Kylin 流式构建
1.前提条件
• Kylin将Kafka抽象成一个等同于Hive的数据源,也就是说Kylin是作为消费者从Kafka拉取数据的。因此Kylin需要依赖Kafka的客户端Jar包,因此我们需要设置环境变量KAFKA_HOME,指向kafka的客户端Jar的路径。eg:
export KAFKA_HOME=/usr/lib/kafka/client
• 写入Kafka中的数据为相同格式的JSON数据,Kylin会从JSON中解析出一张虚拟表,虚拟表中也就是JSON格式的数据中必须包含一个timestamp类型的字段。
• Kylin假定所有往Kafka写入的数据都是规范的。因此我们需要在往Kafka写数据之前要对数据进行清洗。如果写入Kafka的JSON串中对应的度量和维度字段的value为null、空对象或者类型不匹配,在Kylin构建过程中会报错。
2.数据源配置
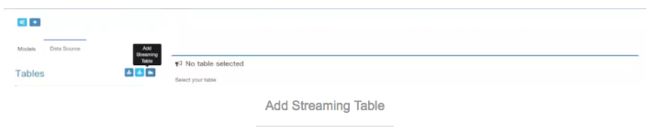
点击Data Source选择 Add Streaming Table,将要放入Kafka中JOSN的数据复制到左边框框,点击 >>,就生成了右边的虚拟表,Kylin会额外帮我们生成一些衍生时间字段,选择自己想保留的字段,为每个字段设置类型,字段中必须有一个类型是timestamp且必须是长整数类型(Why?),否则保存的时候会报错:You should choose at least one 'timestamp' type column generated from source schema。
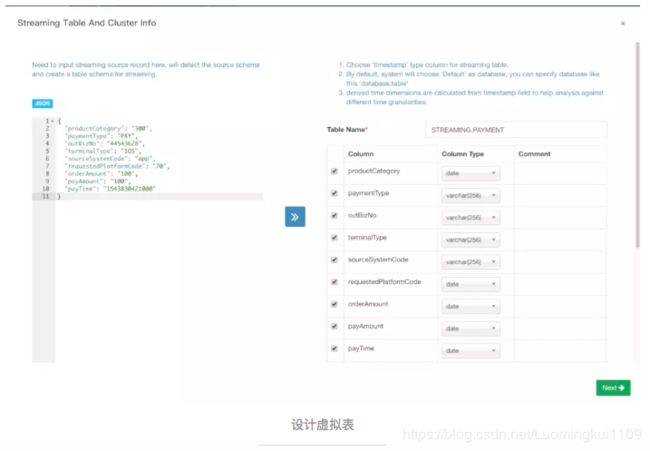

上一步点击Next,进入Kafka和数据解析设置页面,在Kafka Setting区域设置数据所在的Topic和Kafka Broker的集群地址。在Parser Setting区域设置数据解析参数,Parser Name默认为org.apache.kylin.source.kafka.TimedJsonStreamParser,Parser Timestamp Field选择表中timestamp类型的字段,Kylin会根据这个字段的值为自动为衍生时间字段赋值。Parser Properties是根据Parser Timestamp Field自动生成的,这个值会通过构造方法传递给org.apache.kylin.source.kafka.TimedJsonStreamParser。在Advanced Setting区域设置Kylin消费Kafka消息的一些配置参数。设置好上面这些以后,点击Submit就完成了数据源的设置。

3.Model配置
Model的设置跟非流式构建的步骤基本一样,只是在分区设置的时候必须指定一个分区字段,一般选择最小粒度的衍生时间字段(Why?)。

4.Cube设置
Cube的设置跟非流式构建的步骤基本一样,只是在Segment自动合并设置的地方需留意。Kylin的流式构建跟Spark Streaming的思想相似,采用微批量构建,每次微构建都会生成一个Segment。随着时间的推移,Segment越来越多,为了解决每次查询需要提前聚合的Segment越来越多,大量的Segment在HDFS上产生了大量的小文件等等问题,我们需要进行Segment的细粒度自动合并。
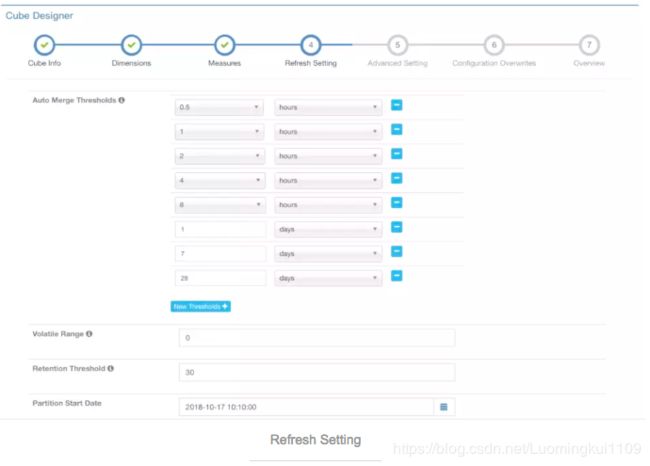
5.触发流式构建
完成了上面设置以后,数据也源源不断投递进Kafka中,这时候就可以触发流式构建了。在Kylin WebUI页面,我们点击build,就会触发一次流式构建。
触发流式构建

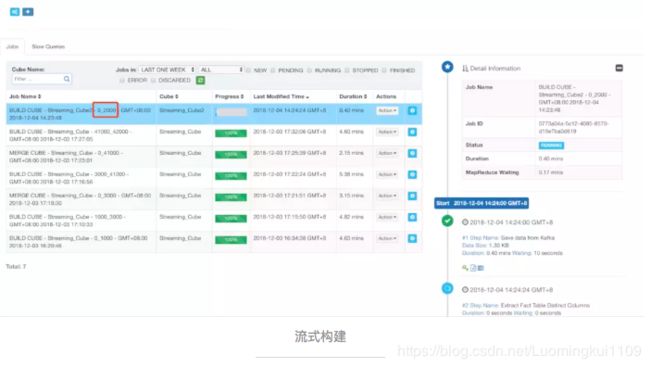
在增量构建的时候提到增量的Segment有两个属性StartDate和EndDate,在流式构建中的Segment不仅仅有StartDate和EndDate(隐藏的)(Why?),还有Kafka消息的起始offset和终止offset(可以看),kafka多个分区的情况下offset是所有分区的offset之和,同时也遵守左闭右开原则。
Kylin同样提供了HTTP 接口来帮助我们自动触发流式构建,比方说我们需要每5分钟触发一次流式构建,我们可以采用crontab命令,每5分钟触发一次构建请求:
crontab -e */5 * * * * curl -X PUT --user ADMIN:KYLIN -H "Content-Type: application/json;charset=utf-8" -d '{ "sourceOffsetStart": 0,"sourceOffsetEnd": 9223372036854775807,"buildType": "BUILD"}' http://192.168.109.134:7070/kylin/api/cubes/{CubeName}/build2
6.一些疑问的解答
6.1 Kylin流式构建怎么保证数据不丢失?
Kylin流式构建生成的Segment都包含Kafka消息的起始offset和终止offset,offset是顺序递增的且没有重叠和遗漏,这将确保没有数据丢失,一个消息只会被消费一次。
6.2 为什么要求投递到Kafka中的JSON数据结构中要包含一个业务时间戳?
①业务时间戳的粒度太细,无法在时间维度上完成深度的聚合,Kylin会自动帮我们生成一些衍生时间字段,这些衍生时间字段的值都来源于业务时间戳。
②流式构建的每个Segment除了包含起始offset,还包含数据集的StartDate和EndDate,这两个属性来源于Model设置的分区字段,分区字段又来源于上面说的衍生时间维度。
6.3 Kafka数据延迟问题对Kylin有影响吗?
没有影响,晚到达的消息会后面的Segment统计进来。每个Segment 有StartDate和EndDate两个属性。当用户按时间条件查询时,Kylin将扫描与查询时间范围相匹配的所有段。如下图:图中有三个Segment,它们的offset依次连续且无重叠(左包右闭),Seg[100-400]中的消息时间跨度是1:04 – 1:11,Seg[400 - 2000]的时间跨度是1:08 – 1:40。当用户要查询1:10的统计信息时,Kylin发现这两个Segment都可能有这个时间的消息,故而会扫描这两个Segment然后再次做汇总计算。