配置 hadoop 高可用集群的原因:如果集群只有一个 NameNode,若NameNode 节点出现故障,那么整个集群都无法使用,也就是存在单点故障的隐患,hadoop 高可用集群能够实现 standby NameNode 自动切换为 active。
HA 的架构,节点个数一般为奇数个,有两个 NameNode,一台为 active 状态,一台为 standby 状态,active NameNode 对外提供服务,standby Namenode 实时同步了 active NameNode 的元数据,当 active NameNode 节点出现故障,standby NameNode 节点可立即切换为active状态并对外提供服务,ResourceManager 同理。所以,在实际生产中一般采用 HA 架构来提高集群的可靠性。
我这里用三台机器来搭建 Hadoop 高可用集群,hadoop 版本3.2.0
集群可以自己规划,节点最好为奇数,最少为3个节点
用Hadoop用户需要相关设置,也可以直接用root用户(我这里用的是root)
集群环境下配置SSH免密码登录
注意:配置SSH免密码登录,使用hadoop身份登录虚拟机服务器,进行相关的操作。
分别在每台机器上安装
设置好hosts
192.168.217.128 hadoop301
192.168.217.129 hadoop302
192.168.217.130 hadoop303
生成SSH免密码登录公钥和私钥
在每台虚拟机服务器上执行如下命令,在每台服务器上分别生成SSH免密码登录的公钥和私钥。
ssh-keygen -t rsa
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
(2)设置目录和文件权限
在每台虚拟机服务器上执行如下命令,设置相应目录和文件的权限。
chmod 700 .ssh
chmod 644 .ssh/authorized_keys
chmod 600 .ssh/id_rsa
(3)将公钥拷贝到每台服务器
在每台虚拟机服务器上执行如下命令,将生成的公钥拷贝到每台虚拟机服务器上。
scp -r .ssh/id_rsa.pub hadoop302
scp -r .ssh/id_rsa.pub hadoop303
执行完上面的命令之后,每台服务器之间都可以通过“ssh 服务器主机名”进行免密码登录了。
注意:执行每条命令的时候,都会提示类似如下信息。
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'binghe101,192.168.175.101' (RSA) to the list of known hosts.
hadoop@binghe101's password:
在“是否确认继续连接”的地方输入“yes”,提示输入密码的地方输入相应服务器的登录密码即可,后续使用“ssh 主机名”登录相应服务器就不用再输入密码了。
jdk 
在 hadoop301 上安装
tar -zxf zookeeper-3.6.1.tar.gz -C /opt/
配置zoo.cfg
cd zookeeper-3.6.1/conf
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
zoo.cfg 内容如下
#The number of milliseconds of each tick 心跳基本时间单位,毫秒级,ZK基本上所有的时间都是这个时间的整数倍。
tickTime=2000
#The number of ticks that the initial
#synchronization phase can take
#tickTime的个数,表示在leader选举结束后,followers与leader同步需要的时间,如果followers比较多或者说leader的数据灰常多时,同步时间相应可能会增加,那么这个值也需要相应增加。当然,这个值也是follower和observer在开始同步leader的数据时的最大等待时间(setSoTimeout)
initLimit=10
#The number of ticks that can pass between
#sending a request and getting an acknowledgement
#tickTime的个数,这时间容易和上面的时间混淆,它也表示follower和observer与leader交互时的最大等待时间,只不过是在与leader同步完毕之后,进入正常请求转发或ping等消息交互时的超时时间
syncLimit=5
#the directory where the snapshot is stored.
#do not use /tmp for storage, /tmp here is just
#example sakes.
#内存数据库快照存放地址,如果没有指定事务日志存放地址(dataLogDir),默认也是存放在这个路径下,建议两个地址分开存放到不同的设备上
dataDir=/data/zookeeper
#the port at which the clients will connect
clientPort=2181
#the maximum number of client connections.
#increase this if you need to handle more clients
#maxClientCnxns=60
#Be sure to read the maintenance section of the
#administrator guide before turning on autopurge.
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
#Purge task interval in hours
#Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=hadoop301:2888:3888
server.2=hadoop302:2888:3888
server.3=hadoop303:2888:3888
同步到 hadoop302 hadoop303
scp -r /opt/zookeeper-3.6.1 root@hadoop302:/opt
scp -r /opt/zookeeper-3.6.1 root@hadoop302:/opt
启动zookeeper
在所有机器行上执行,顺序 hadoop301 hadoop302 hadoop303
/opt/zookepper-3.6.1/bin/zkServer.sh start
/opt/zookepper-3.6.1/bin/zkServer.sh status
查看zookeeper集群状态
在 hadoop301 上安装
将 hadoop-3.2.0tar.gz 上传到/opt 目录下, 并解压
tar -zxvf hadoop-3.2.0.tar.gz -C /opt/
配置Hadoop系统环境变量
同样,Hadoop的系统环境变量也需要在“/etc/profile”文件中进行相应的配置,通过如下命令打开“/etc/profile”文件并进行相关设置。
编辑/etc/profile, 在末尾添加
export HADOOP_HOME=/opt/hadoop-3.2.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
创建Hadoop的数据存储相关目录(自定义根据你自己的硬盘空间大小在相关路径下创建)
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/journalnode/data
mkdir -p /data/hadoop/hdfs/namenode
mkdir -p /data/hadoop/hdfs/datanode
以下是Hadoop相关配置,但是根据自己的实际路径及配置而修改。
编辑 /opt/hadoop-3.2.0/etc/hadoop/core-site.xml
编辑/opt/hadoop-3.2.0/etc/hadoop/hdfs-site.xml
编辑 /opt/hadoop-3.2.0/etc/hadoop/yarn-site.xml
编辑 /opt/hadoop-3.2.0/etc/hadoop/mapred-site.xml
/opt/hadoop-3.2.1/share/hadoop/common/,
/opt/hadoop-3.2.1/share/hadoop/common/lib/,
/opt/hadoop-3.2.1/share/hadoop/hdfs/,
/opt/hadoop-3.2.1/share/hadoop/hdfs/lib/,
/opt/hadoop-3.2.1/share/hadoop/mapreduce/,
/opt/hadoop-3.2.1/share/hadoop/mapreduce/lib/,
/opt/hadoop-3.2.1/share/hadoop/yarn/,
/opt/hadoop-3.2.1/share/hadoop/yarn/lib/
编辑 /opt/hadoop-3.2.0/etc/hadoop/hadoop-env.sh
#The java implementation to use. By default, this environment
#variable is REQUIRED on ALL platforms except OS X!
#export JAVA_HOME=
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0
#Some parts of the shell code may do special things dependent upon
#the operating system. We have to set this here. See the next
#section as to why....
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
export HADOOP_PID_DIR=/opt/hadoop-3.2.1/pid
export HADOOP_LOG_DIR=/var/log/hadoop
编辑 /opt/hadoop-3.2.0/etc/hadoop/yarn-env.sh
#Specify the max heapsize for the ResourceManager. If no units are
#given, it will be assumed to be in MB.
#This value will be overridden by an Xmx setting specified in either
#HADOOP_OPTS and/or YARN_RESOURCEMANAGER_OPTS.
#Default is the same as HADOOP_HEAPSIZE_MAX
#export YARN_RESOURCEMANAGER_HEAPSIZE=
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0
编辑 /opt/hadoop-3.2.0/sbin/start-dfs.sh, /opt/hadoop-3.2.1/sbin/stop-dfs.sh,在脚本开始添加
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
编辑 /opt/hadoop-3.2.0/sbin/start-yarn.sh, /opt/hadoop-3.2.1/sbin/stop-yarn.sh,在脚本开始添加
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
修改/opt/hadoop-3.2.0/etc/hadoo/workers 为如下内容
hadoop301
hadoop302
hadoop303
拷贝 hadoop-3.2.1 到 hadoop302 hadoop303
scp -r /opt/hadoop-3.2.0 root@hadoop302:/opt
scp -r /opt/hadoop-3.2.0 root@hadoop302:/opt
在hadoop302 上执行
修改vi /opt/hadoop-3.2.0/etc/hadoop/yarn-site.xml的yarn.resourcemanager.ha.id,改为如下内容
在hadoop303上执行
vi /opt/hadoop-3.2.0/etc/hadoop/yarn-site.xml删除如下property
启动journalnode
在所有机器行上执行,顺序 hadoop301 hadoop302 hadoop303
#注意,如果使用zsh 需要切换回bash
#chsh -s /usr/bin/bash
/opt/hadoop-3.2.1/sbin/hadoop-daemon.sh start journalnode
#或者通过 /opt/hadoop-3.2.1/bin/hdfs --daemon start journalnode
格式化 Namenode
在hadoop301上执行
#注意,如果使用zsh 需要切换回bash
#chsh -s /usr/bin/bash
/opt/hadoop-3.2.0/bin/hadoop namenode -format
#同步格式化之后的元数据到其他namenode,不然可能起不来
scp -r /data/hadoop/hdfs/namenode/current root@hadoop302:/data/hadoop/hdfs/namenode
scp -r /data/hadoop/hdfs/namenode/current root@hadoop303:/data/hadoop/hdfs/namenode
#格式化ZK
hdfs zkfc -formatZK
启动 hadoop
在hadoop301 上执行
#必须在bash 环境下执行,zsh 兼容模式也不行
start-dfs.sh
start-yarn.sh
hdfs haadmin -getAllServiceState
#正常启动后所看到的进程 jps 查看
2193 QuorumPeerMain
5252 JournalNode
4886 NameNode
5016 DataNode
5487 DFSZKFailoverController
页面访问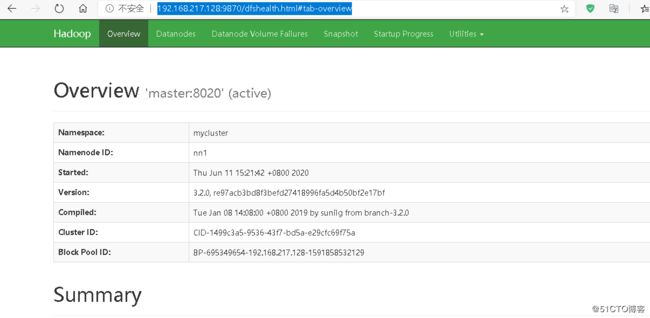
Hadooop Classpath
很多其他的计算引擎都会使用hadoop的hdfs和yarn,他们使用的方式都是通过Hadoop class path。通过如下命令,可以看到hadoop的class path 又哪些
/opt/hadoop-3.2.0/bin/hadoop classpath
spark without hadoop 的安装包就会要求配置已经安装的hadoop 的classpath,可以再spark-env.sh中添加如下配置
###in conf/spark-env.sh ###
#If 'hadoop' binary is on your PATH
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
#With explicit path to 'hadoop' binary
export SPARK_DIST_CLASSPATH=$(/path/to/hadoop/bin/hadoop classpath)
#Passing a Hadoop configuration directory
export SPARK_DIST_CLASSPATH=$(hadoop --config /path/to/configs classpath)