数据结构之二分搜索树
文章目录
- 二叉树
- 二分搜索树 Binary Search Tree
- 手写一个二分搜索树
- 二分搜索树的前序遍历
- 二分搜索树的中序遍历
- 二分搜索树的后序遍历
- 前序遍历的非递归算法
- 二分搜索树的层序遍历
- 二分搜索树删除节点
- 两个数组的交集问题
- 两个数组的交集 II
- 树结构本身是一种天然的组织结构
- 为什么要用树结构
高效
二叉树
- 和链表一样,动态数据结构
class Node{
E e;
Node left;
Node right;
}
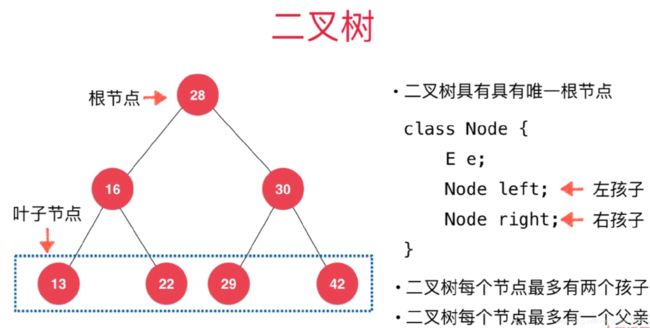
- 二叉树具有天然递归结构
- 每个节点的左子树也是二叉树
- 每个节点的右子树也是二叉树
- 二叉树不一定是“满”的
- 一个节点也是二叉树
- 空(null)也是二叉树
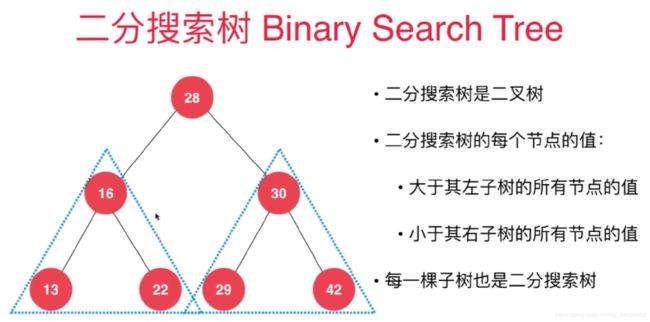
二分搜索树 Binary Search Tree
- 二分搜索树是二叉树
- 二分搜索树的每个节点的值:
- 大于其左子树的所有节点的值
- 小于其右子树的所有节点的值
- 每一颗子树也是二分搜索树
- 存储的元素必须有可比较性
手写一个二分搜索树
这里我们底层的数据结构采用集合,因为它和二分搜索树有 不能添加重复元素 的共性。
public class BST<E extends Comparable<E>> {
private class Node {
public E e;
public Node left, right;
public Node(E e) {
this.e = e;
left = null;
right = null;
}
}
private Node root;
private int size;
public BST(){
root = null;
size = 0;
}
public int size(){
return size;
}
public boolean isEmpty(){
return size == 0;
}
// 向二分搜索树中添加新的元素e
public void add(E e){
// 优化后的方法不需要判断null了
// if(root == null){
// root = new Node(e);
// size ++;
// }
// else
// add(root, e);
root = add(root, e);
}
// 向以node为根的二分搜索树中插入元素e,递归算法
// 优化前方法
// private void add(Node node, E e){
// if(e.equals(node.e))
// return;
// else if(e.compareTo(node.e) < 0 && node.left == null){
// node.left = new Node(e);
// size ++;
// return;
// }
// else if(e.compareTo(node.e) > 0 && node.right == null){
// node.right = new Node(e);
// size ++;
// return;
// }
//
// if(e.compareTo(node.e) < 0)
// add(node.left, e);
// else //e.compareTo(node.e) > 0
// add(node.right, e);
// }
// 向以node为根的二分搜索树中插入元素e,递归算法
// 返回插入新节点后二分搜索树的根
// 优化后方法
private Node add(Node node, E e){
if (node == null){
size ++;
return new Node(e);
}
if (e.compareTo(node.e) < 0)
node.left = add(node.left, e);
else if (e.compareTo(node.e) > 0)
node.right = add(node.right, e);
return node;
}
// 看二分搜索树中是否包含元素e
public boolean contains(E e){
return contains(root, e);
}
// 看以node为根的二分搜索树中是否包含元素e,递归算法
private boolean contains(Node node, E e){
if(node == null)
return false;
if (e.compareTo(node.e) == 0)
return true;
else if (e.compareTo(node.e) < 0 )
return contains(node.left, e);
else // e.compareTo(node.e) > 0
return contains(node.right, e);
}
}
二分搜索树的前序遍历

// 二分搜索树的前序遍历
public void preOrder(){
preOrder(root);
}
// 前序遍历以node为根的二分搜索树, 递归算法
private void preOrder(Node node){
if(node == null)
return;
System.out.println(node.e);
preOrder(node.left);
preOrder(node.right);
}
二分搜索树的中序遍历
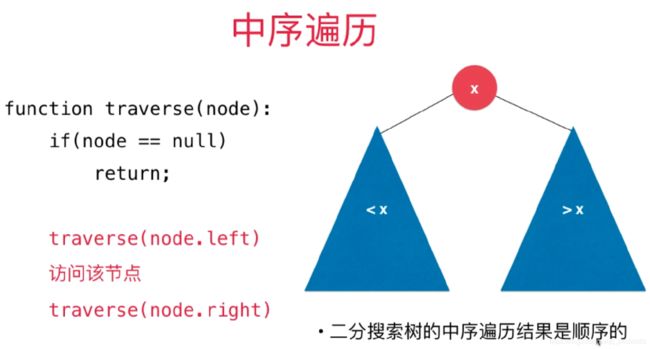
// 二分搜索树的中序遍历
public void inOrder(){
inOrder(root);
}
// 中序遍历以node为根的二分搜索树,递归算法
private void inOrder(Node node){
if (node == null)
return;
inOrder(node.left);
System.out.println(node.e);
inOrder(node.right);
}
- 中序遍历的结果就是排序好的结果
二分搜索树的后序遍历

// 二分搜索树的后序遍历
public void postOrder(){
postOrder(root);
}
// 后序遍历以node为根的二分搜索树,递归算法
private void postOrder(Node node){
if (node == null)
return;
postOrder(node.left);
postOrder(node.right);
System.out.println(node.e);
}
我们进行遍历的时候会访问每个节点三次,左节点经过一次,访问自己经过一次,访问右节点经过一次。
前序遍历对节点的操作发生在第一次,中序遍历发生在第二次,后序遍历发生在第三次。
这里的操作我们可以理解为输出,中序和后序遍历虽然最先输出的是最下角的,可是也是从root节点遍历过去的。
前序遍历的非递归算法
- 前序遍历的非递归算法(使用栈)
// 二分搜索树的非递归前序遍历
public void preOrderNR(){
Stack<Node> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()){
Node cur = stack.pop();
System.out.println(cur.e);
if (cur.right != null)
stack.push(cur.right);
if (cur.left != null)
stack.push(cur.left);
}
}
二分搜索树遍历的非递归实现,比递归实现复杂很多
中序遍历和后序遍历的非递归实现更复杂
中序遍历和后序遍历的非递归实现,实际应用不广
二分搜索树的层序遍历
前面介绍的先序中序后序遍历都是深度优先遍历
层序遍历也就是广度优先遍历就是先遍历第一层,然后第二层…
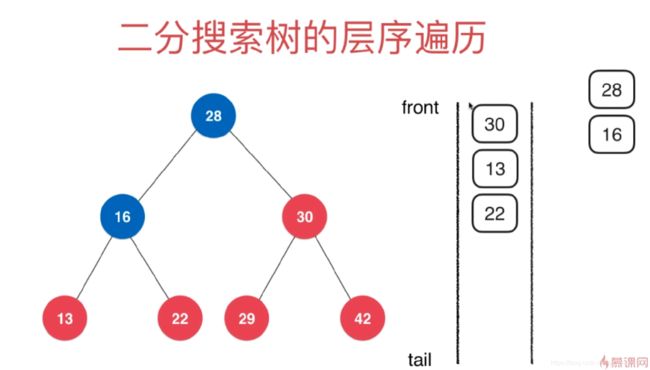
这里我们可以借助队列的概念来实现层序遍历
- 首先入队的是28
- 28出队后,它的两个孩子节点16,30入队
- 16出队,16的两个孩子13,22入队
- …
代码实现:
// 二分搜索树的层序遍历
public void levelOrder(){
Queue<Node> q = new LinkedList<>();
q.add(root);
while (!q.isEmpty()){
Node cur = q.remove();
System.out.println(cur.e);
if (cur.left != null)
q.add(cur.left);
if (cur.right != null)
q.add(cur.right);
}
}
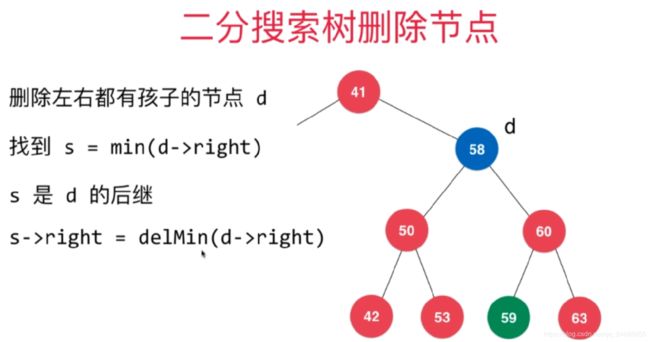
二分搜索树删除节点
- 删除只有左/右子树的节点,它的子树会补到它的位置上
- 那么当我们删除一个既有左节点又有右节点的要怎么删除呢

代码实现删除方法
// 删除掉以node为根的二分搜索树中值为e的节点, 递归算法
// 返回删除节点后新的二分搜索树的根
Node remove(Node node, E e){
if( node == null )
return null;
if( e.compareTo(node.e) < 0 ){
node.left = remove(node.left , e);
return node;
}
else if(e.compareTo(node.e) > 0 ){
node.right = remove(node.right, e);
return node;
}
else{ // e.compareTo(node.e) == 0
// 待删除节点左子树为空的情况
if(node.left == null){
Node rightNode = node.right;
node.right = null;
size --;
return rightNode;
}
// 待删除节点右子树为空的情况
if(node.right == null){
Node leftNode = node.left;
node.left = null;
size --;
return leftNode;
}
// 待删除节点左右子树均不为空的情况
// 找到比待删除节点大的最小节点, 即待删除节点右子树的最小节点
// 用这个节点顶替待删除节点的位置
Node successor = new Node(minimum(node.right).e);
size ++;
successor.right = removeMin(node.right);
successor.left = node.left;
node.left = node.right = null;
size --;
return successor;
}
}
// 返回以node为根的二分搜索树的最小值所在的节点
private Node minimum(Node node){
if(node.left == null)
return node;
return minimum(node.left);
}
// 删除掉以node为根的二分搜索树中的最小节点
// 返回删除节点后新的二分搜索树的根
private Node removeMin(Node node){
if(node.left == null){
Node rightNode = node.right;
node.right = null;
size --;
return rightNode;
}
node.left = removeMin(node.left);
return node;
}
整个二分搜索树的代码
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
public class BST<E extends Comparable<E>> {
private class Node{
public E e;
public Node left, right;
public Node(E e){
this.e = e;
left = null;
right = null;
}
}
private Node root;
private int size;
public BST(){
root = null;
size = 0;
}
public int size(){
return size;
}
public boolean isEmpty(){
return size == 0;
}
// 向二分搜索树中添加新的元素e
public void add(E e){
root = add(root, e);
}
// 向以node为根的二分搜索树中插入元素e,递归算法
// 返回插入新节点后二分搜索树的根
private Node add(Node node, E e){
if(node == null){
size ++;
return new Node(e);
}
if(e.compareTo(node.e) < 0)
node.left = add(node.left, e);
else if(e.compareTo(node.e) > 0)
node.right = add(node.right, e);
return node;
}
// 看二分搜索树中是否包含元素e
public boolean contains(E e){
return contains(root, e);
}
// 看以node为根的二分搜索树中是否包含元素e, 递归算法
private boolean contains(Node node, E e){
if(node == null)
return false;
if(e.compareTo(node.e) == 0)
return true;
else if(e.compareTo(node.e) < 0)
return contains(node.left, e);
else // e.compareTo(node.e) > 0
return contains(node.right, e);
}
// 二分搜索树的前序遍历
public void preOrder(){
preOrder(root);
}
// 前序遍历以node为根的二分搜索树, 递归算法
private void preOrder(Node node){
if(node == null)
return;
System.out.println(node.e);
preOrder(node.left);
preOrder(node.right);
}
// 二分搜索树的非递归前序遍历
public void preOrderNR(){
Stack<Node> stack = new Stack<>();
stack.push(root);
while(!stack.isEmpty()){
Node cur = stack.pop();
System.out.println(cur.e);
if(cur.right != null)
stack.push(cur.right);
if(cur.left != null)
stack.push(cur.left);
}
}
// 二分搜索树的中序遍历
public void inOrder(){
inOrder(root);
}
// 中序遍历以node为根的二分搜索树, 递归算法
private void inOrder(Node node){
if(node == null)
return;
inOrder(node.left);
System.out.println(node.e);
inOrder(node.right);
}
// 二分搜索树的后序遍历
public void postOrder(){
postOrder(root);
}
// 后序遍历以node为根的二分搜索树, 递归算法
private void postOrder(Node node){
if(node == null)
return;
postOrder(node.left);
postOrder(node.right);
System.out.println(node.e);
}
// 二分搜索树的层序遍历
public void levelOrder(){
Queue<Node> q = new LinkedList<>();
q.add(root);
while(!q.isEmpty()){
Node cur = q.remove();
System.out.println(cur.e);
if(cur.left != null)
q.add(cur.left);
if(cur.right != null)
q.add(cur.right);
}
}
// 寻找二分搜索树的最小元素
public E minimum(){
if(size == 0)
throw new IllegalArgumentException("BST is empty!");
return minimum(root).e;
}
// 返回以node为根的二分搜索树的最小值所在的节点
private Node minimum(Node node){
if(node.left == null)
return node;
return minimum(node.left);
}
// 寻找二分搜索树的最大元素
public E maximum(){
if(size == 0)
throw new IllegalArgumentException("BST is empty");
return maximum(root).e;
}
// 返回以node为根的二分搜索树的最大值所在的节点
private Node maximum(Node node){
if(node.right == null)
return node;
return maximum(node.right);
}
// 从二分搜索树中删除最小值所在节点, 返回最小值
public E removeMin(){
E ret = minimum();
root = removeMin(root);
return ret;
}
// 删除掉以node为根的二分搜索树中的最小节点
// 返回删除节点后新的二分搜索树的根
private Node removeMin(Node node){
if(node.left == null){
Node rightNode = node.right;
node.right = null;
size --;
return rightNode;
}
node.left = removeMin(node.left);
return node;
}
// 从二分搜索树中删除最大值所在节点
public E removeMax(){
E ret = maximum();
root = removeMax(root);
return ret;
}
// 删除掉以node为根的二分搜索树中的最大节点
// 返回删除节点后新的二分搜索树的根
private Node removeMax(Node node){
if(node.right == null){
Node leftNode = node.left;
node.left = null;
size --;
return leftNode;
}
node.right = removeMax(node.right);
return node;
}
// 从二分搜索树中删除元素为e的节点
public void remove(E e){
root = remove(root, e);
}
// 删除掉以node为根的二分搜索树中值为e的节点, 递归算法
// 返回删除节点后新的二分搜索树的根
Node remove(Node node, E e){
if( node == null )
return null;
if( e.compareTo(node.e) < 0 ){
node.left = remove(node.left , e);
return node;
}
else if(e.compareTo(node.e) > 0 ){
node.right = remove(node.right, e);
return node;
}
else{ // e.compareTo(node.e) == 0
// 待删除节点左子树为空的情况
if(node.left == null){
Node rightNode = node.right;
node.right = null;
size --;
return rightNode;
}
// 待删除节点右子树为空的情况
if(node.right == null){
Node leftNode = node.left;
node.left = null;
size --;
return leftNode;
}
// 待删除节点左右子树均不为空的情况
// 找到比待删除节点大的最小节点, 即待删除节点右子树的最小节点
// 用这个节点顶替待删除节点的位置
Node successor = new Node(minimum(node.right).e);
size ++;
successor.right = removeMin(node.right);
successor.left = node.left;
node.left = node.right = null;
size --;
return successor;
}
}
@Override
public String toString(){
StringBuilder res = new StringBuilder();
generateBSTString(root, 0, res);
return res.toString();
}
// 生成以node为根节点,深度为depth的描述二叉树的字符串
private void generateBSTString(Node node, int depth, StringBuilder res){
if(node == null){
res.append(generateDepthString(depth) + "null\n");
return;
}
res.append(generateDepthString(depth) + node.e +"\n");
generateBSTString(node.left, depth + 1, res);
generateBSTString(node.right, depth + 1, res);
}
private String generateDepthString(int depth){
StringBuilder res = new StringBuilder();
for(int i = 0 ; i < depth ; i ++)
res.append("--");
return res.toString();
}
}
两个数组的交集问题
LeetCode第349号问题
-
题目描述
给定两个数组,编写一个函数来计算它们的交集。 -
示例 1:
输入: nums1 = [1,2,2,1], nums2 = [2,2]
输出: [2] -
示例 2:
输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出: [9,4] -
说明:
输出结果中的每个元素一定是唯一的。
我们可以不考虑输出结果的顺序。
解答代码:
import java.util.ArrayList;
import java.util.TreeSet;
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
TreeSet<Integer> set = new TreeSet<>();
for (int num: nums1)
set.add(num);
ArrayList<Integer> list = new ArrayList<>();
for (int num: nums2){
if (set.contains(num)){
list.add(num);
set.remove(num);
}
}
int[] res = new int[list.size()];
for (int i = 0 ; i < list.size() ; i ++)
res[i] = list.get(i);
return res;
}
}
- 注意使用了set已经自动帮我们给nums1去重了,而在遍历nums2的过程中,当有相同元素的时候,在添加到list中后也会将set中的这个元素remove掉,也就避免了重复数据。
两个数组的交集 II
leetcode第350号问题
-
问题描述
给定两个数组,编写一个函数来计算它们的交集。 -
示例 1:
输入: nums1 = [1,2,2,1], nums2 = [2,2]
输出: [2,2] -
示例 2:
输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出: [4,9] -
说明:
输出结果中每个元素出现的次数,应与元素在两个数组中出现的次数一致。
我们可以不考虑输出结果的顺序。 -
进阶:
如果给定的数组已经排好序呢?你将如何优化你的算法?
如果 nums1 的大小比 nums2 小很多,哪种方法更优?
如果 nums2 的元素存储在磁盘上,磁盘内存是有限的,并且你不能一次加载所有的元素到内存中,你该怎么办?
解答代码:
import java.util.ArrayList;
import java.util.TreeMap;
class Solution {
public int[] intersect(int[] nums1, int[] nums2) {
// TreeMap的两个Integer参数,第一个代表我们存入的元素,第二个代表出现的频次
TreeMap<Integer, Integer> map = new TreeMap<>();
for (int num: nums1){
if (!map.containsKey(num))
map.put(num, 1);
else
map.put(num, map.get(num) + 1);
}
ArrayList<Integer> list = new ArrayList<>();
for (int num: nums2){
if (map.containsKey(num)){
list.add(num);
map.put(num, map.get(num) - 1);
if (map.get(num) == 0)
map.remove(num);
}
}
int[] res = new int[list.size()];
for (int i = 0 ; i < list.size() ; i ++)
res[i] = list.get(i);
return res;
}
}