于获得的2d骨架位置,后续接入两个fully connected的操作,直接回归3D坐标点。这个做法非常粗暴直接,但是效果还是非常明显的。在回归之前,需要对坐标系统做一些操作。
同样,从2017年的ICCV开始,已经有工作【22】开始把2D以及3d skeleton的估计问题joint一起来做优化。这样的好处其实是非常明显的。因为很多2d数据对于3d来讲是有帮助的,同时3D姿态对于2d位置点估计也能提供额外的信息辅助。2D的MPII, COCO数据可以让算法获得比较强的前背景点分割能力,然后3D的姿态估计数据集只需要关注前景的3D骨架估计。这也是目前学术界数据集的现状。从实际效果上面来讲,joint training的方法效果确实也比割裂的train 2d以及3d skeleton效果要好。
从2018年开始,3D skeleton开始往3d shape发展。原先只需要知道joint点的3D坐标位置,但是很多应用,比如人体交互,美体,可能需要更dense的人体姿态估计。这时候就有了一个比较有意思的工作densePose 【23】。这个工作既提出来一个新的问题,也包含新的benchmark以及baseline。相比传统的SMPL模型,这个工作提出了使用UV map来做估计(同时间也有denseBody类似的工作),可以获得非常dense的3d姿态位置,等价于生成了3d shape。当然,从3d shape的角度来讲,有很多非常不错的工作,这里就不做重点展开。
最后讲一下3d人体姿态估计目前存在的问题。我个人认为主要是benchmark。目前最常使用的human 3.6M实际上很容易被overfit,因为subjects数量太小(实际训练样本只有5-6人,depend on具体的测试方法,测试样本更少)。同时,是在受限的实验室场景录制,跟真实场景差异太大,背景很干净,同时前景的动作pose也比较固定。当然,3d skeleton的数据集的难度非常大,特别是需要采集unconstrained条件下面的数据。目前也有一些工作在尝试用生成的数据来提升结果。
应用
最后,讲了这么多的人体姿态估计,我们最后说一下人体姿态估计有什么用,这里的人体姿态估计是一个广义的人体姿态估计,包含2D/3D等。
首先的一个应用是人体的动作行为估计,要理解行人,人体的姿态估计其实是一个非常重要的中间层信息。目前有蛮多基于人体姿态估计直接做action recogntion的工作,比如把关键点当成graph的节点,然后是使用graph convolution network来整合各种信息做动作分类。我博士的研究课题是action recognition,我读完四年博士的一个总结是action这个问题,如果需要真正做到落地,人体姿态估计算法是必不可少的组成部分。
第二类应用是偏娱乐类的,比如人体交互,美体等。比如可以通过3d姿态估计来虚拟出一个动画人物来做交互,使用真实人体来控制虚拟人物。另外比如前一段时间比较火热的瘦腰,美腿等操作背后都可能依赖于人体姿态估计算法。
第三类应用是可以做为其他算法的辅助环节,比如Person ReID可以基于人体姿态估计来做alignment,姿态估计可以用来辅助行人检测,杀掉检测的FP之类的。
未来
深度学习带来了学术界以及工业界的飞速发展,极大的提升了目前算法的结果,也使得我们开始关注并尝试解决一些更有挑战性的问题。
下面的几点我是侧重于把人体姿态估计真正落地到产品中而展开的。当然也可以换个维度考虑更长线的研究发展,这个可能希望以后有机会再一起讨论。
Data Generation
我觉得这个是一个非常重要的研究方向,不管是对2d还是3d。以2d为例,虽然目前数据量已经非常的大,比如COCO数据,大概有6w+的图片数据。但是大部分pose都是正常pose,比如站立,走路等。对于一些特殊pose,比如摔倒,翻越等并没有多少数据。或者可以这么理解,这些数据的收集成本很高。如果我们可以通过生成数据的方法来无限制的生成出各种各样的数据的话,这个对于算法的提升是非常的关键。虽然目前GAN之类的数据生成质量并不高,但是对于人体姿态估计这个问题来讲其实已经够了,因为我们不需要清晰真实的细节,更多的是需要多样性的前景(不同着装的人)和pose。但是数据生成的方式对于人体姿态估计本身也有一个非常大的挑战,这个可以留做作业,感兴趣的同学可以在留言区回复。
Crowd的问题
这个问题其实是行人检测的问题。目前市面上没有能针对拥挤场景很work的行人检测算法。这个问题的主要瓶颈在于行人检测的一个后处理步骤:NMS (Non-maximum suppression)。这个其实是从传统物体检测方法时代就有的问题。因为目前大部分算法不能区分一个行人的两个框还是两个不同行人的两个框,所以使用NMS来基于IOU用高分框抑制低分框。这个问题在传统的DPM以及ACF时代问题并不突出,因为当时算法精度远没有达到需要考虑NMS的问题。但是随着技术的进步,目前NMS已经是一个越来越明显的瓶颈,或者说也是行人检测真正落地的一个很重要的障碍。最近我们提出了一个新的数据集CrowdHuman,希望引起大家对于遮挡拥挤问题的关注。从算法上面来讲,最近也陆续开始由蛮多不错的工作在往这个方向努力,但是离解决问题还是有一定的距离。回到人体姿态估计这个问题,目前top-down方法依赖于检测,所以这个问题避免不了。 bottom-up可能可以绕开,但是从assemble行人的角度,拥挤场景这个问题也非常有挑战。
Multi-task Learning
刚刚我们讲到,2D以及3D人体姿态估计可以联合training,从而提升整体结果。同样,其实可以把人体姿态估计跟人体相关的其他任务一起联合做数据的标注以及训练。这里可以考虑的包括人体分割(human segmentation),人体部位的parse (human parse)等。可以这么理解,human seg本身的标注可以认为是多边形的标注,我们可以在多边形轮廓上面进行采点,这几个任务可以很自然的联合起来。人体多任务的联合训练我觉得对于充分理解行人是非常有意义的,同时也可以提升各个任务本身的精度。当然潜在的问题是数据标注的成本会增加。另外可以考虑的是跨数据集的联合training,比如某个数据集只有skeleton标注,有个数据集只有seg标注等,这个问题其实也是工业界中很常见的一个问题。
Speed
速度永远是产品落地中需要重点考虑的问题。目前大部分学术paper可能都是在GPU做到差不多实时的水平,但是很多应用场景需要在端上,比如手机的ARM上面进行实时高效的处理。我们之前有尝试过使用我们自己的ThunderNet [24]做人体检测,然后拼上一个简化版的CPN来做人体姿态估计,可以做到端上近似实时的速度,但是效果跟GPU上面还是有一定差距。所以速度的优化是非常有价值的。
UnConstrained 3D skeleton Benchmark
这个我上面也有提到,3D人体姿态估计急需一个更大更有挑战的benchmark来持续推动这个领域的进步。随着很多3d sensor的普及,我理解我们不一定需要依赖传统的多摄像头的setting来做采集,这个使得我们能获得更真实,更wild的数据。
后记
这里只是从我个人的角度列了一些人体姿态估计的重要工作,当然其中可能miss了很多细节,很多重要的文献,但是我希望这个是一个引子,吸引更多的同学来一起投入这个方向,一起来推动这个领域的落地。因为我时刻相信人体姿态估计的进步,将会是我们真正从视觉角度理解行人的非常关键的一步。
最后,希望借此也感谢一下我们R4D中做人体姿态估计的同学,感谢志成,逸伦,文博,斌一,琦翔,禹明,天孜,瑞豪,正雄等等,虽然可能有些同学已经奔赴各地,但是非常感谢各位的付出也怀念和大家一起战斗的时光????。
Reference
[1] Randomized Trees for Human Pose Detection, Rogez etc, CVPR 2018
[2] Local probabilistic regression for activity-independent human pose inference, Urtasun etc, ICCV 2009
[3] Strong Appearance and Expressive Spatial Models for Human Pose Estimation, Pishchulin etc, ICCV 2013
[4] Pictorial Structures Revisited: People Detection and Articulated Pose Estimation, Andriluka etc, CVPR 2009
[5] Latent Structured Models for Human Pose Estimation, Ionescu etc, ICCV 2011
[6] Poselet Conditioned Pictorial Structures, Pishchulin etc, CVPR 2013
[7] Learning Human Pose Estimation Features with Convolutional Networks, Jain etc, ICLR 2014
[8] Convolutional Pose Machines, Wei etc, CVPR 2016
[9] Stacked Hourglass Networks for Human Pose Estimation, Newell etc, ECCV 2016
[10] Multi-Context Attention for Human Pose Estimation, Chu etc, CVPR 2017
[11] Deeply Learned Compositional Models for Human Pose Estimation, ECCV 2018
[12] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields, Cao etc, CVPR 2017
[13] Associative Embedding: End-to-End Learning for Joint Detection and Grouping, Newell etc, NIPS 2017
[14] DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation, Pishchulin etc, CVPR 2016
[15] DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model, Insafutdinov, ECCV 2016
[16] Cascaded Pyramid Network for Multi-Person Pose Estimation, Chen etc, CVPR 2017
[17] Rethinking on Multi-Stage Networks for Human Pose Estimation, Li etc, Arxiv 2018
[18] Deep High-Resolution Representation Learning for Human Pose Estimation, Sun etc, CVPR 2019
[19] Simple Baselines for Human Pose Estimation and Tracking, Xiao etc, ECCV 2018
[20] 3D Human Pose Estimation = 2D Pose Estimation + Matching, Chen etc, CVPR 2017
[21] A simple yet effective baseline for 3d human pose estimation, Martinez, ICCV 2017
[22] Compositional Human Pose Regression, Sun etc, ICCV 2017
[23] Densepose: Dense Human Pose Estimation in the Wild, Guler etc, CVPR 2018
[24] ThunderNet: Toward Real-time Generic Object Detection, Qin etc, ICCV 2019
传送门
欢迎大家关注如下 旷视研究院 官方微信号????
