2D/3D人体姿态估计 (2D/3D Human Pose Estimation)
1. 基本概念
- 算法改进入口
- 网络设计
- 特征流
- 损失函数
- 数据集的重要性:只要有一个好的、针对性的数据集,问题都可以解决
- 过集成新一代AutoML技术,可降低算法试错成本
- 人体姿态估计(Human Pose Estimation):是指图像或视频中人体关节的定位问题。 也可表述为:在所有关节姿势的空间中搜索特定姿势。
- 2D姿态估计(2D Pose Estimation):从RGB图像估计每个关节的2D Pose(x,y)坐标。
- 3D姿态估计(3D Pose Estimation):从RGBD图像中估计每个关节的3D Pose(x,y,z)坐标。
- Human Pose Estimation:又名Human Keypoint Detection
- 人体姿态估计方法可分为:
- 基于模型的生成方法:Pictorial Structure Model (PSM)是最流行的基于模型的生成方法,传统的PSM将人体视为关节结构。该模型通常由两部分组成,分别对每个身体部位的外观和相邻部位之间的空间关系进行建模。D
- 人体位姿
- 位姿中的每一个坐标点称为一个“部分(part)”或关节(joint)或关键点(keypoint)
- 两个部分之间的有效连接称为一个“对(pair)“(或肢体)
- 不是所有的关节之间的两两连接都能组成有效pair(肢体)
- 常用术语:
- 基于判别的方法:把姿态估计当作一个回归问题
| 缩写 | 全称 |
|---|---|
| mAP | mean Average Precision |
| AP | Average Precision |
| IoU | Intersection over Union |
| OKS | Object Keypoint Similarity |
| AR | Average Recall |
| MPJPE | Mean Per Joint Position Error |
1.1 姿态估计的难点
- 小且几乎看不见的关节
- 部分遮挡(partial occlusion)
- 不同视角(view-point)
- 衣服颜色(black is bad)及材质
- 光照变化(lighting change)
- 背景杂乱(background clutter)
1.2 人体结构化特性
- 身体部位比例
- 左右对称性
- 互穿性约束
- 关节界限(例如肘部不能向后弯曲)
- 身体的连通性(例如手腕与肘部刚性相关)
1.3 评价指标(Evaluation Metrics)
1.3.1 2D姿态估计评价指标
-
Percentage of Correct Parts - PCP(正确四肢的百分比)
- 如果两个预测关节位置和真实关节位置之间的距离小于肢体长度的一半(通常表示为[email protected]),则认为检测到肢体(正确的部分)
- 测量肢体的召回率。缺点是,由于较短的肢体具有较小的阈值,因此它对较短的肢体的惩罚更大
- PCP越大,模型越好
-
Percentage of Correct Key-points - PCK (正确关节的百分比)
- 如果预测关节和真实关节之间的距离在某个阈值内,则认为检测到的关节是正确的
- [email protected]:阈值=头骨连接的50% (head bone link)
- [email protected]:预测关节和真实关节之间的距离<0.2*躯干直径 (torso diameter)
- 有时采用150mm作为阈值, 由于较短的肢体具有较小的躯干和头部骨骼连接,因此可以缓解较短肢体的问题
- PCK可用于2D和3D
-
Percentage of Detected Joints - PDJ (检出关节的百分比)
- 如果预测关节和真实关节之间的距离在躯干直径的某一比例范围内,则认为检测到的关节是正确的
- [email protected]=预测关节和真实关节之间的距离<0.2*躯干直径
-
Object Keypoint Similarity (OKS) based mAP
- 用于COCO关键点检测挑战赛中
O K S = ∑ i exp ( − d i 2 / 2 s 2 k i 2 ) δ ( v i > 0 ) ∑ i δ ( v i > 0 ) OKS = \frac{\sum_{i} \exp \left(-d_{i}^{2} / 2 s^{2} k_{i}^{2}\right) \delta\left(v_{i}>0\right)}{\sum_{i} \delta\left(v_{i}>0\right)} OKS=∑iδ(vi>0)∑iexp(−di2/2s2ki2)δ(vi>0)
d i d_i di:检测到的关键点与相应的真实值(ground truth)之间的欧几里德距离
v i v_i vi:真实值(ground truth)的可见度标志
s s s:对象比例
k i k_i ki:控制衰减的每个关键点常量
- 用于COCO关键点检测挑战赛中
1.3.2 3D姿态估计评价指标
- MPJPE(Mean Per Joint Position Error)
- 平均每关节位置误差是3D人体姿态估计中最常用的评价指标
- 每关节的位置误差是一个关节的Ground真实值和预测值之间的欧几里德距离
- T样本数量
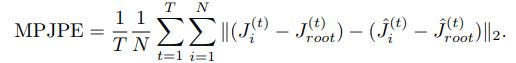
1.4 姿态估计分类
- 单人姿态估计:Single-Person Skeleton Estimation
- 多人姿态估计:Multi-Person Pose Estimation
- 人体姿态跟踪:Video Pose Tracking
- 3D姿态估计:3D Skeleton Estimation
1.5 姿态估计方法
1.5.1 Top-Down
- 步骤:
- 第一步:找到图片中所有的人
- 第二步:对每个人做姿态估计
- 第三步:寻找每个人的关键点
- 应用场景:
- 单人姿态估计
1.5.2 Bottom-Up
- 步骤:
- 第一步:找到图片中的所有parts(关键点), 比如头、左手、右手
- 第二步:把这些parts(关键点)组装成一个个人
1.6 常用关键资源
- OpenVINO™ Toolkit Pre-Trained Models (Human Pose Estimation)
- learnopencv (Human Pose Estimation)
- openpose (原作者)
2. 数据源类型+数据集+代码
2.1 数据源类型分析
2.1.1 数据源类型
- RGB图像
- 特征:形状、颜色和纹理
- 用途:提取兴趣点和光流
- 深度图像
- 深度信息对光照变化不敏感
- 深度信息对颜色和纹理不变性
- 可靠地估计人体轮廓和骨架
- 提供场景中丰富的三维结构信息
- RGB+D图像
- 骨骼数据
- 包含人体关节位置
2.1.2 可用信息
- 空间信息 (spatial information)
- 时间信息(temporal information)
- 结构信息(structural information)
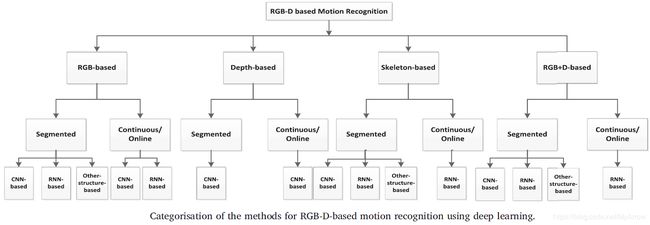
2.1.3 不同数据类型的识别方法
2.2 姿态数据集
| 序号 | 数据集 | 时间 | 人数 | 样本数 | 指标/关节数 | 用途及特点 |
|---|---|---|---|---|---|---|
| 1 | PoseTrack | 人体及关键点的跟踪数据集 | ||||
| 2 | CrowdPose | |||||
| 3 | Human3.6M | 输入RGB, 输出3D人体关键点 | ||||
| 4 | DensePose | 输入RGB,输出3D Shape | ||||
| 5 | COCO | 2016 | 多人 | 200K | OKS/18 | 1) 输入RGB, 输出2D人体关键点 2) 200K图像,250K关节标记实例 3) 2016冠军:OpenPose (CMU AP:0.605) 4) 2017冠军:CPN (Megvii AP:0.721) 5) 2018冠军:MSPN (Megvii AP:0.764) 6) 2018亚军: SB (MSRA AP:0.745) 7) 2019冠军:RSN (Megvii AP=0.771) 8) 2019亚军:DarkPose (UESTC AP=0.764) |
| 6 | MPII | 2014 | 多人 | 25K | PCKh/15 | (互联网采集)此前的Paper都是基于FLIC和LSP做评估 |
| 7 | FLIC | 2013 | 5K | 来源于30部电影 | ||
| 8 | LSP | 2010 | 单人 | 2K | /14 | 运动员运作 |
| 9 |
- OpenPose:Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields 【code】
- CPN: Cascaded Pyramid Network for Multi-Person Pose Estimation 【code 】
- MSPN:Rethinking on Multi-Stage Networks for Human Pose Estimation 【code 】
- 第一,使用图像分类表现较好的网络(如 ResNet)作为多阶段网络的单元网络;
- 第二,提出逐阶段传递的信息聚集方式,降低信息损失;
- 第三,引入由粗到精的监督,并进行多尺度监督
- 与HourGlass的比较:Hourglass 在重复下采样和上采样的过程中,卷积层的通道数是相同的。这是因为高层语义信息更强,需要更多通道表征。下采样时,Hourglass 变体会导致特征编码(Encoder)无法很好地表达特征,从而造成一定程度上的特征信息丢失。相比于下采样,上采样很难更优地表征特征,所以增加下采样阶段的网络能力对整体网络会更有效
- SB:Simple Baselines for Human Pose Estimation and Tracking
- RSN:Res-Steps-Net for Multi-Person Pose Estimation
- DarkPose:Distribution-Aware Coordinate Representation for Human Pose Estimation 【code】
- FPD:Fast Human Pose Estimation 【code】
2.2.1 RGB数据集
- Leeds Sports Pose (LSP) Dataset
- Frames Labeled In Cinema (FLIC)
- MPII Human Pose Dataset
- MS COCO Keypoint Leaderboard
- AI Challenge
- PoseTrack
2.2.2 RGB-D数据集

2.3 代码
- Pytorch-Human-Pose-Estimation
- microsoft / human-pose-estimation.pytorch
- facebookresearch / DensePose
- 数据集
- CMU-Perceptual-Computing-Lab / openpose C++
- 数据集
- Convolutional Pose Machines
- Fast Human Pose Estimation CVPR2019
- DarkPose- UESTC
3. 基于RGB图像的2D姿态估计 (2D Pose Estimation)
- 基于RGB图像
3.1 经典方法
| 序号 | 方法 | 特点 |
|---|---|---|
| 1 | 通过一个全局Feature, 把姿态估计问题当成分类或回归问题直接求觖 | 精度一般,要求背景干净 |
| 2 | 基于图模型(Pictorial Stucture Model),对单个Part使用DPM来获得, 同时需要pair-wise关系来优化关键点间的关联 |
精度较高 |
- 经典方法专注以下两个维度:
- 特征表示(Feature Presentation):如HOG, Shape Context, SIFT等Shallow feature
- 关键点的空间位置关系:如Pictorial Structure Model
- 这两个维度在深度学习时代也是到头重要的, 只是深度学习会把特征提取、分类、空间位置的建模都在一个网络中直接建模,这样更方便设计和优化。
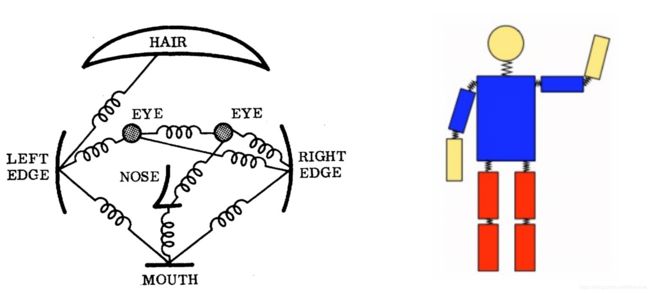
3.1.1 图像结构框架(Pictorial Structures Framework)
- 原理:结构化的预测任务
- 通过部件(parts)的集合来表示一个对象,这些部件以可变形的 方式进行排列
- 一个部件(part)是一个外观模板,它被用于在图像中进行匹配
- 部件通过像素的位置和方向进行参数化,生成的结构可以对关节运动进行建模 - 局限性
- 姿态模型不依赖图像数据,需要不断丰富模型的表示能力
- 模型
3.1.2 变形部件模型(Deformable Part Models)
- 原理
- DPM是模板的集合,这些模板以可变形的方式进行排列,每个模型有一个“全局模板+局部模板”
- 这些模板在图像中匹配以识别/检测对象
- 基于零件的模型可以很好地为关节建模
- 局限性
- 模型的表现力有限
- 没有在全局范围内加以考虑
3.2 基于深度学习
- 关键里程碑
| 序号 | 算法 | 时间 | 特点 | 作者 |
|---|---|---|---|---|
| 1 | Convolutional Pose Machine (CPM) | 2016 | 从CPM开始,神经网络可以E2E地把特征表示以及空间点的位置关系建模进去(隐式建模) | CMU Yaser Sheikh (OpenPose) |
| 2 | Hourglass | 2016 |
- Heatmap:保存了空间位置信息
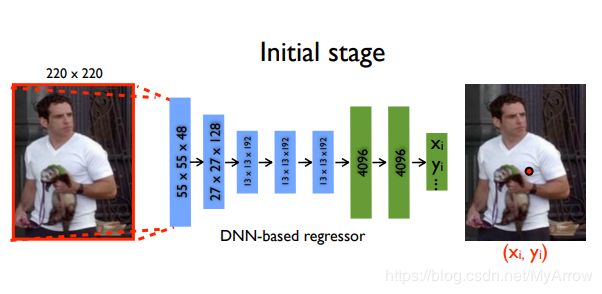
3.2.1 DeepPose (CVPR’14)
- 原理
- 姿态估计:被作为基于CNN的身体关节回归问题
- 可使用级联回归器以获得更好的结果
- 可使用整体方式进行推理,即可推导出隐藏的关节
- 模型
- 主干网络:AlexNet
- 两个全连接层
- 输出2K个关节坐标
- 损失函数:L2
- 局限性
- 回归XY坐标位置是困难的
- 增加了学习的复杂度
- 泛化能力差
- 通过级联优化

- 结果
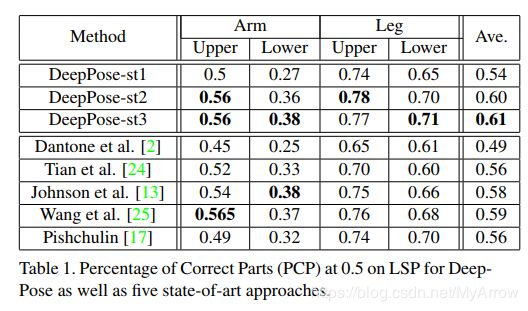
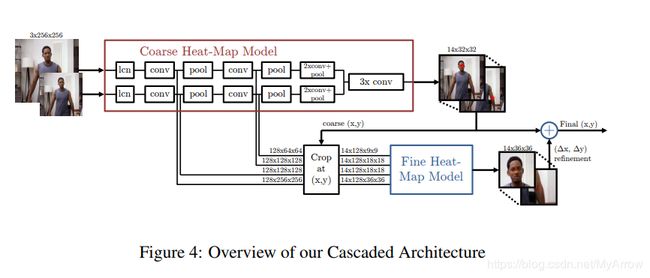
3.2.2 Efficient Object Localization Using Convolutional Networks (CVPR’15)
-
原理
- 通过并行运行多个分辨率的图像来生成热图(heatmaps),同时捕获各种尺度的特征
- 输出是离散的热图,而不是连续回归
- 热图预测关节在每个像素处发生的可能性
- 热图模型非常成功,随后的许多论文都预测了热图,而不是直接回归
- heatmap

-
模型
- Coarse Heat-Map Model:产生一个粗略的heatmap(关节)位置
- Fine Heat-Map Model: 以粗略的关节位置为中心,取一个小图求解更精确的关节位置
- 关键特征:ConvNet和图形模型的联合使用,图形模型学习关节之间的典型空间关系
- 损失函数:预测热图与目标热图间的Mean Squared-Error (MSE) 距离
-
局限性
- 缺乏结构化模型
- 对人体结构进行建模应该使定位可见的关键点变得更加容易,并且可以估计被遮挡的关键点
-
结果

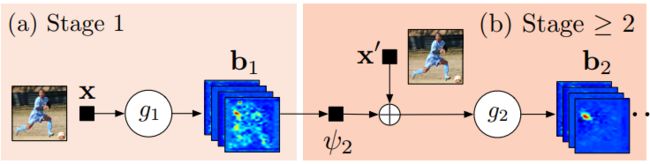
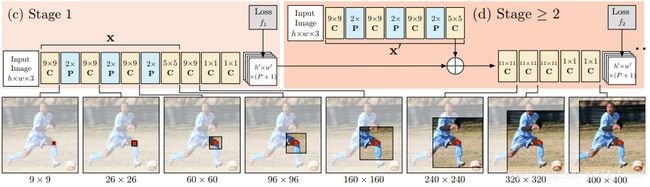
3.2.3 Convolutional Pose Machines (CVPR’16)
-
原理
- 学习长距离的空间关系:通过使用更大的感受野来实现
-
模型
- Convolutional Pose Machines (CPM) = 图像特征提取模型 + 预测模型
- 使用中间监督(intermediate supervision)以解决多层网络梯度消失的问题
-
优点
- 引入了一个创新的CPM 框架
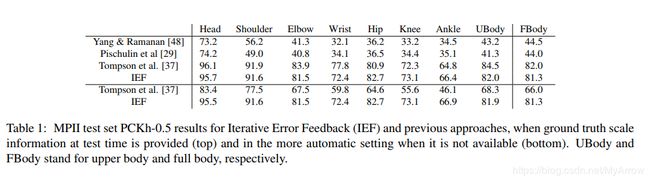
3.2.4 Human Pose Estimation with Iterative Error Feedback (CVPR’16)
-
原理
- 预测当前估计的错误并迭代地纠正它们
- 不是一次性直接预测输出,而是通过反馈错误预测逐步改变初始解的自校正模型,这个过程称为迭代错误反馈(IEF)
-
模型
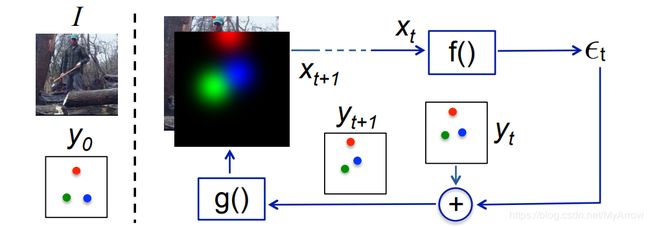
ϵ t = f ( x t ) \epsilon_{t}=f\left(x_{t}\right) ϵt=f(xt)
y t + 1 = y t + ϵ t y_{t+1}=y_{t}+\epsilon_{t} yt+1=yt+ϵt
x t + 1 = I ⊕ g ( y t + 1 ) x_{t+1}=I \oplus g\left(y_{t+1}\right) xt+1=I⊕g(yt+1)
f ( ) 和 g ( ) f()和g() f()和g():由学习产生,其中 f ( ) f() f()就是CNN -
迭代过程效果

-
结果
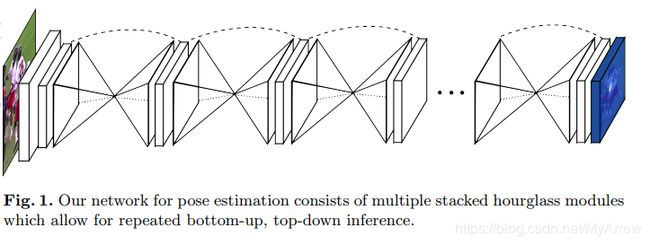
3.2.5 Stacked Hourglass Networks for Human Pose Estimation (ECCV’16)
- 原理
- 堆叠的沙漏网络(stacked hourglass network)
- 网络由池化和上采样层组成,看起来像一个沙漏
- 沙漏的设计是由需要捕捉每一个尺度上的信息驱动的
- 虽然局部证据对于识别面部和手部等特征至关重要,但最终的姿势估计需要全局背景。
- 人的方位、四肢的排列以及相邻关节之间的关系是在图像中不同尺度下最容易识别的线索之一(较小的分辨率捕获高阶特征和全局上下文)
- 中间监督(Intermediate supervision):应用于每个沙漏阶段的预测,即监督堆栈中每个沙漏的预测,而不仅仅是最终的沙漏预测。
- 模型
- Bottom-up processing (从高分辨率到低分辨率)
- Top-down processing (从低分辨率到高分辨率)
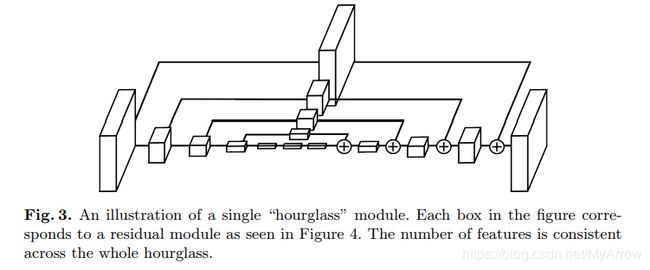
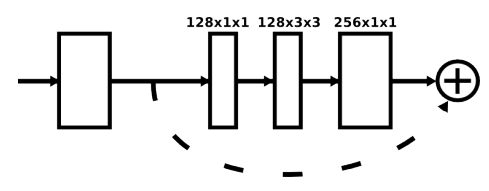
- 贡献
- 它是一个2D姿态估计的Landmark,不仅提供了一个创新且直觉的架构,且打败了以前的所有模型
- 沙漏在每个尺度都捕捉信息。全局和局部的信息被完全捕获并被网络用来学习预测。
- 结果
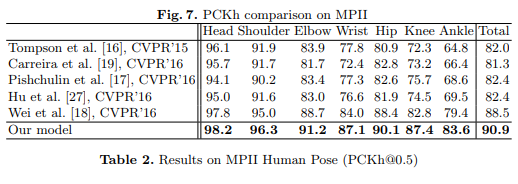
3.2.6 Simple Baselines for Human Pose Estimation and Tracking (ECCV’18)
- 目标
- 让方法变得简单,且效果不差
- 一个简单的体系结构比使用跳过连接(保留每个分辨率的信息)的体系结构表现得更好
- 模型
- 一个ResNet + 几个卷积层
- 使用MSE(Mean Squared Error)作为预测heatmap与ground heatmap间的损失函数
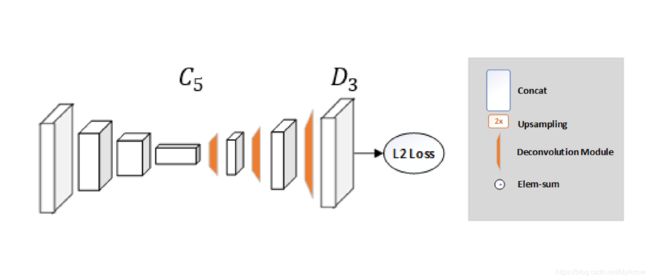
- 结果
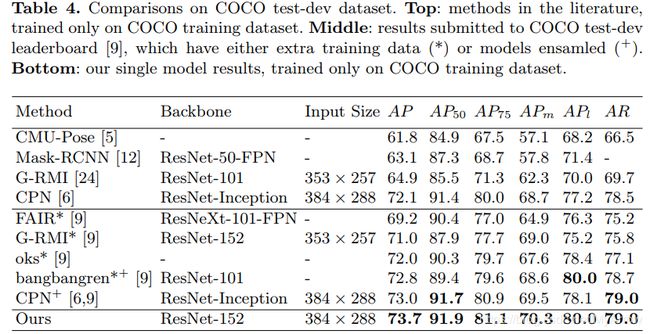

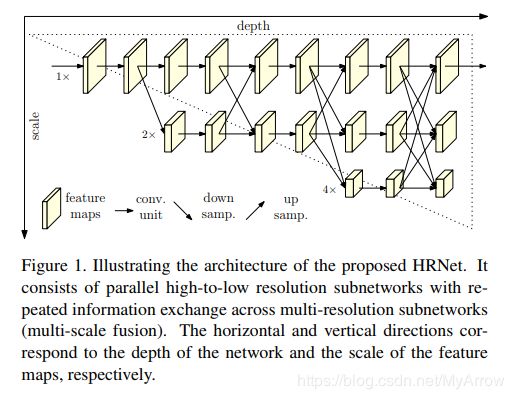
3.2.7 Deep High-Resolution Representation Learning for Human Pose Estimation [HRNet] (CVPR’19)
- 原理
- HRNet (High-Resolution Network):在COCO数据集中,HRNet模型在关键点检测、多人姿态估计和姿态估计任务上都优于现有的所有方法
- 以前的研究大多是从高→低→高分辨率表征;而HRNet在整个过程中都保持了高分辨率的表示,并且工作得非常好
- 另一个优点是这种架构不使用中间热图监控,不像堆叠的沙漏
- 使用MSE损失对热图进行回归
- 模型
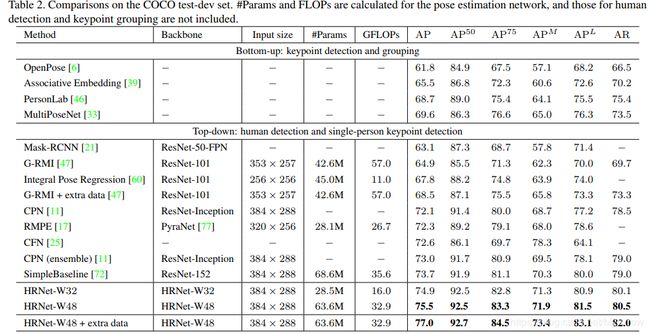
- 结果
3.2.8 OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields (CVPR’17)
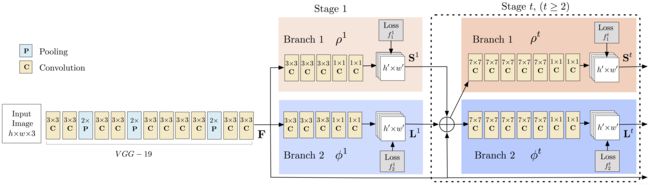
- 原理 :采用bottom-up方法:首先检测出图像中所有人的关节(关键点),然后将检出的关键点分配给每个对应的人
- 工作流程
- 1)使用前面的几个网络层(VGG-19),从图像中提取特征图
- 2)然后这些特征被传给两个平行的卷积层分支
- Part Confidence Maps (PCM):第一个分支用来预测 18 个置信图(S),每个图代表人体骨架中的一个关节,下图为左肩关节的置信图(Confidence maps)和关联图 (Affinity maps)

- Part Affinity Fields (PAF):第二个分支预测一个关节关联(PA: Part Affinities)的2D向量场(2D Vector Fields)集合(L),它编码了关节间的关联度(degree of associatoin between parts),下图为neck与left shoulder间的关节关联场(PAF:Part Affinity Field)

- Part Confidence Maps (PCM):第一个分支用来预测 18 个置信图(S),每个图代表人体骨架中的一个关节,下图为左肩关节的置信图(Confidence maps)和关联图 (Affinity maps)
- 3)通过贪婪推理分析置信度图和关联图,得到图像中所有人的二维关键点
- 4)使用关节置信图(Part Confidence Maps),可以在每个关节对之间形成二分图
- 5)使用 PAF 值,二分图里较弱的连接被删除
- 6)通过上述步骤,可以检出图中所有人的人体姿态骨架,并将其分配给正确的人
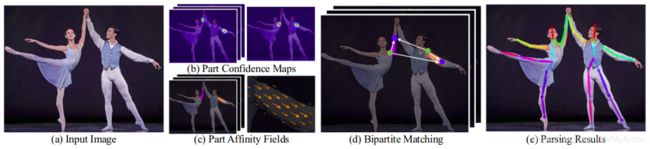
- 模型
- 结果
4. 基于RGB图像的3D姿态估计 (3D Pose Estimation)
4.1 3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network (ACCV 14)
-
原理
- 预测三维关节位置最简单的方法:训练一个网络,使其直接从图像中回归。
-
模型
- 该框架由两类任务组成:
- 关节点回归任务:输入:包含测试者的bounding box图像;输出:关节与根关节的相对位置
- 关节点检测任务:输入:包含测试者的bounding box图像;输出:分类一个局部窗口是否包含指定的关节

- 该框架由两类任务组成:
-
结果
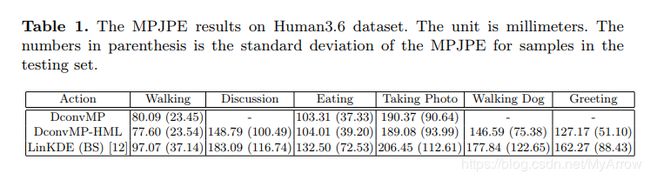
4.2 3D Human Pose Estimation = 2D Pose Estimation + Matching (CVPR’17)
- 原理
- 不直接从图像预测3D位姿,而是预测2D位置,然后推断3D位姿
- 给定一个3D姿态库(本质上是3D姿态的集合),它们生成大量的2D投影。给定这组成对(2D,3D)数据训练集和来自2D姿势估计算法的预测值;返回一个3D位姿 ,且此3D位姿的一个2D投影与此2D样本最匹配
- 它基于以下两个条件:
- 深度神经网络已经彻底改变了二维姿态估计,产生了非常好的结果
- “大数据”3D mocap数据集很容易获得,通过简单的记忆,可以更容易地将预测的2D姿势“提升”到3D
- 模型
p ( X , x , I ) = p ( X ∣ x , I ) ⋅ p ( x ∣ I ) ⋅ p ( I ) p(X,x, I) = p(X|x,I) \cdot p(x|I) \cdot p(I) p(X,x,I)=p(X∣x,I)⋅p(x∣I)⋅p(I)- 3 D P o s e : X ∈ R N × 3 3D Pose:X \in R^{N\times3} 3DPose:X∈RN×3
- 2 D P o s e : x ∈ R N × 2 2D Pose:x \in R^{N \times 2} 2DPose:x∈RN×2
- 输 入 图 像 : I 输入图像:I 输入图像:I
- 关 节 点 个 数 : N 关节点个数:N 关节点个数:N
- p ( X ∣ x , I ) p(X|x,I) p(X∣x,I):被建模为非参数近邻模型(NN: Nearest-Neighbor)
- p ( x ∣ I ) p(x|I) p(x∣I):是一个CNN,即: p ( x ∣ I ) = C N N ( I ) p(x|I) = CNN(I) p(x∣I)=CNN(I),CNN返回N个2D heatmaps, CNN是一个CPM(Convolutional Pose Machine)
- p ( X ∣ x ) p(X|x) p(X∣x):建模为一个Nearest Neighbour,它返回一个Nearest neighbor (1NN)3D深度
- 结果

4.3 Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach (ICCV 2017)
- 原理
- 这种方法既利用了二维关节位置,又利用了原始图像的中间特征表示
- 提出了一种弱监督和端到端的方法,该方法在呈现两级级联结构的深层神经网络中使用二维和三维混合标记
- 二维标注作为三维姿态估计的弱标签
- 二维数据不具有三维的Ground Truth,但在自然图像中具有多样性
- 为了预测二维图像上的三维姿态,引入了几何损失
- 模型
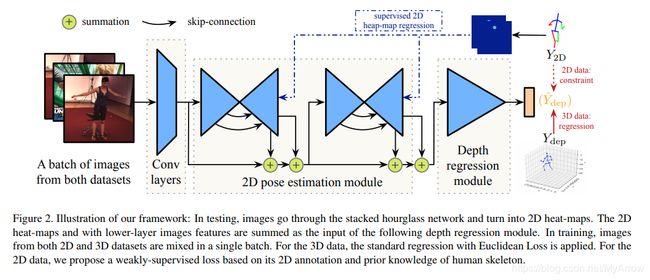
- 2D Pose Estimation module : A stacked hourglass module
- Depth Regression Module: 包含4个残差&池化模块
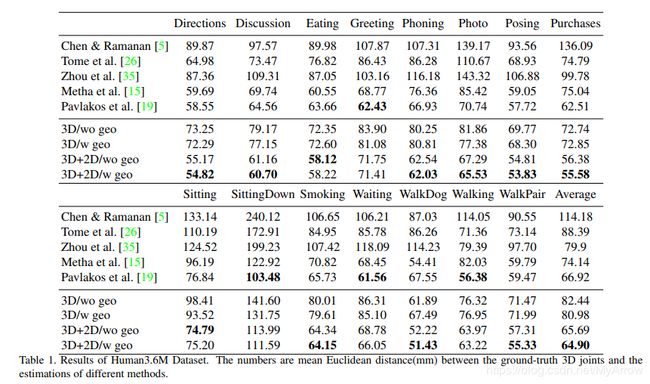
- 结果

4.4 A Simple Yet Effective Baseline for 3D Human Pose Estimation (ICCV’17)
- 原理
- 探讨了三维姿态估计的误差来源
- 三维姿态估计可以分为两个阶段:图像→二维姿态→三维姿态
- 通过一个简单直观的架构,本文了解错误是源于有限的二维姿态(视觉)理解,还是源于未能将二维姿势映射到三维位置
- 模型
- 具有batchnorm、dropout和RELUs以及残差连接的多层神经网络
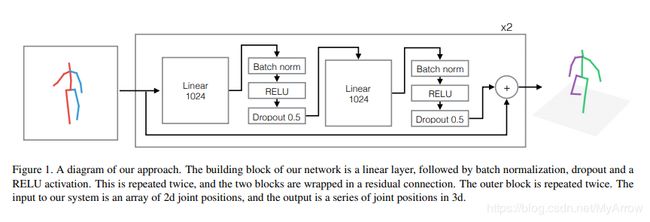
- 具有batchnorm、dropout和RELUs以及残差连接的多层神经网络
- 结果

4.5 Integral Human Pose Regression (ECCV’18)
- 原理
- 最佳的二维姿态估计方法都是基于检测的
- 为每个关节生成一个似然热图
- 并将该关节定位为地图中似然最大的点
- 同时,将热图扩展到三维姿态估计中
- 尽管性能良好,但热图表示在本质上有以下缺点:
- “取最大值”运算是不可微的,防止了训练的端到端
- 由于深度神经网络的下采样步骤,热图的分辨率比输入图像的分辨率低,这导致不可避免的量化误差
- 使用分辨率更高的图像和热图有助于提高精度,但需要计算和存储,特别是对于三维热图
- 现有的工作要么基于热图,要么基于回归
- 本文使用一个简单的操作可以将热图表示和关节回归组合在一起,它将“取最大值”操作修改为“取期望值”
- 关节被估计为热图中所有位置的积分,由它们的概率加权(从似然性标准化),这种方法称为积分回归(软argmax)
- 它既有热图表示方法和回归方法的优点,又避免了它们的缺点。积分函数是可微的,允许端到端的训练
- 模型
- 结果
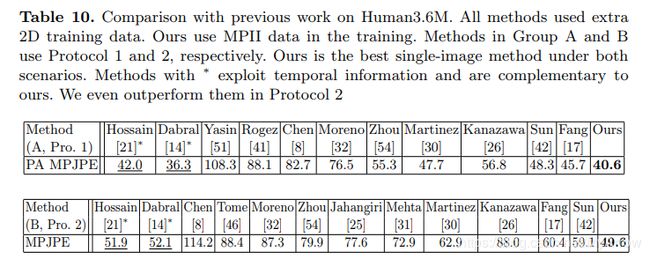
4.6 Unsupervised Geometry-Aware Representation for 3D Human Pose Estimation (ECCV’18)
- 原理
- 从多个角度拍摄的同一个人的图像用于学习捕捉人体三维几何结构的潜在表示
- 学习此表示不需要任何二维或三维姿势标注,相反,编码器-解码器被训练来从从不同的视点捕获的图像预测从一个视点看到的图像;然后可以学习以有监督的方式从该潜在表示中预测3D姿势
- 由于潜在的表示已经捕捉到了三维几何体,因此映射到三维姿态的过程要简单得多,并且使用的样本比依赖多视图监视的现有方法要少得多
- 模型

- 结果
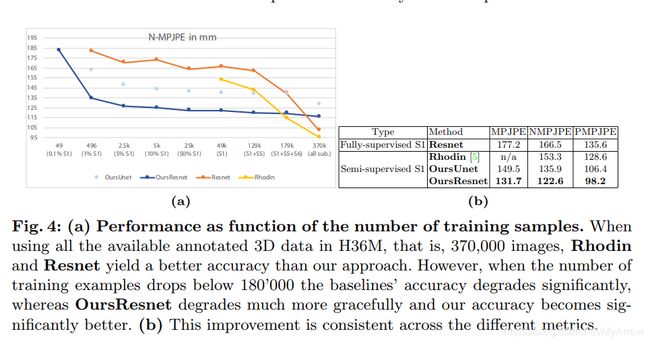
5. 基于RGB-D的3D姿态估计 (3D Pose Estimation)
参考:
- https://nanonets.com/blog/human-pose-estimation-2d-guide/#deeppose
- https://nanonets.com/blog/human-pose-estimation-3d-guide/
- Awesome Human Pose Estimation-Full Links
- RGB-D-based human motion recognition with deep learning: A survey
- Adversarial posenet: A structure aware convolutional network for human pose estimation
- PoseNet: Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image (ICCV 2019).
- Download Human3.6M parsed data [data]
- Download MPII parsed data [images][annotations]
- Download MuCo parsed and composited data [data]
- Download MuPoTS parsed parsed data [images][annotations]
- All annotation files follow MS COCO format.
- If you want to add your own dataset, you have to convert it to MS COCO format.