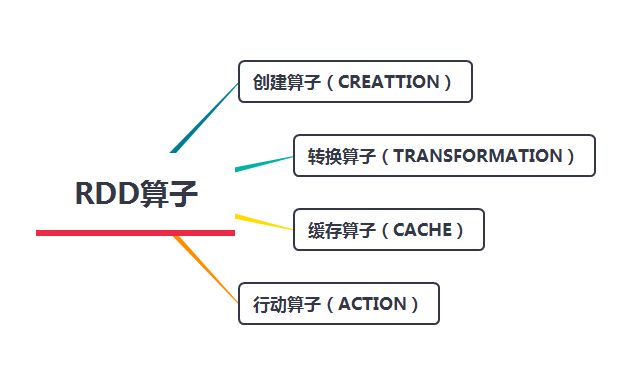
RDD算子是Spark计算框架中定义的对RDD进行操作的各种函数,从RDD算子的功能可将RDD算子分为四类,创建算子、转换算子、缓存算子和行动算子。
RDD算子
创建算子
创建RDD有两种方式:一种是将基于Scala的集合类型数据(如List或Set类型)分布到集群中生成RDD,另一种则是加载外部数据源(如本地文本文件或HDFS文件)生成RDD。上面所提到的两种方式都是通过SparkContext的接口函数提供的,前者有两种方法:makeRDD和parallelize,后者则因为其支持不同形式和不同格式的文件,有较多的函数。
基于集合类型数据创建RDD
SparkContext.makeRDD:创建RDD
# 输入参数seq为一个集合数据集,参数String序列指定了希望将该数据集产生的RDD分区希望放置的节点,
# 可以用Spark节点的主机名(hostname)描述
def makeRDD[T](seq: Seq[(T, Seq[String])])(implicit arg0: ClassTag[T]): [RDD]
# 输入参数seq为一个数据集,numSlices是分区数量,若不指定数量,
# 将使用Spark配置中的spark.default.parallelism参数所生成的defaultParallelism数值,为默认的分区数量。
def makeRDD[T](seq: Seq[T], numSlices: Int = [defaultParallelism])(implicit arg0: ClassTag[T]): [RDD]
makeRDD
示例代码:
your-spark-path/bin# ./spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
17/01/23 09:20:56 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/01/23 09:20:58 WARN spark.SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.1.150:4040
Spark context available as 'sc' (master = local[*], app id = local-1485134457902).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_111)
Type in expressions to have them evaluated.
Type :help for more information.
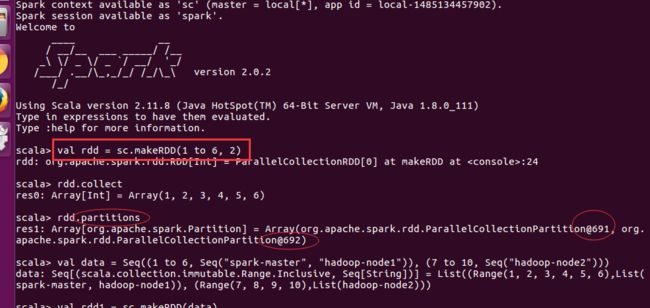
scala> val rdd = sc.makeRDD(1 to 6, 2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at :24
scala> rdd.collect
res0: Array[Int] = Array(1, 2, 3, 4, 5, 6)
scala> rdd.partitions
res1: Array[org.apache.spark.Partition] = Array(org.apache.spark.rdd.ParallelCollectionPartition@691, org.apache.spark.rdd.ParallelCollectionPartition@692)
scala> val data = Seq((1 to 6, Seq("spark-master", "hadoop-node1")), (7 to 10, Seq("hadoop-node2")))
data: Seq[(scala.collection.immutable.Range.Inclusive, Seq[String])] = List((Range(1, 2, 3, 4, 5, 6),List(spark-master, hadoop-node1)), (Range(7, 8, 9, 10),List(hadoop-node2)))
scala> val rdd1 = sc.makeRDD(data)
rdd1: org.apache.spark.rdd.RDD[scala.collection.immutable.Range.Inclusive] = ParallelCollectionRDD[1] at makeRDD at :26
scala> rdd1.collect
res2: Array[scala.collection.immutable.Range.Inclusive] = Array(Range(1, 2, 3, 4, 5, 6), Range(7, 8, 9, 10))
scala> rdd1.preferredLocations(rdd1.partitions(1))
res6: Seq[String] = List(hadoop-node2)
scala> rdd1.preferredLocations(rdd1.partitions(0))
res7: Seq[String] = List(spark-master, hadoop-node1)
SparkContext.parallelize:数据并行化生成RDD
# 将集合数据seq分布到节点上形成RDD,并返回生成的RDD。numSlices是分区数量,
# 若不指定数量,将使用Spark配置中的spark.default.parallelism参数所生成的defaultParallelism数值,为默认的分区数量。
def parallelize[T](seq: Seq[T], numSlices: Int = defaultParallelism)(implicit arg0: ClassTag[T]): RDD[T]
parallelize
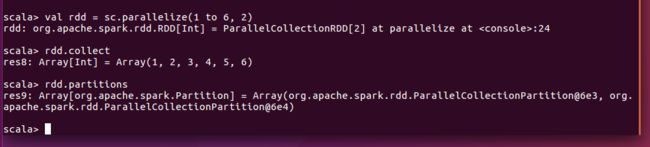
scala> val rdd = sc.parallelize(1 to 6, 2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at :24
scala> rdd.collect
res8: Array[Int] = Array(1, 2, 3, 4, 5, 6)
scala> rdd.partitions
res9: Array[org.apache.spark.Partition] = Array(org.apache.spark.rdd.ParallelCollectionPartition@6e3, org.apache.spark.rdd.ParallelCollectionPartition@6e4)
基于外部数据创建RDD
SparkContext.textFile——基于文本文件创建RDD
# 从HDFS、本地文件系统或者其他Hadoop支持的文件系统,按行读入指定路径下的文本文件,并返回生成的RDD。
# path是待读入的文本文件的路径,minPartitions是分区数量,不给定由spark配置中参数生成默认值
def textFile(path: String, minPartitions: Int = defaultMinPartitions): RDD[String]

textFile
# 若读取的数据是来自HDFS时,路径地址:"hdfs://...."
scala> val textFile = sc.textFile("file:/usr/local/spark/spark202/README.md")
textFile: org.apache.spark.rdd.RDD[String] = file:/usr/local/spark/spark202/README.md MapPartitionsRDD[6] at textFile at :24
scala> textFile.count()
res11: Long = 99
scala> textFile.first()
res12: String = # Apache Spark
SparkContext.wholeTextFiles——基于一个目录下的全部文本文件创建RDD
def wholeTextFiles(path: String, minPartitions: Int = defaultMinPartitions): RDD[(String, String)]
Read a directory of text files from HDFS, a local file system (available on all nodes), or any Hadoop-supported file system URI. Each file is read as a single record and returned in a key-value pair, where the key is the path of each file, the value is the content of each file.
基于Hadoop API从Hadoop文件数据创建RDD
详见spark官方文档

Hadoop-RDD