CVPR 2020 | 旷视研究院提出新型人-物交互检测框架,实现当前最佳

IEEE国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 大会官方论文结果公布,旷视研究院 16 篇论文被收录(其中含 6篇 Oral 论文),研究领域涵盖物体检测与行人再识别(尤其是遮挡场景),人脸识别,文字检测与识别,实时视频感知与推理,小样本学习,迁移学习,3D感知,GAN与图像生成,计算机图形学,语义分割,细粒度图像,对抗样本攻击等众多领域,取得多项领先的技术研究成果,这与已开放/开源的旷视AI生产力平台Brain++密不可分。
本文是旷视CVPR2020论文系列解读第14篇,本文提出一种新型人-物交互检测算法,可直接把人-物交互关系检测为一系列的交互点,进一步预测朝向人和物体中心的交互向量;接着,这些交互点可以配对组合人与物体的检测结果,以生成最终的交互预测。据知,本文首次提出把人-物交互检测拆分为关键点检测和组合问题,该方法在两大流行数据集V-COCO和HICO-DET做了全面实验,均取得先进的性能。

论文名称:Learning Human-Object Interaction Detection using Interaction Points
论文链接:https://arxiv.org/abs/2003.14023
目录
导语
简介
方法
整体架构
交互生成
交互点分支
交互向量分支
交互匹配
实验
对比SOTA
结论
参考文献
往期解读
导语
对图像内容超越实例层面的语义理解,已成为计算机视觉领域基本问题之一。人-物交互(HOI)检测属于视觉关系检测的一种,该任务不仅定位图像中的人和物体,还需要推理出人和物体之间的交互关系,比如「吃苹果」、「驾驶汽车」等。
由于一张图像可能包含多个人做同一类交互,一个人同时交互多个物体、多个人共享同一个交互物体,还可能存在细粒度交互的情况,导致HOI检测颇具挑战性。这些复杂而多元的交互场景给HOI检测方案的设计带来了巨大困难。
大多数现有方法以三元组(人,动作,物体)的形式检测人-物交互,并将该问题分解成两部分:物体检测和交互识别。物体检测方面,通过一个预训练的物体检测器检测出人和物体;对于交互识别,相关文献提出了若干个策略。
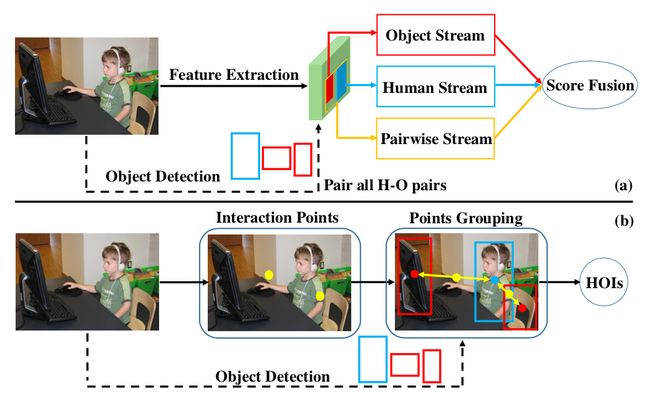
图1:大多数现有方法(a)与本文方法(b)示意图对比
现有大多数HOI检测方法使用多支路架构(见图1(a))识别交互关系。多支路架构通常包含三个独立的支路:人体支路、物体支路和配对支路。人体和物体支路分别编码人和物的外观特征,而配对支路旨在编码人和物的空间关系。接着,三个支路各自的得分进行融合,用于交互识别。
尽管提高了HOI检测性能,基于上述多支路架构的当前最佳方法是计算昂贵的。训练时,这些以实例为中心的方法需要配对所有的人和物体,来学习正/负人-物对。这意味着推理时间会随着人-物实例数量呈二次方增长,因为所有的人-物对都需要经过一遍网络,以获得最后的交互得分。
除了计算昂贵之外,这些方法还明显依赖于外观特征和一个简单的配对支路,其中配对支路是把两个框(人和物)结合起来组成一个二值图像表征来编码空间关系。本文认为,仅仅依赖于表面特征和粗糙的空间信息不足以应对复杂的交互场景,往往会造成不准确的预测。
本文试图直接把人-物对之间的交互关系检测为一系列交互点,从而探索出另一种可替代的方案来解决上述问题。
简介
本文提出了一个全新的方法用于HOI检测。受最近anchor-free物体检测算法的启发,本文提出把HOI检测看作关键点检测和分组问题(见图1(b))。该方法直接把人-物对之间的交互检测为一系列交互点,并基于这些交互点学习出指向人和物体中心点的交互向量。
本文进一步提出交互匹配方案,对交互点、交互向量和物体检测分支产生的人和物体检测框进行匹配,从而获得最后的交互预测。在两个HOI检测数据集(V-COCO和HICO-DET)上的大量实验表明,该方法大幅超越现有的以实例为中心的方法,取得当前最佳结果。
方法
整体架构
本文方法整体架构如图2所示,它包含物体检测和交互预测两部分,其中最大的设计创新是针对后者的全新表征,它包含三步:1)特征提取,2)交互生成,3)交互分组。

图2:本文HOI检测框架示意图,包含一个定位和交互预测阶段
从backbone提取的特征输入至交互生成模块,得到交互点和交互向量。交互点是人-物对之间的中心点,也是交互向量的起点。最终,交互点和交互向量联合已检测的人、物检测框输入至交互匹配模块,得到最终的HOI三元组(人,动作,物体)预测。
交互生成
交互生成模块包含两个并行的分支:交互点分支和交互向量分支。两个分支均以提取自backbone的特征作为输入。
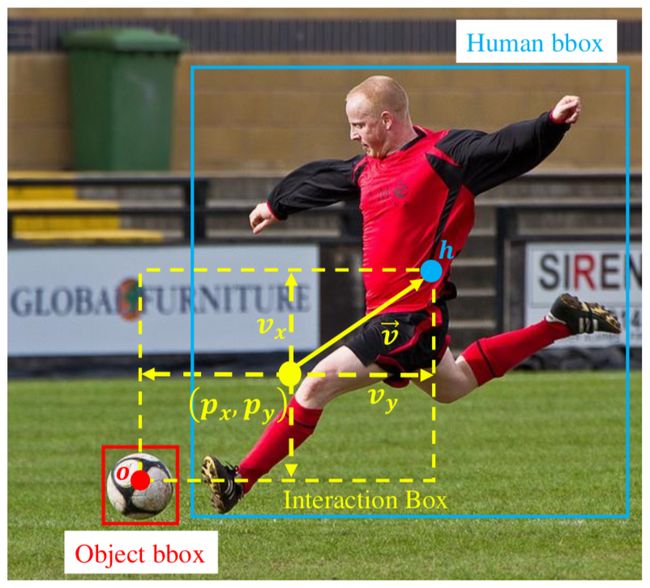
图3:示例图像中交互点和交互向量的图示
交互点分支。给定来自backbone的特征图,通过单个3x3卷积层生成交互点热图。训练时,交互点热图通过包含多个峰值的ground-truth热图监督,其中每个交互点均由相同的高斯核定义。
注意,在anchor-free物体检测框架中,单个关键点只能表示一个物体类别。不同于物体检测,在HOI检测中,单一关键点定位可以对应多个交互类别,因为给定一个物体,人可以与之有多个交互关系。图3给出了一个交互点示例。注意,这里的交互点是针对有对应物体的交互类别所定义的,对于没有对应物体的交互类别,比如「走路」、「微笑」等,则直接定义人的中心点为交互点。
交互向量分支。如图3所示,基于交互点,交互向量分支旨在预测朝向人体中心点的交互向量,该分支通过训练能够预测无符号交互向量的模长。和交互点分支相同,本文使用一个3x3卷积层生成两通道无符号的交互向量图,其中一个是交互向量在水平方向上的长度,另一个是在垂直方向上的长度。
推理阶段,基于交互点和无符号交互向量,可以计算出4个可能的人体中心点坐标:

并进一步把交互框定义为依据等式(1)所计算出4个坐标所组成的矩形框。
交互匹配
为了高效而精确地对人-物的交互点和物体检测框进行匹配,本文进一步提出交互匹配方案,利用软约束过滤大部分人-物负对,如图4所示。

图4:交互匹配方案示意图
它包含3个输入:人/物检测框,提取自交互热图的交互点,交互点对应位置的交互向量。借助等式(1),交互框的4个角点坐标可以由给定的交互点和无符号交互向量计算得到。
如果交互框、人/物体检测框和4个向量长度满足条件(2)中的约束,那么当前的人/物检测框以及交互点被认为是HOI正对。
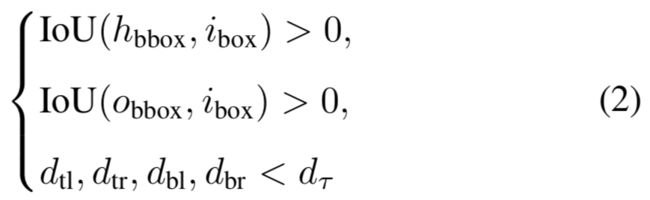
交互匹配方案如算法1所示:

算法1:交互匹配
实验
本文给出了本文方法和当前最优方法的对比。
对比SOTA
表1给出了V-COCO数据集上的对比结果。
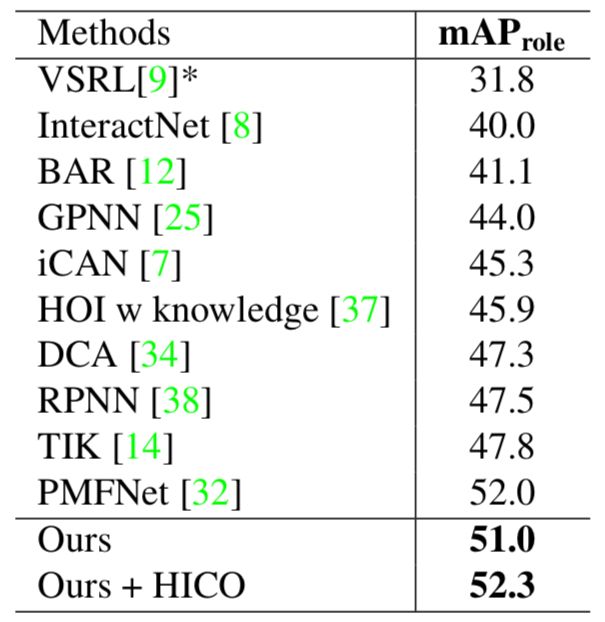
表1:V-COCO数据集上与当前最优方法的结果对比(mAP_role)
表2给出了HICO-DET数据集上的对比结果。
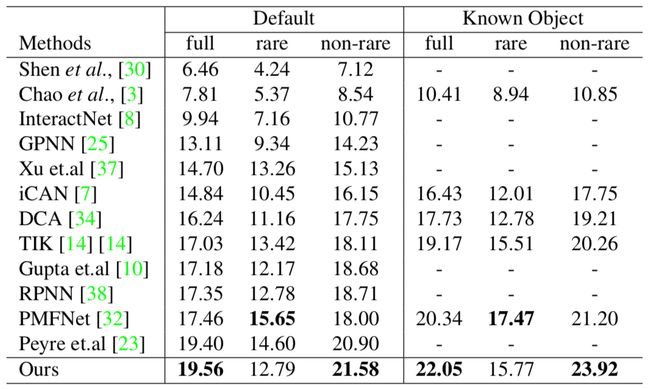 表2:HICO-DET数据集上与当前最优方法的结果对比(mAP_role)
表2:HICO-DET数据集上与当前最优方法的结果对比(mAP_role)
结论
旷视研究院提出一个基于点的框架用于HOI检测,它把HOI检测视为一个关键点检测和分组的问题。首先,关键点检测网络生成交互点及其相应的交互向量;接着,通过交互匹配机制,物体检测分支的人-物检测框直接和这些交互点继续配对。在两个HOI检测数据集上的实验证明了该方法均优于当前最佳结果。
入群交流
欢迎加入旷视基础模型技术交流群

或添加helloworld0079回复“基础模型”入群
参考文献
Yuwei Chao, Yunfan Liu, Xieyang Liu, Huayi Zeng, and Jia Deng. Learning to detect human-object interactions. InWACV, 2018.
Chen Gao, Yuliang Zou, and Jia-Bin Huang. iCAN: Instance-centric attention network for human-object interac- tion detection. In BMVC, 2018.
Yong-Lu Li, Siyuan Zhou, Xijie Huang, Liang Xu, Ze Ma, Yan-Feng Wang Hao-Shu Fang, and Cewu Lu. Transferable interactiveness knowledge for human-object interaction de- tection. In CVPR, 2019.
Tianfei Zhou, Wenguan Wang, Siyuan Qi, Jianbing Shen,and Haibin Ling. Cascaded human-object interaction recog-nition. In CVPR, 2020.
Julia Peyre, Ivan Laptev, Cordelia Schmid, and Josef Sivic. Detecting unseen visual relations using analogies. In ICCV, 2019.
Tiancai Wang, Rao Muhammad Anwer, Muhammad Haris Khan, Fahad Shahbaz Khan, Yanwei Pang, and Ling Shao. Deep contextual attention for human-object interaction de- tection. In ICCV, 2019.
Saurabh Gupta and Jitendra Malik. Visual semantic role la- beling. arXiv preprint arXiv:1505.04474, 2015.
YuweiChao,ZhanWang,YugengHe,JiaxuanWang,andJia Deng. HICO: A benchmark for recognizing human-object interactions in images. In ICCV, 2015.
往期解读
CVPR 2020 | 旷视研究院提出PVN3D:基于3D关键点投票网络的单目6DoF位姿估计算法
CVPR 2020 | 旷视研究院提出SAT:优化解决半监督视频物体分割问题
CVPR 2020 | 旷视研究院提出新方法,优化解决遮挡行人重识别问题
CVPR 2020 Oral | 旷视研究院提出Circle Loss,革新深度特征学习范式
CVPR 2020 Oral | 旷视研究院提出双边分支网络BBN:攻坚长尾分布的现实世界任务
CVPR 2020 Oral | 旷视研究院提出针对语义分割的动态路径选择网络
CVPR 2020 | 旷视研究院提出数据不确定性算法 DUL,优化人脸识别性能
CVPR 2020 Oral | 旷视研究院提出密集场景检测新方法:一个候选框,多个预测结果
CVPR 2020 | 旷视研究院提出UnrealText,从3D虚拟世界合成逼真的文字图像
CVPR 2020 Oral | 旷视研究院提出对抗攻击新方法DaST:无需真实数据训练替身模型
CVPR 2020 Oral | 旷视研究院提出注意力归一化AN,优化图像生成任务性能
CVPR 2020 | 旷视研究院提出SQE:多场景MOT参数自优化度量指标
CVPR 2020 | 旷视研究院探究优化场景文字识别的「词汇依赖」问题
传送门
欢迎大家关注如下 旷视研究院 官方微信号????
