压缩原因
1.文件太大,节省空间
2.提高数据在网络上传输的效率
3.对数据起到保护作用---加密
文件压缩类型
无损压缩:源文件被压缩之后,可以通过解压缩还原成与源文件相同的格式
有损压缩:源文件被压缩之后,解压缩无法还原成与源文件相同,但识别其内容没有影响,多用于语音,图片,视频压缩
基于Huffman树的压缩如何实现
首先先对文件进行LZ77压缩(也就是基于字符层面的压缩),然后在LZ77压缩文件的基础上再进行Huffman压缩
第一,什么是LZ77压缩
LZ77是基于字节的通用压缩算法,它的原理就是将源文件中的重复字节(即在前文中出现的重复字节)使用(长度,距离)对来表示,例如
mnoabczxyuvwabc123456abczxydefgh
压缩之后:mnoabczxyuvm93123456186defgh。
为了记录压缩之后的数据到底是文件数据还是(长度距离)对,而又加了一个信息文件
信息文件(比特位):0代表数据,1代表的是长度距离对
LZ77压缩原理
1.构建一个64k连续空间窗口(文件数据读取的缓冲区),窗口中分为查找缓冲区和先行缓冲区,先行缓冲区中数据压缩时,通过哈希表找出最长匹配串即距离,如果没有在前文中找到重复则把原字节放入压缩文件中,如果找到重复,则把长度距离对放入压缩文件中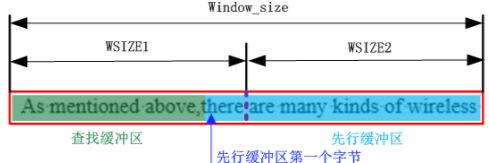
2.构建哈希表,由于压缩时写长度距离对时有三个字节,所以低于三字节的数据不压缩,所以哈希表构建需要256256256,即2^24个空间个数,也就是32M,但是由于空间太大,以及随着压缩不断进行,哈希表中内容不断更新,维护起来特别耗时,最终给哈希表的个数为2^15个空间,在这种“狼多肉少”的情况下,为了避免哈希冲突,采用了64k的连续空间来维护哈希表,右窗head空间全置为0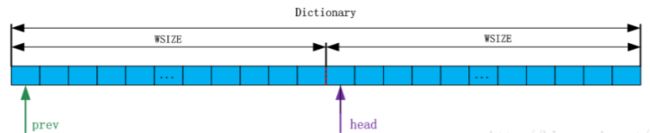
3.通过读取文件以三个字节为一组填入哈希表中,如果遇到单组字节,直接填入,如果遇到重复字节,把右窗中的数值填入左窗,即

4.为了让解压缩的时候可以识别到底是数据文件还是长度距离对,而又加了一个信息文件
信息文件(比特位):0代表数据,1代表的是长度距离对 对每一个字节压缩的时候,需要同时判断压缩字节是否为长度距离对,按比特位压入
第二,什么是Huffman树
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
例如:给定权值为1(A),3(B),5(C),7(D)四个节点,构建Huffman树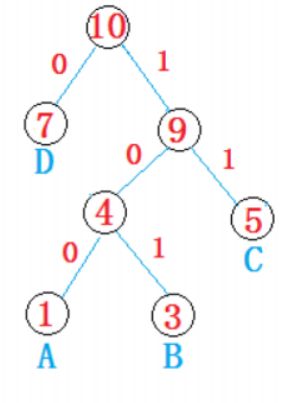
Huffman压缩原理--基于Huffman编码
以字符串中每个字符出现的次数为权值构建Huffman树
从根节点开始,左分支为0,右分支为1,如上图
所有权值节点都在叶子节点位置,遍历每条到叶子节点的路径获取字符的编码
举个栗子:ABBBCCCCCDDDDDDD
Huffman编码:
A:100
B:101
C:11
D:0原理就是这么简单,一个字符占一个字节,现在用二进制编码代替之后,一个字符只占三位,也就是说一个字节可以表示两三个字符,所以说一次压缩,就会节省很多字节,也就起到了压缩的作用。
Huffman压缩中最重要的是三点
创建Huffman树:
1 先用权值创建n棵只有根节点的二叉树森林【意思是先创建n个节点】
2 选取根节点权值最小的二叉树构建新的二叉树【建小堆,新二叉树根节点权值为左右子树的根节点权值之和】【用到了priority_queue优先级队列】
3 删除使用的两棵根节点权值较小的二叉树
4 将新创建的二叉树添加到二叉树森林中
接下来2-4循环继续,直到二叉树森林中只有一棵二叉树则Huffman树创建成文件压缩过程:
1读取源文件,读取源文件中每个字符出现的次数
2 以每个字符出现的次数作为权值,创建huffman树:小堆--优先级队列
3 通过huffman树找每个字符对应的编码
4 用每个字符的新编码重新对源文件进行改写【翻译的过程】文件解压缩的过程:
1 从压缩文件中获取源文件的后缀
2 从压缩文件中获取字符次数的总行数
3 获取每个字符出现的次数
4 重建huffman树
5 解压压缩数据
a. 从压缩文件中读取一个字节的获取压缩数据ch
b. 从根节点开始,按照ch的8个比特位信息从高到低遍历huffman树:该比特位是0,取当前节点的左孩子,否则取右孩子,直到遍历到叶子节点位置,该字符就被解析成功,将解压出的字符写入文件,如果在遍历huffman过程中,8个比特位已经比较完毕还没有到达叶子节点,从a开始执行
c. 重复以上过程,直到所有的数据解析完毕。第三,对LZ77和Huffman压缩进行整合
文件压缩和解压缩过程:LZ77压缩-->Huffman压缩(LZ77基础上)-->Huffman解压缩-->LZ77解压缩
1.整合过程中,会出现临时文件(LZ77压缩信息文件,LZ77压缩后的压缩文件,Huffman解压缩之后的文件),所以需要对这些文件进行删除:remove函数
2.压缩文件和解压缩过程中,LZ77和Huffman有交替过程,所以在调用函数时的传参过程需要封装
写代码当中碰到的一些主要的问题,我将这些总结起来:
LZ77过程:
编程前:
首先知识层面的欠缺,查阅了好多资料
编程时:
1.当压缩文件压缩至右窗的时候,为了防止哈希表中prev(数组)越界,需要&HASH_SIZE-1,但是一旦这样做就会出现匹配链成环的现象
解决方案:匹配次数不超过255次
2.压缩文件开头内容需要对文件后缀进行写入,在写入时,信息文件并没有填入,所以解压缩时,文件出现乱码
解决方案:解压缩时,文件指针对压缩文件头部进行读取,但不对标记信息进行读取
3.对于一个文件中,在解压缩时会中文大部分出现乱码,英文有少部分
解决方案:解压缩时,遇到距离长度对的时候,每解压缩一个字节,都需要刷新一次缓冲区,因为后面的数据中可能有此次解压的字节
Huffman过程:
1.编译的时候:
刚开始写的时候测试发现如果压缩文件中出现了中文,程序就会崩溃,最后发现是数组越界的错误,因为如果只是字符,它的范围是-128~127,程序中使用char类型为数组下标(0~127),所以字符没有问题. 但是汉字的编码是两个字节,所以可能会出现越界,
解决方法:就是将char类型强转为unsigned char,下标可表示范围为0~255.
2.解压缩的时候
有些特殊字符在处理需要注意一下,比如'\n',我的程序中Getline()函数就是读取一行字符,但是若是该字符本身就是一个'\n'呢? 这就非常的棘手了. 因为解压缩之后出现了乱码
解决方法:读取压缩文件时若读到了'\n',则说明该字符就是'\n',应该继续读取它的次数
3.运行的时候:
发现文件篇幅很长的时候,只能压缩和解压缩一部分,是因为字符长度的设定太小
解决方法:_count长度设为unsigned long long类型
测试方面:
1.对于txt文件压缩率还可以,但是对于音频和视频方面压缩率较低
2.为了压缩率,时间复杂度优点高
压缩率
| 文件类型 | 源文件大小 | 压缩后大小 | 压缩率 |
|---|---|---|---|
| txt文档 | 27.8KB | 12.5KB | 0.45 |
| 音频文件 | 29.8 MB | 31.9MB | 1.07 |
| 视频文件 | 20.7MB | 22.1MB | 1.06 |