6个步骤,告诉你如何用树莓派和机器学习DIY一个车牌识别器!(附详细分析)...

作者 | Robert Lucian Chiriac
翻译 | 天道酬勤,编辑 | Carol
出品 | AI科技大本营(ID:rgznai100)
几个月前,作者开始考虑让汽车能够具备检测和识别物体的能力。他很喜欢这个主意,因为已经见识到了特斯拉的能力,并且虽然不能立即购买特斯拉(Model 3看起来越来越有吸引力了),但他认为会尽力实现自己的梦想。
预测视频的GIF,检查结果部分,
视频地址:https://www.youtube.com/watch?v=gsYEZtecXlA
所以,他做到了。
下面,作者记录了项目中的每个步骤。

确定项目范围
首先要考虑这种系统应该具备的功能。如果说作者这辈子学到了什么,那就是从小做起永远是最好的策略:循序渐进。所以,除了显而易见的车道保持任务(每个人都已经做过了)之外,作者想到的只是在开车时清楚地识别车牌。这个识别过程包括两个步骤:
检测车牌;
识别每个车牌边框内的文本。
如果我们能够做到这一点,那么进行其他任务应该相当容易(如确定碰撞风险、距离等)。也许甚至可以创建一个环境的向量空间表示,这可能是一个很好的选择。
在过多担心细节之前,我们需要知道以下两点:
一种将未标记图像作为输入并检测车牌的机器学习模型。
某种硬件。简而言之,需要一个能链接到一个或多个摄像机的计算机系统来查询我们的模型。
首先,我们来着手建立正确的对象检测模型。

选择正确的模型
经过认真研究,作者决定采用以下机器学习模型:
YOLOv3——这是迄今为止最快的模型,其mAP可与其他先进模型相媲美,该模型用于检测物体。
文字检测器——用于检测图像中的文字。
CRNN——基本上是循环卷积神经网络(CNN)模型。卷积神经网络必须是循环的,因为它需要能够将检测到的字符按正确的顺序排列来形成单词。
这三个模型将如何协同工作的呢?下面是操作流程:
首先,YOLOv3模型在从摄像机接收的每一帧中检测每个牌照的边界框。建议不要非常精确地预测边界框,包含比检测到的物体更宽的边界比较好。如果太窄,则可能会影响后续流程的性能。这与下面的模型相辅相成。
CRAFT文字检测器从YOLOv3接收裁剪的车牌。现在,如果裁剪过的帧太窄,那么很有可能会遗漏部分车牌文字,从而预测会失败。但是,当边界框更大时,我们可以让CRAFT模型检测字母的位置。这给了我们每个字母非常精确的位置。
最后,我们可以将CRAFT中每个单词的边界框传递给我们的CRNN模型,来预测实际单词。
有了的基本模型架构后,我们便可以将其转移到硬件上了。

设计硬件
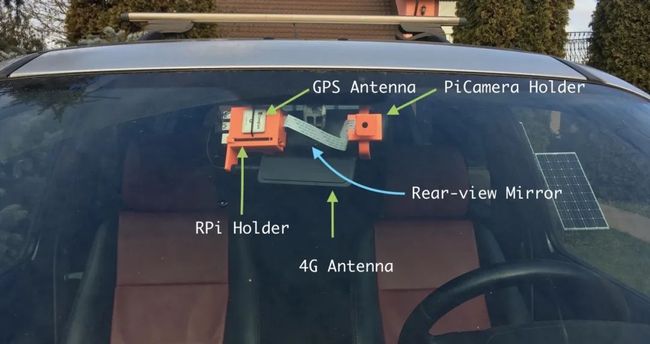
我们需要低功耗的硬件,比如树莓派(Raspberry Pi)。它具有足够的计算能力,可以用可观的帧速率对帧进行预处理,并且具有Pi摄像头。Pi摄像头是树莓派的实际相机系统。它有一个很棒的库,而且非常成熟。
至于联网访问,我们可以提供一个EC25-E的4G接入,其中还嵌入了一个GPS模块。有关树莓派接入4G网络的文章可阅读此处:
https://www.robertlucian.com/2018/08/29/mobile-network-access-rpi/。
我们从外壳开始,将其挂在汽车的后视镜上应该可以很好地工作,我们来设计一个由两部分组成的支撑结构:
树莓派+GPS模块+4G模块将放在后视镜的一侧。在EC25-E模块上可以查看上述文章,来查看所选择的GPS和4G天线。
另一方面,通过一个带有球形接头的手臂来给Pi相机固定方向。
这些支持或外壳使用可靠的Prusa i3 MK3S 3D打印机打印。

图1 树莓派+4G/GPS防护罩的外壳
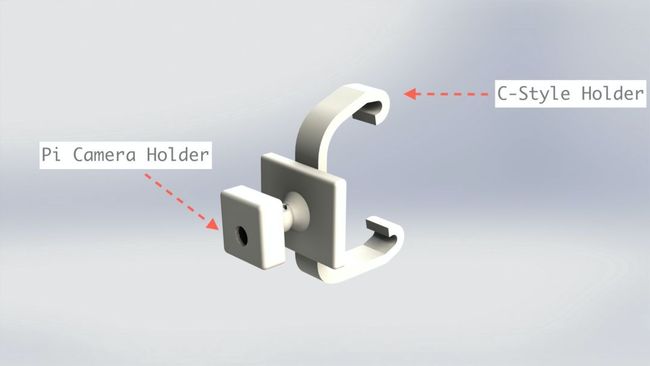
图2 带有球形接头用于定向的Pi摄像机支架
图1和图2显示了呈现时的结构。注意,C型支架是可插拔的,因此树莓派的外壳和Pi相机的支持没有与支架一起打印出来。它们有一个插座,插座上插着支架。如果有读者决定复制该项目,这将非常有用。你们只需要调整后视镜支架即可在汽车上工作。目前,该支架在一款路虎自由职业者的车上运作良好。

图3 Pi 相机支撑结构的侧视图
图4 Pi相机的支撑结构和RPi支架的前视图
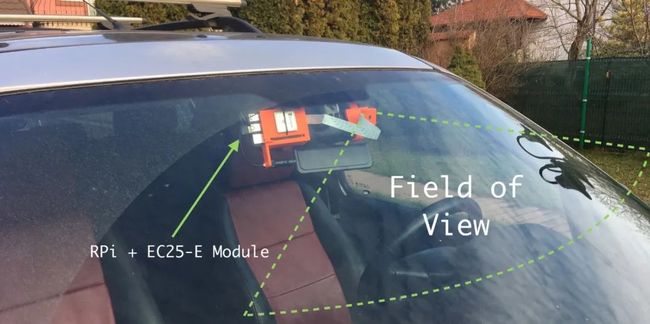
图5 摄像机视野的富有想象力的表示

图6 包含4G / GPS模块、Pi摄像头和树莓派的嵌入式系统的特写照片
显然,这些建模需要花费一些时间,需要进行几次迭代才能得到坚固的结构。使用PETG材料层高度为200微米,PETG可以在80-90摄氏度内很好地工作,并且对紫外线辐射的抵抗力很强,虽然不如ASA好,但强度很高。
这是在SolidWorks中设计的,因此所有的SLDPRT / SLDASM文件以及所有STL和gcode都可以在下方链接找到,也可以使用它们来打印你的版本。
https://www.dropbox.com/sh/fw16vy1okrp606y/AAAwkoWXODmoaOP4yR-z4T8Va?dl=0

训练模型
一旦有了硬件,便可以开始训练模型。
不出所料,最好不要重新发明轮子,并尽可能多地重复使用别人的工作。这就是迁移学习的全部内容——利用来自其他超大型数据集的分析。几天前作者读到过一个关于迁移学习非常相关案例的文章,在文章中,它谈到了哈佛医学院的一个附属团队,该团队能够对模型进行微调,来预测“从胸部X光片得出的长期死亡率,包括非癌性死亡”。他们只有一个仅50000张标签图像的小型数据集,但是他们使用的预训练模型(Inception-v4)训练了大约1400万张图像。这比最初的模型花费的训练时间和金钱较少,然而达到的准确性仍然很高。
文章地址:
https://medium.com/m/global-identity?redirectUrl=https%3A%2F%2Ftowardsdatascience.com%2Fdeep-learning-isnt-hard-anymore-26db0d4749d7
作者也打算这样做。
YOLOv3
在网上可以查到很多经过预先训练的车牌模型,但没有预期的那么多,但是其中有一个训练过约3600张车牌图像。它虽然不多,但也比什么都没有强。此外,它还使用Darknet的预训练模型进行了训练。我们可以用,这是那个模型:
https://github.com/ThorPham/License-plate-detection
作者用VOTT注释了收集的车架(当然还有车牌)。最终创建了一个由534张图像组成的小型数据集,并带有标记为车牌的边框。数据集链接如下:
https://github.com/RobertLucian/license-plate-dataset
然后,作者找到了YOLOv3网络的Keras实现。用它来训练数据集,然后将模型预发布到这个仓库中,以便其他人也可以使用它。在测试集中获得的mAP为90%,考虑到数据集非常小,这已经很好了。
CRNN&CRNN
在无数次尝试寻找一种好的网络来识别文本之后,作者偶然发现了keras-ocr,它是CRAFT和CRNN的包和灵活的版本。并且还附带了它们的预训练模型。这非常好用,作者决定不对模型进行微调,并保持原样。
最重要的是,使用keras-ocr预测文本非常简单。基本上只是几行代码。查看它们的主页,了解其操作方法:
https://github.com/faustomorales/keras-ocr。

部署我的车牌识别器模型
这里可以使用两种主要的模型部署方法:
在本地进行所有推理。
在云中进行推理。
这两种方法都具有挑战性。第一个意味着有一个庞大的“大脑”计算机系统,这既复杂又昂贵。第二个问题是有关延迟和基础架构方面的挑战,特别是使用GPU进行推理。
在本研究中,作者偶然发现了一个名为cortex的开源项目。它对游戏来说是很新的东西,但是作为AI开发工具的下一个发展方向,确实很有意义。
基本上,cortex是一个将机器学习模型部署为生产web服务的平台。这意味着我们可以专注于自己的应用程序,而把其余的事情留给cortex去处理。在这种情况下,它在AWS上完成所有配置,而我们唯一需要做的就是使用模板模型来编写预测器。非常方便,只需为每个模型编写几十行代码。
这是从GitHub存储库中提取的终端中的cortex:https://github.com/cortexlabs/cortex 如果那不是漂亮和简单,不知道如何该怎么称呼:

来源: GitHubCortex
由于自动驾驶仪不使用此计算机视觉系统,延迟对我们而言并不重要,因此我们可以使用cortex。如果它是自动驾驶系统的一部分,那么使用通过云提供商提供的服务并不是一个好主意,至少在现在不是。
部署带有cortex的机器学习模型只需以下两点:
定义cortex.yaml文件,这是我们API的配置文件。每个API都会处理一种任务。我们分配的yolov3 API用于检测给定帧上车牌的边界框,crnn API用于使用CRAFTtext检测器和CRNN预测车牌号。
定义每个API的预测变量。基本上,在cortex中定义一个特定类别的预测方法以接收有效负载(所有servypart已由平台处理),使用有效负载预测结果,然后返回预测。就是这么简单!
这里有一个经典iris数据集的预测器示例,但没有详细介绍作者是如何做到这一点的(并使本文保持适当的长度)。这两个api的cortex实现的链接可以在他们的资源库中找到:这个项目的所有其他资源都在这篇文章的末尾。
https://github.com/cortexlabs/cortex/tree/master/examples/tensorflow/license-plate-reader

然后进行预测,你只需像这样使用curl:

预测响应看起来像是“setosa”。非常简单!

开发客户端
通过cortex处理我们的部署,我们可以继续设计客户端,这是很棘手的部分。
我们可以考虑以下架构:
以适当的分辨率(800x450或480x270)从Pi相机以30 FPS的速度收集帧,并将每个帧放入一个公共队列。
在一个单独的过程中,我们从队列中拉出帧,并将其分发给不同线程上的多个工作线程。
每个工作线程(或称之为推理线程)都会向我们的cortexAPI发出API请求。首先,向我们的yolov3API发送请求,然后,如果检测到任何牌照,则向我们的crnn API发送另一个请求,其中包含一批裁剪的牌照。该响应会包含文本格式的预测车牌号。
将每个检测到的车牌(包含或不包含识别的文本)推入另一个队列,最终将其广播到浏览器页面。同时,还将车牌号预测推送到另一个队列,稍后将其保存到磁盘(csv格式)。
广播队列将接收一组无序帧。它的使用者的任务是通过在每次向客户端广播新帧时将它们放置在非常小的缓冲区(几帧大小)中来对它们进行重新排序。该使用者正在另外一个进程上运行。该使用者还必须尝试将队列上的大小保持为指定值,以便可以以一致的帧速率(即30 FPS)显示帧。显然,如果队列大小减小,则帧速率的减少是成比例的,反之亦然,当队列大小增加时,成比例的增加。最初,作者想实现一个迟滞功能,但是意识到它会给流带来非常起伏的感觉。
同时,在主进程中还有另一个线程正在运行,它从另一个队列和GPS数据中提取预测。当客户端收到终止信号时,预测、GPS数据和时间也将转储到csv文件中。
下面是与AWS上的云API相关的客户端流程图。

图7 客户端流程图以及随cortex设置的云API
在我们的案例中,客户端是树莓派,推理请求发送到的树莓派和云API由cortex在亚马逊网络服务AWS上提供。
客户端的源代码也可以在其GitHub存储库上进行复制:
https://github.com/RobertLucian/cortex-license-plate-reader-client。
我们必须克服的一个特殊挑战是4G的带宽。最好减少此应用程序所需的带宽,来减轻可能出现的挂机或对可用数据的过度使用。作者决定在Pi相机上使用非常低的分辨率:480x270(我们可以使用较小的分辨率,因为Pi相机的视野非常窄,因此我们仍然可以轻松识别车牌)。即使在此分辨率下,帧的JPEG大小在10MBits时仍约为100KB。将其乘以每秒30帧,就可以得到3000KB,大约为24Mb / s,而且没有HTTP开销——这太大了。
相反,作者做了以下技巧:
将宽度减小到416像素,这正是YOLOv3模型将图像调整大小的宽度。规模显然保持不变。
将图像转换为灰度。
删除了图像顶部的45%部分。他们的想法是,由于汽车不在飞行中,因此牌照不会出现在车架的顶部。据作者所知,裁剪出45%的图像不会影响预测器的性能。
再次将图像转换为JPEG,但质量较低。
结果帧的大小约为7–10KB,这非常好。这相当于2.8Mb / s。但是加上所有的开销,它大约是3.5Mb / s(包括响应)。
对于crnn API,即使没有应用压缩技巧,裁剪的车牌也不会花费太多。它们的大小约为2-3KB。
总而言之,要以30FPS的速度运行,推理API所需的带宽约为6Mb / s。这个数字是我们可以接受的。
 结果
结果
通过观看视频得知,本项目成功了,视频地址:https://youtu.be/gsYEZtecXlA。
上面的例子是通过cortex运行推理的实时示例。我需要大约20个配备GPU的实例才能顺利运行。根据群集的延迟,你可能需要更多或更少的实例。从捕获帧到将其广播到浏览器窗口之间的平均等待时间约为0.9秒,考虑到推断发生在很远的地方,这非常棒,这让我们感到惊讶。
文本识别部分可能不是最好的,但至少可以证明这一点,通过提高视频的分辨率,减小摄像机的视场或对其进行微调,可以使精度更高。
至于较高的GPU数量,可以通过优化减少。例如,将模型转换为使用混合/全半精度(FP16 / BFP16)。一般而言,让模型使用混合精度将对精度产生最小的影响,因此我们不会做太多的权衡。
T4和V100 GPU具有特殊的张量内核,这些张量内核被设计为在半精度类型的矩阵乘法上超快。在T4上,半精度加速比单精度运算的速度提高了约8倍,而在V100上,提高了10倍。这是一个数量级的差异。这意味着已转换为使用单精度/混合精度的模型可以最多减少8倍的时间来进行推理,而在V100上则分别减少十分之一的时间。
作者没有将模型转换为使用单精度/混合精度,因为这超出了该项目的范围。就作者而言,这只是一个优化问题。作者很可能会在0.14版的cortex版本发布时使用它(具有真正的多进程支持和基于队列的自动缩放功能),因此我们也可以利用多进程的Web服务器。
总而言之,如果实施了所有优化措施,将集群的大小从20个配备GPU的实例减少到一个实例实际上是可行的。如果进行了适当的优化,甚至不可能最大化配备单个GPU的实例。
为了使成本更加可以接受,在AWS上使用弹性推理可以将成本降低多达75%,这非常好。形象地说,你可能拥有一个管道来实时处理一个流。不幸的是,目前Cortex尚不支持弹性推理,但由于它已经应用在雷达上了,因此我们可以在不久的将来看到它的支持。
注意:YOLOv3和CRNN模型可以通过在更大的数据集(大约50–100k样本)上进行微调来进行很多改进。到那时,甚至可以进一步减小帧的大小以减少数据使用量,而不会降低精度:“补偿某处以便能够从其他地方取走”。结合所有这些模型转换为使用半精度类型(可能还有弹性推理),可以构成一个非常高效/具有成本效益的推理机。
 更新
更新
有了支持Web服务器多进程工作程序的cortex版本0.14,我们能够将yolov3 API和crnn API的GPU实例数量从8个减少到2个(在CRNN和 CRAFT模型)从12降低到10。这实际上意味着实例总数减少了40%,这是非常不错的收益。所有这些实例都配备了单个T4 GPU和4个vCPU。
我们发现计算量最大的模型是CRAFT模型,该模型建立在具有约1.38亿权重的VGG-16模型的基础上。请记住,由于一帧中可能检测到多个车牌,因此通常每个帧都需要进行多个推断。这极大地增加了它的计算要求。从理论上讲,应消除CRAFT模型,而应改进(微调)CRNN模型以更好地识别车牌。这样,crnn API可以缩小很多,最多可以缩小到1或2个实例。

结论(以及5G如何适配这些)
目前,很多设备开始越来越依赖于云计算,尤其是对于计算能力有限的边缘设备。
而且,由于目前正在部署5G,因此从理论上讲,它应该使云距离这些计算受限的设备更近。因此,云的影响力应随之增长。5G网络越可靠,对于将所谓的关键任务(即自动驾驶汽车)的计算卸载到云上的信心就越大。
我们可以在这个项目中一直学习的另一件事是,随着简化的平台的出现,事情变得如此简单,这些简化的平台用于在云中部署机器学习模型。5年前,这将是一个很大的挑战:但是现在,一个人可以在相对较短的时间内完成很多工作。
参考资源
可在此处找到3D打印支架的所有SLDPRT / SLDASM / STL / gcode :
https://www.dropbox.com/sh/fw16vy1okrp606y/AAAwkoWXODmoaOP4yR-z4T8Va?dl=0
该项目的客户端实施可在此处找到:
https://github.com/RobertLucian/cortex-license-plate-reader-client
该项目的cortex实现在这里找到:
https://github.com/cortexlabs/cortex/tree/master/examples/tensorflow/license-plate-reader
可在此处找到Keras的YOLOv3模型库:
https://github.com/experiencor/keras-yolo3
可在此处找到CRAFT文本检测器+CRNN文本识别器的库:
https://github.com/faustomorales/keras-ocr
可在此处找到欧洲车牌的数据集(由作者的Pi相机捕获的534个样本组成):
https://github.com/RobertLucian/license-plate-dataset
可在此处找到Keras(license_plate.h5)和SavedModel(yolov3文件夹/zip)格式的YOLOv3模型:
https://www.dropbox.com/sh/4ltffycnzfeul01/AACe85GoIzlmjEnIhuh5JQPma?dl=0
如果有不清楚的地方或其他意见,欢迎评论告诉我们。
原文:https://towardsdatascience.com/i-built-a-diy-license-plate-reader-with-a-raspberry-pi-and-machine-learning-7e428d3c7401
(*本文由 AI 科技大本营编译,转载请联系微信1092722531)
【end】
◆
精彩推荐
◆
《原力计划【第二季】- 学习力挑战》正式开始!
即日起至 3月21日,千万流量支持原创作者更有专属【勋章】等你来挑战

推荐阅读
0.052秒打开100GB数据?这个Python开源库这样做数据分析
这款“狗屁不通”文章生成器火了,效果确实比GPT 2差太远
淘宝千万级并发架构的十四次演进
“华为搜索”正海外内测;苹果5亿美元和解“降速门”;Firefox隐藏HTTPS
血亏 1.5 亿元!微盟耗时 145 个小时弥补删库
Libra为何而生?Facebook为何要给 Libra创建Move语言?Calibra技术负责人给出了回答

你点的每个“在看”,我都认真当成了AI