python爬取网易云某一歌手的音乐评论
爬取网易云音乐上某一歌手的音乐评论,许嵩为例。
一:查看网页抓包分析,首先抓取许嵩的歌曲,点击单曲抓包,我只抓取了第一页的歌曲


搜索许嵩查看获取 歌曲id。可以看出来是 post 请求获取的,参数是加密过得,我没有研究过这个解密,直接把参数扒下来,调用对应地址,解析返回的 json 获取歌曲id及其他信息。
# 获取歌曲id及歌曲名称
def get_song_id():
data = {
# 许嵩的
"params": "KcgvTSDue1viaYxe07Zd+TqT3aaJZ2CfQ0FIOySNGI2ouQnVRHTA2XN8v8+ydxOadocWof/DGCMpXNSAKEHMf0Y/HJlyG2soJ7WaefhCkr8mm0nSpX9nQjIVK9iIkpQ14Q2UXQht5JUmgKLlYuJJ2TdVmhaBtbl+K12v0JXqzl+l0DRQWovH2MvkrdhAhCWty3cRuSbu/dlbGU140HLTO5/pT7ZeTxcPe8/jB/txC/B1QnafGnAiFerXYHdn4N61benQ8TeSQNcFOgfUypNgoaiyh8nJy5OzvE5XYwtkh/7JMRbMIEB6vpp4FYnfNEBi",
"encSecKey": "95a9dc4f10032b4db1a5e40bc78e8c5009130370cfa2412a3203aac932ebca7de3958d3a682be22aa521ab4408ed5d9e2d502dff9b5e2631386ff1ef161dff5e43e1fef1e356eea17dfaf4c444de0119504b383e0113a7b2b65b11d260b1f6b5a20df4394e04eac3ff75c9092f05f82b2e0ab8abb7c9156e0ccb5c9c5e1869b9"
}
# songs_url = "https://music.163.com/weapi/cloudsearch/get/web?csrf_token="
# headers = {
# 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.101'
# ' Safari/537.36'
# }
resp = requests.post(url=songs_url, data=data, headers=headers)
# content = resp.content.decode()
resp_json= resp.json()
arr = resp_json['result']['songs']
songs_id = []
for song in arr:
# print(song['id'], song['name'])
id2name = {song['id']: song['name']}
songs_id.append(id2name)
return songs_id二:爬取对应歌曲评论
点进歌曲后抓包发现 有歌曲评论的请求是 https://music.163.com/weapi/v1/resource/comments/R_SO_4_411214279?csrf_token=
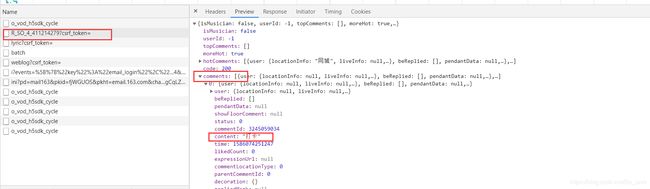
其中content就是评论的内容。剩下的就是解析这个请求,封装参数了。

多试几次就会发现这个url的 R_SO_4_ 后面的就是这个歌曲的id,而 请求参数肯定是对分页参数进行加密的,具体的解密过程我没研究过,也是在网上看了其他大佬的分析,把他们的加密代码改了下。
地址:https://www.jianshu.com/p/98e33aae1d6b
我的代码
import requests
from Crypto.Cipher import AES
import base64
import json
import pymysql
import time
# 获取音乐
songs_url = "https://music.163.com/weapi/cloudsearch/get/web?csrf_token=" # post
comment_url_base = "https://music.163.com/weapi/v1/resource/comments/R_SO_4_" # post
# 输出文件名称
out_put_file = 'wangyiyun.txt'
hot_comment_out_put_file = 'wangyiyun_hot.txt'
out_put_error_file = 'error.txt'
# mysql 链接
db = pymysql.connect(host="", user="root", passwd="", db="db01", port=3309, charset='utf8mb4')
page_size = 100
class Comment:
def __init__(self,comment_dict,songId, songName):
# {"content":comment['content'],"likedCount":comment['likedCount'],"songId":song_id,"nickname":comment['user']['nickname']}
self.__id__ = comment_dict['commentId']
self.__content__ = comment_dict['content']
self.__time__ = comment_dict['time']
self.__likedCount__ = comment_dict['likedCount']
self.__parentCommentId__ = comment_dict['parentCommentId']
self.__nickname__ = comment_dict['user']['nickname']
self.__userId__ = comment_dict['user']['userId']
self.__songId__ = songId
self.__songName__ = songName
def __str__(self):
return "id " + str(self.__id__) + " songName: " + self.__songName__ + " nickname: " + self.__nickname__ + " content: " + self.__content__ + \
" likedCount: " + str(self.__likedCount__) + " time: " + str(self.__time__)
# 获取 每首歌的 评论
def get_comments(song_id, song_name):
param = get_params(0)
encSecKey = get_encSecKey()
data = {
"params": param,
"encSecKey":encSecKey
}
# 每个歌曲的获取评论的 url
comment_url = comment_url_base + str(song_id) + "?csrf_token="
try:
resp = requests.post(url=comment_url, data=data, headers=headers, timeout=10)
except Exception as result:
print(time.strftime('%Y.%m.%d %H:%M:%S ', time.localtime(time.time())) ," 获取 %s 评论数量错误 " % song_name, result)
write_error_to_file(" 获取 %s 评论数量错误 result %s" % (song_name, result))
else:
comment_json = resp.json()
total = comment_json['total']
# 热评 每首歌 15条 热评
hot_comment_list_json = comment_json['hotComments']
hot_comment_list = []
for hot_comment in hot_comment_list_json:
# com = {"content":comment['content'],"likedCount":comment['likedCount'],"songId":song_id,"nickname":comment['user']['nickname']}
# 拼装对象
com_obj = Comment(hot_comment, song_id, song_name)
# 写入 本地文件
hot_comment_write_to_file(com_obj.__str__())
hot_comment_list.append(com_obj)
if len(hot_comment_list) > 0:
# 插入 mysql
hot_batch_insert_mysql(hot_comment_list)
print(time.strftime('%Y.%m.%d %H:%M:%S ', time.localtime(time.time())) ," 抓取 %s 的评论,一共 %d 条" % (song_name, total))
flag = 0
# 获取评论
# 从最后一页开始获取
# for page in reversedrsed(rangege(int(total/page_size+1))):
# 从第一页开始获取
for page in range(int(total/page_size+1)):
# 50 页 睡眠, 避免封 ip
print("爬取 %s 第 %d 页" % (song_name, page+1))
if page % 10 == 0 and page > 50:
print("睡眠中 %s %d " % (song_name, page+1))
time.sleep(5)
if page % 100 == 0 and page > 1000:
print("睡眠中 %s %d " % (song_name, page+1))
time.sleep(20)
page_comment_list = get_page_comment_list(song_id, song_name, page, page_size)
if page_comment_list is None or len(page_comment_list) == 0:
write_error_to_file(" 抓取 %s 的评论,第 %d 页 数据为空" % (song_name, page))
print(" 抓取 %s 的评论,第 %d 页 数据为空" % (song_name, page))
break
if page_comment_list is not None and len(page_comment_list) > 0:
# mysql
count = batch_insert_mysql(page_comment_list)
# 如果插入的数据行数为0, 表示获取的评论为重复的
if count == 0:
flag = flag +1
# 两次获取评论相同的话 则不继续爬取,
if flag == 2:
write_error_to_file(" 抓取 %s 的评论,第 %d 页" % (song_name, page))
break
for comment in page_comment_list:
# print(comment)
write_to_file(comment.__str__())
# insert_mysql(comment)
# 分页获取 歌曲 的评论
def get_page_comment_list(song_id, song_name, page_num, pageSize):
param = get_params(page_num, pageSize)
encSecKey = get_encSecKey()
data = {
"params": param,
"encSecKey": encSecKey
}
comment_url = comment_url_base + str(song_id) + "?csrf_token="
try:
resp = requests.post(url=comment_url, data=data, headers=headers,timeout=10)
except Exception as result:
print(time.strftime('%Y.%m.%d %H:%M:%S ', time.localtime(time.time())) ," " + song_name, " 第 ",page_num, ' 页获取数据失败', result)
write_error_to_file(" 歌曲 %s 第 %d 页获取数据失败 result %s" % (song_name ,page_num, result))
return None
else:
comment_json = resp.json()
comment_list_json = comment_json["comments"]
comment_list = []
for comment in comment_list_json:
# com = {"content":comment['content'],"likedCount":comment['likedCount'],"songId":song_id,"nickname":comment['user']['nickname']}
com_obj = Comment(comment,song_id,song_name)
comment_list.append(com_obj)
return comment_list
# 获取分页参数获取加密参数
def get_params(pageNum, pageSize = 20):
if pageNum == 0:
first_param = '{rid:"", offset:"0", total:"true", limit:' + str(pageSize) + ', csrf_token:""}'
else:
offset = str(pageNum * pageSize)
# first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' % (offset, 'flase')
first_param = '{rid:"", offset:"%s", total:"%s", limit:' + str(pageSize) + ', csrf_token:""}'
first_param = first_param % (offset, 'flase')
print("first_param %s, pageNum %s, pageSize %s" % (first_param, pageNum, pageSize))
# 这里是转为 二进制
iv = b"0102030405060708"
# 这里是转为 二进制
first_key = b"0CoJUm6Qyw8W8jud"
second_key = 16 * 'F'
h_encText = AES_encrypt(first_param, first_key, iv)
# h_encText 是二进制, AES_encrypt() 第一参数需要 str ,所以把 h_encText 转为 str
h_encText = AES_encrypt(h_encText.decode('utf-8'), bytes(second_key, encoding = "utf8")+b"", iv)
return h_encText
def AES_encrypt(text, key, iv):
encryptor = AES.new(key, AES.MODE_CBC, iv)
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encrypt_text = encryptor.encrypt(bytes(text, encoding = "utf8")+b"")
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey代码中我把爬取的数据放到 txt 文件和 mysql 中。
在爬取评论的时候我发现每首歌的评论大概只能爬取1100条左右, 在继续分页查询返回的数据都是重复的,从最后一页往前分页也是一样的,所以代码中会根据插入是否插入mysql 数据判断数据是否重复(mysql中主键用的是评论的id,主键重复就不会insert,返回的更新行数是0,根据更新行数判断的)来判断是否继续爬取当前歌曲的评论数,我想这是网易避免深度分页吧,毕竟正常人也不会翻那么多评论,我还在浏览器和桌面端翻了翻中间的评论 是这样的:
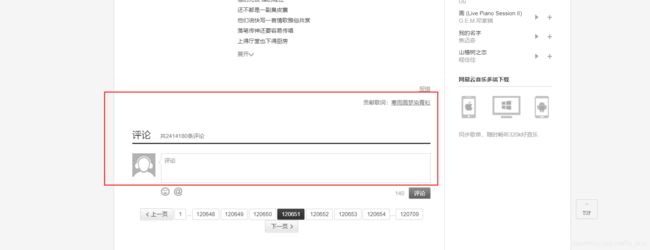

这两个是从后往前翻页的,从前往后翻的话只能翻到50页。代码中有一行是从最后一页往前分页查询的。
下面是把数据存储到本地 txt 和 mysql的代码
# 批量插入 mysql
def batch_insert_mysql(comment_list):
sql = "INSERT IGNORE INTO `yun_comment` (`id`, `song_id` ,`song_name`,`content`, `nick_name`, " \
"`liked_count`, `parent_comment_id`, `user_id`,`comment_date` ,`time`, `create_date`) VALUES "
for i in range(len(comment_list)):
comment = comment_list[i]
sql += "('%d', '%d', '%s', '%s', '%s', '%d', '%d', '%d', '%s','%d', now())," % \
(comment.__id__,comment.__songId__,transferContent(comment.__songName__),transferContent(comment.__content__),transferContent(comment.__nickname__),
comment.__likedCount__,comment.__parentCommentId__,comment.__userId__,formate_time_to_date(comment.__time__),comment.__time__)
sql = sql[:len(sql)-1]
try:
cursor = db.cursor()
result = cursor.execute(sql)
# print("result %s , sql %s" % (result, sql))
db.commit()
return result
except Exception as result:
print(time.strftime('%Y.%m.%d %H:%M:%S ', time.localtime(time.time())) ," insert error sql: %s, result:" % sql, result)
write_error_to_file(" insert error sql: %s, result %s" %(sql, result))
return 1
# 热评批量插入mysql
def hot_batch_insert_mysql(comment_list):
sql = "INSERT IGNORE INTO `yun_comment_hot` (`id`, `song_id` ,`song_name`,`content`, `nick_name`, " \
"`liked_count`, `parent_comment_id`, `user_id`, `comment_date`,`time`, `create_date`) VALUES "
for i in range(len(comment_list)):
comment = comment_list[i]
sql += "('%d', '%d', '%s', '%s', '%s', " \
"'%d', '%d', '%d', '%s','%d', now())," % \
(comment.__id__,comment.__songId__,transferContent(comment.__songName__),
transferContent(comment.__content__),transferContent(comment.__nickname__),
comment.__likedCount__,comment.__parentCommentId__,comment.__userId__,formate_time_to_date(comment.__time__),comment.__time__)
sql = sql[:len(sql)-1]
try:
cursor = db.cursor()
result = cursor.execute(sql)
# print("result %s , sql %s" % (result, sql))
db.commit()
return result
except Exception as result:
print(time.strftime('%Y.%m.%d %H:%M:%S ', time.localtime(time.time())) ," insert error sql: %s, result:" % sql, result)
write_error_to_file(" insert error sql: %s, result %s" %(sql, result))
return 1
# 转义字符
def transferContent(content):
if content is None:
return None
else:
string = ""
for c in content:
if c == "'":
string += "\\\'"
else:
string += c
return string
# time 转为 日期
def formate_time_to_date(timeStamp):
timeStampStr = str(timeStamp)
if len(timeStampStr) > 10:
timeStampStr = timeStampStr[0:10]
timeArray = time.localtime(int(timeStampStr))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
# 写入文件
def write_to_file(content):
with open(out_put_file, 'a', encoding='utf-8') as f:
# print(type(json.dumps(content)))
# dumps实现字典的序列化 ensure_ascii=False 保证输出的是中文不是Unicode编码
f.write(json.dumps(content, ensure_ascii=False)+'\n')
def hot_comment_write_to_file(content):
with open(hot_comment_out_put_file, 'a', encoding='utf-8') as f:
# print(type(json.dumps(content)))
# dumps实现字典的序列化 ensure_ascii=False 保证输出的是中文不是Unicode编码
f.write(json.dumps(content, ensure_ascii=False)+'\n')
def write_error_to_file(content):
with open(out_put_error_file, 'a', encoding='utf-8') as f:
# print(type(json.dumps(content)))
# dumps实现字典的序列化 ensure_ascii=False 保证输出的是中文不是Unicode编码
f.write(json.dumps(content, ensure_ascii=False)+'\n')
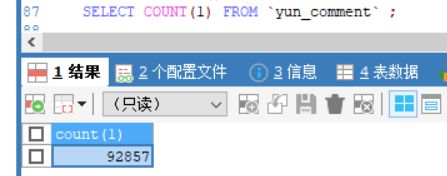
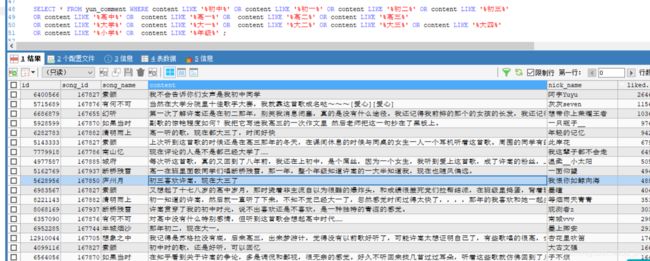
我爬了几次一共爬了31首歌,9w多数据,查了下发现 9000多条评论内容都带有学生印记的,看来很多同学都是听许嵩的歌回想起读书时光啊。

本人不是写python的,所以有些代码可能很不规范,一些异常什么的也没有处理很好,如果有问题欢迎大家提出来,我会改进的
git 地址:https://github.com/898349230/crawler/blob/master/wangyiyun.py