java面试题整理
2018年11月份辞职后,就开始我的漫漫求职之路,终于在2019年2月份入职了.在这期间,我面试了应该差不多30加公司了.总结了每次被问到的问题.希望对大家有帮助.我是在广州工作的.这份总结我是写在word里面,拷贝过来,每一点的序号都变成了1,大家将就一下.
- hashmap底层
数据结构中有数组和链表这两个结构来存储数据。
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小;
数组的特点是:寻址容易,插入和删除困难;
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大。
链表的特点是:寻址困难,插入和删除容易。
综合这两者的优点,摒弃缺点,哈希表就诞生了,既满足了数据查找方面的特点,占用的空间也不大。
哈希表可以说就是数组链表,底层还是数组但是这个数组每一项就是一个链表。
HashMap 是一个用于存储Key-Value 键值对的集合,每一个键值对也叫做Entry。这些个Entry 分散存储在一个数组当中,这个数组就是HashMap 的主干。
HashMap 数组每一个元素的初始值都是Null。
HashMap的构造函数
HashMap实现了Map接口,继承AbstractMap。其中Map接口定义了键映射到值的规则,而AbstractMap类提供 Map 接口的骨干实现。
HashMap提供了三个构造函数:
HashMap():构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity):构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity, float loadFactor):构造一个带指定初始容量和加载因子的空HashMap。
HashMap也可以说是一个数组链表,HashMap里面有一个非常重要的内部静态类——Entry,这个Entry非常重要,它里面包含了键key,值value,下一个节点next,以及hash值,Entry是HashMap非常重要的一个基础Bean,因为所有的内容都存在Entry里面,HashMap的本质可以理解为 Entry[ ] 数组。
HashMap的遍历
//第三种:推荐,尤其是容量大时
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
使用HashMap的匿名内部类Entry遍历比使用keySet()效率要高很多,使用forEach循环时要注意不要在循环的过程中改变键值对的任何一方的值,否则出现哈希表的值没有随着键值的改变而改变,到时候在删除的时候会出现问题。 此外,entrySet比keySet快些。对于keySet其实是遍历了2次,一次是转为iterator,一次就从hashmap中取出key所对于的value。而entrySet只是遍历了第一次,他把key和value都放到了entry中,所以就快了。
Put 方法的原理
比如调用 hashMap.put(“apple”, 0) ,插入一个Key为“apple”的元素。这时候我们需要利用一个哈希函数来确定Entry的插入位置(index): index = Hash("apple")
但是,因为HashMap的长度是有限的,当插入的Entry越来越多时,再完美的Hash函数也难免会出现index冲突的情况。
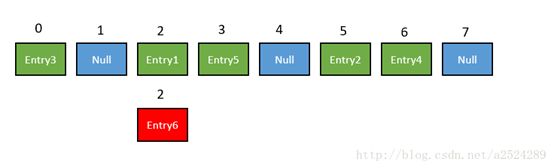
我们可以利用链表来解决。
HashMap数组的每一个元素不止是一个Entry对象,也是一个链表的头节点。每一个Entry对象通过Next指针指向它的下一个Entry节点。当新来的Entry映射到冲突的数组位置时,只需要插入到对应的链表即可:
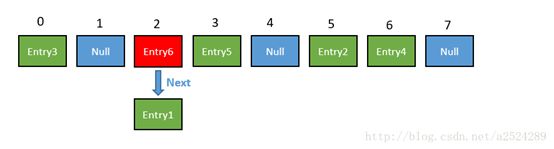
新来的Entry节点插入链表时,使用的是“头插法。
Get方法的原理
首先会把输入的Key做一次Hash映射,得到对应的index:
index = Hash(“apple”)
由于刚才所说的Hash冲突,同一个位置有可能匹配到多个Entry,这时候就需要顺着对应链表的头节点,一个一个向下来查找。假设我们要查找的Key是“apple”:
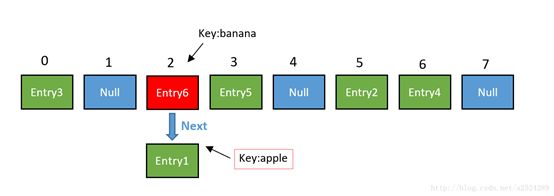
第一步,我们查看的是头节点Entry6,Entry6的Key是banana,显然不是我们要找的结果。
第二步,我们查看的是Next节点Entry1,Entry1的Key是apple,正是我们要找的结果。
之所以把Entry6放在头节点,是因为HashMap的发明者认为,后插入的Entry被查找的可能性更大。
HashMap的初始长度
初始长度为16,且每次自动扩容或者手动初始化的时候必须是2的幂。
如何进行位运算呢?有如下的公式(Length是HashMap的长度):
之前说过,从Key映射到HashMap数组的对应位置,会用到一个Hash函数:
index = Hash(“apple”)
如何实现一个尽量均匀分布的Hash函数呢?我们通过利用Key的HashCode值来做某种运算。
index = HashCode(Key) & (Length - 1)
下面我们以值为“book”的Key来演示整个过程:
- 计算book的hashcode,结果为十进制的3029737,二进制的101110001110101110 1001。
- 假定HashMap长度是默认的16,计算Length-1的结果为十进制的15,二进制的1111。
- 把以上两个结果做与运算,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9。
可以说,Hash算法最终得到的index结果,完全取决于Key的Hashcode值的最后几位。这里的位运算其实是一种快速取模算法
hashmap的特点
1.底层实现是 链表数组,JDK 8 后又加了 红黑树;
2.实现了 Map 全部的方法
3.key 用 Set 存放,所以想做到 key 不允许重复,key 对应的类需要重写 hashCode 和 equals 方法
4. 允许空键和空值(但空键只有一个,且放在第一位
5. 元素是无序的,而且顺序会不定时改变
- MySql
Mysql的优点:简单,开源免费,小巧,速度快,可移植性高,连接性和安全性好
Mysql的缺点:不支持热备份,没有一种存储过程语言
(1)、索引是什么
索引是对数据库中一或多个列值的排序,帮助数据库高效获取数据的数据结构
假如我们用类比的方法,数据库中的索引就相当于书籍中的目录一样,当我们想找到书中的摸个知识点,我们可以直接去目录中找而不是在书中每页的找,但是这也抛出了索引的一个缺点,在对数据库修改的时候要修改索引到导致时间变多。
几个基本的索引类型: 普通索引、 唯一索引、主键索引 、全文索引
索引优点
· 加快检索速度
· 唯一索引确保每行数据的唯一性
· 在使用索引的过程可以优化隐藏器,提高系统性能
索引缺点
· 插入删除 修改 维护速度下降
· 占用物理和数据空间
(2)、事务
事务的作用
事务(Transaction)是并发控制的基本单位。事务就是一系列的操作,这些操作要么都执行,要么都不执行。
事务具有以下4个基本特征
· Atomic(原子性) 事务中的一系列的操作要么都完成,要么全部失败
· Consistency(一致性) 一个成功的事务应该讲数据写入的到数据库,否则就要回滚到最初的状态
· Isolation(隔离性) 并发访问和修改的独立
· Durability(持久性) 事务结束应该讲事务的处理结构存储起来
事务的语句
· 开始事物:BEGIN TRANSACTION
· 提交事物:COMMIT TRANSACTION
· 回滚事务:ROLLBACK TRANSACTION
(3)、数据库中的乐观锁和悲观锁
· 悲观锁 假定会发生并发冲突,屏蔽任何违反数据完整的操作
· 乐观锁 假定不会发生冲突,只有在提交操作时检查是否违反数据的完整性
(4)、drop、delete、 truncate的区别
delete和truncate只删除表的数据不删除表的结构
· 速度 drop > truncate > delete
· 想删除部分数据时, delete 删除时要带上where语句
· 保留表而想删除所有的数据时用truncate
(5)、视图的作用,视图可以更改么?
视图是虚拟的表,与包含数据的表不一样,视图只包含使用时动态检索数据的查询;不包含任何列或数据。使用视图可以简化复杂的sql操作,隐藏具体的细节,保护数据;视图创建后,可以使用与表相同的方式利用它们。
视图不能被索引,也不能有关联的触发器或默认值,如果视图本身内有order by 则对视图再次order by将被覆盖。
对于某些视图比如未使用联结子查询分组聚集函数Distinct Union等,是可以对其更新的,对视图的更新将对基表进行更新;但是视图主要用于简化检索,保护数据,并不用于更新,而且大部分视图都不可以更新。
(6)、应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
(7)、下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
若要提高效率,可以考虑全文检索。
(8)、in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
(9)、不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
(10)、很多时候用 exists 代替 in 是一个好的选择
(11)、索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
(12)、尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
(13)、在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
- json
JSON(JavaScript Object Notation)一种轻量级的数据交互格式
类似于一种数据封装,可以想象为java中student封装类
它是基于JavaScript的一个子集。数据格式简单, 易于读写, 占用带宽小
JSON的数值可以是数字、字符串、布尔值、数组或者对象、null
什么是JSON和XML
JSON:JavaScript Object Notation 【JavaScript 对象表示法】.
XML:extensiable markup language 被称作可扩展标记语言
JSON和XML都是数据交换语言,完全独立于任何程序语言的文本格式。
XML文件格式复杂,比较占宽带,服务器端与客户端解析xml话费较多的资源和时间.
JSON解析方式(阿里巴巴fastjson、谷歌gson,jackJson)
XML解析方式(dom、sax、pul)
XML和JSON优缺点
XML的优点
- A.格式统一,符合标准;
- B.容易与其他系统进行远程交互,数据共享比较方便
XML的缺点
- A.XML文件庞大,文件格式复杂,传输占带宽;
- B.服务器端和客户端都需要花费大量代码来解析XML,导致服务器端和客户端代码变得异常复杂且不易维护;
- C.客户端不同浏览器之间解析XML的方式不一致,需要重复编写很多代码;
- D.服务器端和客户端解析XML花费较多的资源和时间。
JSON的优点
- A.数据格式比较简单,易于读写,格式都是压缩的,占用带宽小;
- B.易于解析,客户端JavaScript可以简单的通过eval_r()进行JSON数据的读取;
- C.支持多种语言,包括ActionScript, C, C#, ColdFusion, Java, JavaScript, Perl, PHP, Python, Ruby等服务器端语言,便于服务器端的解析;
- D.因为JSON格式能直接为服务器端代码使用,大大简化了服务器端和客户端的代码开发量,且完成任务不变,并且易于维护
JSON的缺点
- A.没有XML格式这么推广的深入人心和喜用广泛,没有XML那么通用性;
- B.JSON片段的创建和验证过程比一般的XML稍显复杂。
- mvc的理解
MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。
Model(模型):数据模型,提供要展示的数据,因此包含数据和行为,主要提供了模型数据查询和模型数据的状态更新等功能,包括数据和业务。主要使用的技术:数据模型:实体类(JavaBean),数据访问:JDBC,Hibernate等。
View(视图):负责进行模型的展示,一般就是我们见到的用户界面,比如JSP,Html等
Controller(控制器):接收用户请求,委托给模型进行处理(状态改变),处理完毕后把返回的模型数据返回给视图,由视图负责展示。主要使用的技术:servlet,Struts中的Action类等。
MVC是一个框架模式,它强制性的使应用程序的输入、处理和输出分开。使用MVC应用程序被分成三个核心部件:模型、视图、控制器。它们各自处理自己的任务。最典型的MVC就是JSP + servlet + javabean的模式。
JSP是一种动态网页技术。它把HTML页面中加入Java脚本,以及JSP标签构成JSP文件。当浏览器请求某个JSP页面时,Tomcat会把JSP页面翻译为Java文件。
- springmvc的理解
SpringMvc是基于过滤器对servlet进行了封装的一个框架,我们使用的时候就是在web.xml文件中配置DispatcherServlet类;SpringMvc工作时主要是通过DispatcherServlet管理接收到的请求并进行处理。
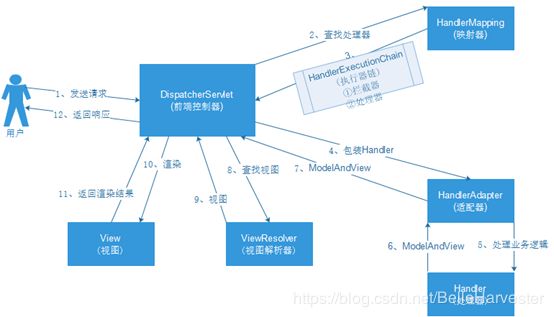
具体执行流程如下:
SpringMVC运行原理
- 客户端请求提交到DispatcherServlet
- 由DispatcherServlet控制器查询HandlerMapping,找到并分发到指定的Controller中。
- Controller调用业务逻辑处理后,返回ModelAndView
- DispatcherServlet查询一个或多个ViewResoler视图解析器,找到ModelAndView指定的视图
- 视图负责将结果显示到客户端
SpringMVC的优点:
清晰的角色划分
强大的JavaBean配置
可适配,非侵入
可复用的业务代码
可定制的绑定和验证
灵活的model转换:在Springweb框架中,使用基于Map的键/值对来达到轻易的与各种视图技术集成。
简单而强大的JSP标签库
JSP表单标签库:在Spring2.0中引入的表单标签库,使用在JSP编写表单更加容易。
常用的jsp标签
- spring的核心模块
(1)、Spring Core【核心容器】:核心容器提供了Spring的基本功能。核心容器的核心功能是用IOC容器来管理类的依赖关系。
(2)、Spring AOP【面向切面】:Spring的AOP模块提供了面向切面编程的支持。SpringAOP采用的是纯Java实现,采用基于代理的AOP实现方案,AOP代理由IOC容器负责生成、管理,依赖关系也一并由IOC容器管理。
(3)、Spring ORM【对象实体映射】:提供了与多个第三方持久层框架的良好整合。
(4)、Spring DAO【持久层模块】: Spring进一步简化DAO开发步骤,能以一致的方式使用数据库访问技术,用统一的方式调用事务管理,避免具体的实现侵入业务逻辑层的代码中。
(5)、Spring Context【应用上下文】:它是一个配置文件,为Spring提供上下文信息,提供了框架式的对象访问方法。
(6)、Spring Web【Web模块】:提供了基础的针对Web开发的集成特性。
(7)、Spring MVC【MVC模块】:提供了Web应用的MVC实现。Spring的MVC框架并不是仅仅提供一种传统的实现,它提供了一种清晰的分离模型。
- spring控制反转,依赖注入的理解
所有的一切都是为了松耦合
如果一个类A 的功能实现需要借助于类B,那么就称类B是类A的依赖,如果在类A的内部去实例化类B,那么两者之间会出现较高的耦合,一旦类B出现了问题,类A也需要进行改造,如果这样的情况较多,每个类之间都有很多依赖,那么就会出现牵一发而动全身的情况,程序会极难维护,并且很容易出现问题。要解决这个问题,就要把A类对B类的控制权抽离出来,交给一个第三方去做,把控制权反转给第三方,就称作控制反转(IOC Inversion Of Control)。控制反转是一种思想,是能够解决问题的一种可能的结果,而依赖注入(Dependency Injection)就是其最典型的实现方法。由第三方(我们称作IOC容器)来控制依赖,把他通过构造函数、属性或者工厂模式等方法,注入到类A内,这样就极大程度的对类A和类B进行了解耦。
依赖注入spring的注入方式:
-
-
- set注入方式
- 静态工厂注入方式
- 构造方法注入方式
- 基于注解的方式
-
- redis的用途
redis常用的五种数据类型
(1)、String(字符串)
String是简单的 key-value 键值对,value 不仅可以是 String,也可以是数字。它是Redis最基本的数据类型,一个redis中字符串value最多可以是512M。
(2)、Hash(哈希)
Redis hash 是一个键值对集合,对应Value内部实际就是一个HashMap,Hash特别适合用于存储对象。
(3)、List(列表)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)。
(4)、Set(集合)
Redis的Set是String类型的无序集合,它的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
(5)、zset(有序集合)
Redis zset 和 set 一样也是String类型元素的集合,且不允许重复的成员,不同的是每个元素都会关联一个double类型的分数,用来排序。
为什么使用redis?
(1)、解决应用服务器的cpu和内存压力
(2)、减少io的读操作,减轻io的压力
(3)、关系型数据库的扩展性不强,难以改变表结构
优点:
(1)、nosql数据库没有关联关系,数据结构简单,拓展表比较容易
(2)、nosql读取速度快,对较大数据处理快
适用场景:
(1)、数据高并发的读写
(2)、海量数据的读写
(3)、对扩展性要求高的数据
不适用场景:
(1)、需要事务支持
(2)、基于sql结构化查询储存,关系复杂
使用场景:
配合关系型数据库做高速缓存
换成高频次访问的数据,降低数据库io
分布式架构,做session共享
可以持久化特定数据
利用zset类型可以存储排行榜
利用list的自然时间排序存储最新n个数据
- servlet的理解
Servlet是一个作为浏览器与数据库之间的中间层,它是为了解决实现动态页面而衍生的一个java组件。也就是说Servlet就是一个程序,是什么程序呢,是运行在web服务器端的程序。
作用:
浏览器发送请求给Tomcat,Tomcat作为Servlet容器,会找到对应的Servlet并将http请求文本接收并解析,然后封装成HttpServletRequest类型的request对象。Servlet接受处理通过设置response对象,然后将response对象交给Tomcat,Tomcat就会将其变成响应文本的格式发送给浏览器。
Servlet生命周期
首先Tomcat接收到http请求后,会检查是否装载并创建了对应的Servlet,如果是,则创建一个用于封装HTTP请求消息的HttpServletRequest对象和一个代表HTTP响应消息的HttpServletResponse对象,
然后调用Servlet的service()方法,(一般我们继承了HttpServlet类后会覆写doGet()和doPoat()方法)并将请求和响应对象作为参数传递进去。如果否,装载并创建该Servlet的一个实例对象,调用Servlet实例对象的init()方法,然后执行上面同样的步骤。
Tomcat被停止或重新启动之前,Servlet引擎将卸载Servlet,并在卸载之前调用Servlet的destroy()方法。
- mybatis的优缺点\hibernate的优缺点
MyBatis 是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以对配置和原生Map使用简单的 XML 或注解,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
MyBatis框架的优点:
(1). 与JDBC相比,减少了50%以上的代码量。
(2). MyBatis是最简单的持久化框架,小巧并且简单易学。
(3). MyBatis相当灵活,不会对应用程序或者数据库的现有设计强加任何影响,SQL写在XML里,从程序代码中彻底分离,降低耦合度,便于统一管理和优化,并可重用。
(4). 提供XML标签,支持编写动态SQL语句。
(5). 提供映射标签,支持对象与数据库的ORM字段关系映射。
MyBatis框架的缺点:
(1). SQL语句的编写工作量较大,尤其是字段多、关联表多时,更是如此,对开发人员编写SQL语句的功底有一定要求。
(2). SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
MyBatis框架适用场合:
MyBatis专注于SQL本身,是一个足够灵活的DAO层解决方案。
对性能的要求很高,或者需求变化较多的项目,如互联网项目,MyBatis将是不错的选择。
hibernate:
(1). 功能强大,数据库无关性好,O/R映射能力强,如果你对Hibernate相当精通,而且对Hibernate进行了适当的封装,那么你的项目整个持久层代码会相当简单,需要写的代码很少,开发速度很快。
(2). 有更好的二级缓存机制,可以使用第三方缓存。
(3). 缺点就是学习门槛不低,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之间如何权衡取得平衡,以及怎样用好Hibernate方面需要你的经验和能力都很强才行。
- 跨域的理解
当用户对不同协议或不同端口或不同域名的资源进行访问时,就是跨域。
为什么会造成跨域
罪魁祸首:同源策略
同源定义:即同一域,即相同协议&相同端口&相同域名&相同子域名
同源策略规定:XHR对象只能访问与包含它的页面位于同一域中的资源,有利于预防一些恶意行为。
解决办法有很多,CORS、iframe、h5新特性postMessage等,而比较简单的方法就是jsonp。
JSONP,JSON with Padding的简写,这个全称对jsonp的理解还是有一定的帮助的。填充式JSON或者说是参数式JSON。JSONP的语法和JSON很像,简单来说就是在JSON外部用一个函数包裹着。JSONP基本语法如下:
callback({ "name": "kwan" , "msg": "获取成功" });
JSONP两部分组成:回调函数和里面的数据。回调函数是当响应到来时,应该在页面中调用的函数,一般是在发送过去的请求中指定。
JSONP原理:
刚才的解决依据可知,JSONP原理就是动态插入带有跨域url的