建议收藏,爬虫必用技巧, Python模拟登入的N种方式!
这段时间在研究如何破解官网验证码,然后进行下一步的爬虫操作,然而一个多星期过去了,编写的代码去识别验证码的效率还是很低,尝试用了tesserorc库和百度的API接口,都无济于事,本以为追不上五月的小尾巴,突然想到我尝试了这么多方法何不为一篇破坑博客呢。
现在很多官网都会给出相应的反扒措施,就拿这个登入来说,如果你不登入账号那么你就只能获取微量的信息,甚至获取不了信息,这对我们爬虫来说是非常不友好的,但是我们总不可能每次都需要手动登入吧,一次二次你能接受,大工程呢?既然学了python,而不为用脚本代码帮你做这点事情呢?
模拟登入:
- 不同方式优缺点对比:
- 方式一: requests的auth参数:
- 方式一: requests高级用法扩展:
- 方式二: requests的session会话使用:
- 方式三: selenium模拟登入:
图为简书登入模块:
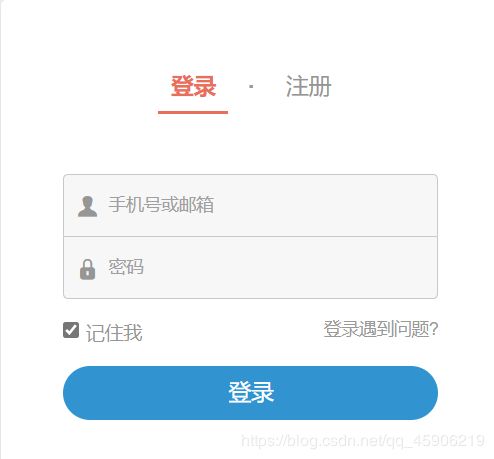
不同方式优缺点对比:
突然想到一种可能更简单的方式,所以整理得三,不同情况参考不同用法!
如下:
| 方式 | 优点 | 缺点 |
|---|---|---|
| requests的auth参数 | 极简 | 出现的次数很少 |
| requests的session会话 | 维持cookies一致 | 需要构造一定参数 |
| selenium自动化 | 最强的模拟登入 | 安装复杂,库名太多 |
以上就是三大登入的优缺点,个人推荐使用session去尝试模拟登入!
方式一: requests的auth参数:
- 这个是我无意在书上看到的。关于requests的高级用法中,提到了这点,这里就记录一下,个人觉得这种方式只可能出现在
某网站中,学了也挺好的,省的限制观看次数,后续我也会更新如何破解vip视频的思路,有需要的关注我。
使用类似场所:

用法很简单,代码如下:
# parasm: url : 网站
# parasm: username: 用户名
# parasm: password : 密码
import requests
url = '********'
r = requests.get(url, anth=('username', 'password'))
print(r.text)
还是一句话,这种方式极大可能出现在某网站中,其他情况基本不可能出现,那么就得使用下面二种方式了。
方式一: requests高级用法扩展:
-
相信很多人看书都不看全的,很多细节都在书中呢,下面扩展几种requests库的高级用法,很好用的东西。
-
超时处理:
某网站服务器搭建在国外,加载巨慢。代码可能抛出timeout : xxxx等情况,这个时候用它:
r = requests.get(url , timeout=30)
- 文件上传: 假如某网站需要上传文件,那么就使用它:
files = {'file': open('img.jpg', 'rb')}
r = requests.get(url, files=files)
print(r.text)
- cookies设置: headers这个很多人都使用过吧,基本都是加一个代理头就完事了,其实也可以设置其他的参数,然后使用post请求,就可以简单的模拟登入一次了,用法如下:
这些字段一般都需要加上,常用的就是代理头user-agent,这个必须设置:
headers = {
'cookies': '浏览器复制',
'Host': '浏览器复制',
'Referer' '浏览器复制'
'User-Agent': '浏览器复制'
}
方式二: requests的session会话使用:
会话是什么: 就好比你和朋友对接电话,你这头是客户端,朋友那头是服务端,你们接通电话,这个通话记录就代表一个会话,电话中,你可以通过声音知道是你朋友,在服务器中,你请求成功一次,客户端和服务端就维持了一个会话,这个会话能代表你的身份,那么这段时间在一个浏览器中,你进入网站就不需要在输入账号密码了,直到你退出浏览器,那么会话截至,下次登入就需要再次输入密码了。
- 很好的是,
Session能很好的帮助我们维持会话,从而达到cookies的一致性。区别于一半的请求requests,就可以达到get 和 post 共同的作用;
基本用法如下:
s = requests.Session()
r = s.get(url)
那么我们使用会话从GitHub的模拟登入尝试下:
首先我们需要登入一次,看看需要构建什么参数:
登入网站
在这个界面就开启f12 , 不然看不了会话维持:
登入成功之后,如下图,查看构造参数:
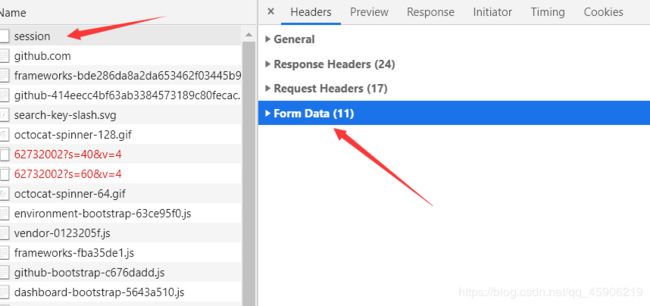
打开这个From Data 会发现,authenticity_token 这个字段,我们可能构造不了,这个时候,就得回到 登入界面了, 打开源代码。F这个字段:

如图: 只需要爬取这个页面,获得这个参数 那么就可以构造登入的所有参数了, 爬虫代码如下:
def token(self):
# 获得 authenticity_token 字段 方便下次模拟登入
# login_url : 登入网址
r = self.session.get(self.login_url, headers=self.headers)
if r.status_code == 200:
r.encoding = r.apparent_encoding
html = etree.HTML(r.text)
html = etree.tostring(html)
html = etree.fromstring(html)
tk = html.xpath('//*[@id="login"]/form/input[1]/@value')
return tk
对于cookies的一致性,使用session 就已经搞定了这个问题,根据上图的Name字段中的session ,
我们可以找到会话网址: ‘https://github.com/session’
所以我们现在只需要构造一个函数去请求这个会话网址,就可以达到我们的要求了:
代码如下, 这里我构造了一个class类,账号密码用自己,或者前面传值过去,图中的函数是二个爬虫代码,可以根据需求设计:
def login(self):
# 模拟登入
post_date = {
'commit': 'Sign in',
'authenticity_token': self.token(),
'ga_id': '1453216517.1584352055',
'login': self.email,
'password': self.password
}
# 打印仓库信息
r = self.session.post(self.post_url, data=post_date, headers=self.headers)
if r.status_code == 200:
self.get_info_1(r.text)
# 打印个人信息和邮箱
r = self.session.get(self.logined_url, headers=self.headers)
if r.status_code == 200:
self.get_info_2(r.text)
会话登入到这里就结束了,主要是构造参数挺麻烦的,需要页面里寻找,看到这里给个关注和赞啦。

方式三: selenium模拟登入:
如何下载selenium相关的插件,我就不做介绍了,篇幅有限
使用selenium 就是需要考虑到表单的切换,和定位元素等,其他都很简单,这里用4399游戏网页做一个实例: 网址
点击登入:
弹出登入表单:
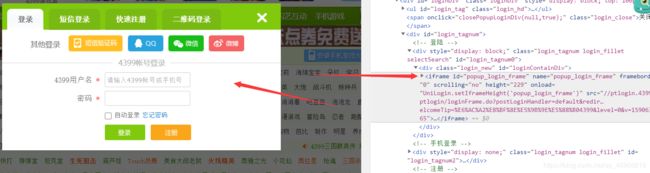
这里我们需要切换表单,不然输入不了,怎么找到这个表单的,很简单,整块的高亮就行:
代码如下:
from selenium import webdriver # 导入库
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome() # 声明浏览器
browser.implicitly_wait(30) # 隐性等待 在规定的时间内,最长等待S秒
browser.get('http://www.4399.com') # 打开设置的网址
# ID定位 或者其他的都行
browser.find_element_by_id('login_tologin').click() # 点击登入界面
browser.switch_to.frame("popup_login_frame") # 进入表单中
browser.find_element_by_css_selector('#username').clear()
browser.find_element_by_id('username').send_keys('账号')
browser.find_element_by_id('username').send_keys(Keys.TAB)
browser.find_element_by_id('j-password').send_keys('密码')
browser.find_element_by_id('j-password').send_keys(Keys.ENTER)
我给的例子没有涉及到验证码,如果涉及到验证码,要不人工输入,要么破解验证码,或者交给打码平台,最好的方式就是绕过验证码,这个我也在思考如何去实现。以上就是这周的知识总结,有帮助的话,就点个赞和关注吧!
后记: 开学了,天气很热,但我们也不要放弃!