大数据之Kylin入门——第二章Kylin入门
1.数据准备
hive建表语句和一些测试数据:
部门表:
create external table if not exists default.dept(
deptno int,
dname string,
loc int
) row format delimited fields terminated by '\t';
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
员工表:
create external table if not exists default.emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int) row format delimited fields terminated by '\t';
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 102.创建工程
1.登陆系统

2.创建工程
填入工程名

3.导入数据
最开始我们在hive中创建了两张表并导入了数据,这里直接从hive拉取数据过来。
选择数据源Data Source

选择第二项,从列表中导入。

选择我们在hive中建立的两张表,这里并没有将数据导入,只是导入了表的元数据。

导入成功后,页面上就显示了我们刚导入的两张表。
4.创建model
这里说明下,kylin目前只支持的数仓模型是星型模型,雪花模型还不支持。
给model取名

选择事实表。其实员工表,部门表都是维度表,我这里只有两张表就以员工表作为事实表。
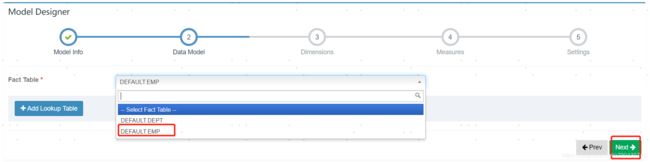
添加维度表
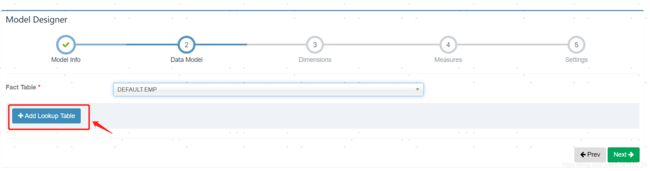
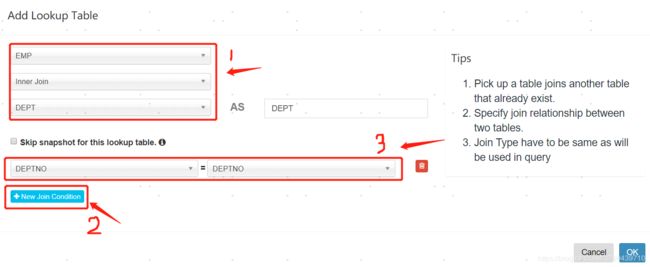
先选择事实表要关联的维度表,然后选择两张表关联的字段
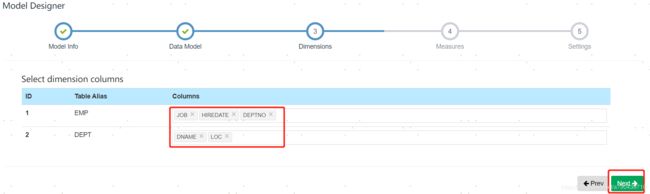
选择维度信息,维度信息也就是你最终OLAP分析是以哪些方面来计算的。
选择度量信息,度量信息也就是你从各个维度分析,最终有个指标来衡量你的分析。

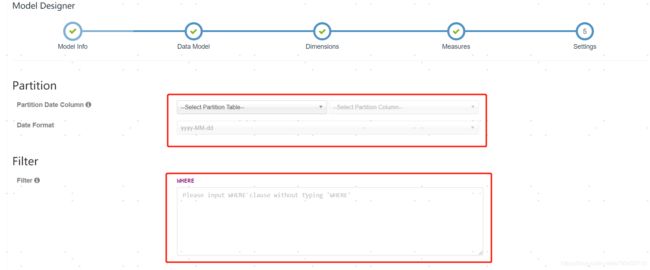
partition和where这里不填写,点击next。
这里说明下partition和where到底是干什么用的。
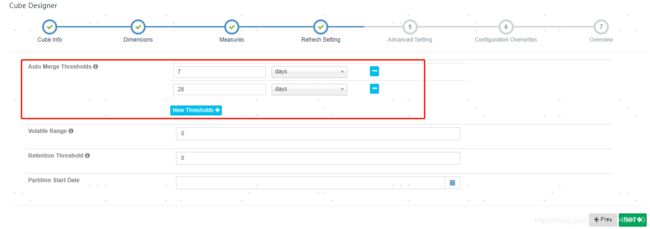
hive的表内容更新可能有增量更新和全量更新。如果是增量更新,一般都是按照日期来更新,所以partition就要选择日期字段,这样hive按照每日增量更新数据后,Kylin根据每日增量构建数据再汇总,计算一份新的数据保存起来。此外,还可以联合构建cube的设置,选择多长时间汇聚一次。cube设置位置如下图所示位置:
where是起过滤作用,从hive导入过来计算的数据可能不需要全量的数据,所以在这里加上过滤条件,过滤掉不需要的数据。
model创建完成

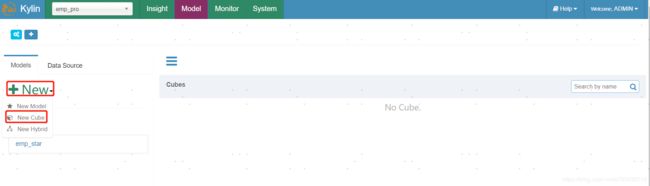
5.创建cube
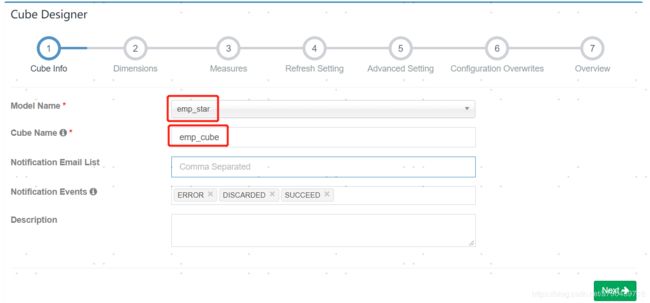
选取cube,并填写cube name,有需要可以填写邮件,cube在构建后各种状态时会给你发送邮件。
现在新增维度,刚才model设置了维度,这里构建cube的时候可以重新设定维度。

这里选择如下几项维度进行构建,并且选择normal(第五章cube优化会详细讲解normal,derived)。

现在设立度量到底计算什么指标。
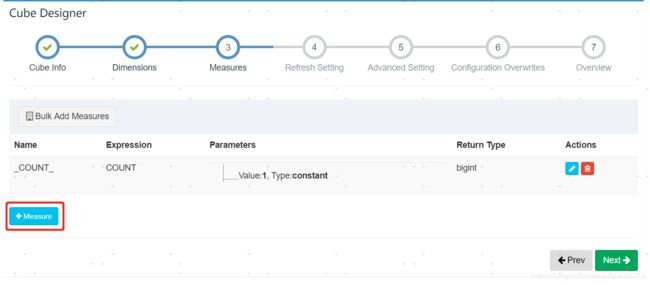
这里给你自己的度量取个名字。然后选择expression,也就是怎么计算你的度量,我这里选的是对工资求和,用的sum。param type有colume和constant,一般求count的时候才是constant。最后选择要计算的列,这里选择的是薪水sal。最后选择OK保存。
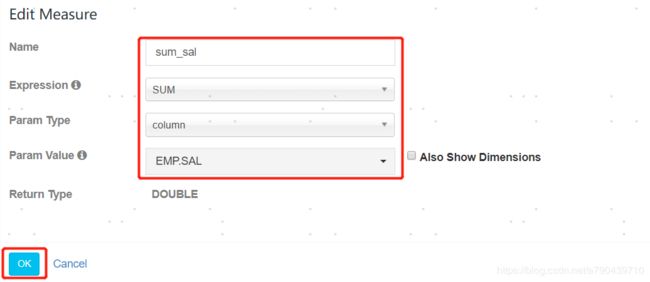
保存之后,后面的步骤4,5,6,7都直接点击next就行。第五章讲cube优化的时候会讲述这些到底是做什么的。
6.查看cube。
保存之后你可以查看我们构建cube的sql语句是什么,也可以查看我们到底构建了多少种维度。


7.构建cube。
现在我们可以开始让kylin来构建我们的cube。

我们可以查看cube构建的过程以及每个步骤的日志。

cube在执行过程中,如果报以下异常,说明你的hadoop历史服务没有打开,命令$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver启动历史服务。然后jps查看服务是否启动。然后resume从失败的地方重新开始执行cube。
org.apache.kylin.engine.mr.exception.MapReduceException: Exception: java.net.ConnectException: Call From hadoop102/192.168.1.102 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
java.net.ConnectException: Call From hadoop102/192.168.1.102 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at org.apache.kylin.engine.mr.common.MapReduceExecutable.doWork(MapReduceExecutable.java:173)
at org.apache.kylin.job.execution.AbstractExecutable.execute(AbstractExecutable.java:164)
at org.apache.kylin.job.execution.DefaultChainedExecutable.doWork(DefaultChainedExecutable.java:70)
at org.apache.kylin.job.execution.AbstractExecutable.execute(AbstractExecutable.java:164)
at org.apache.kylin.job.impl.threadpool.DefaultScheduler$JobRunner.run(DefaultScheduler.java:113)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
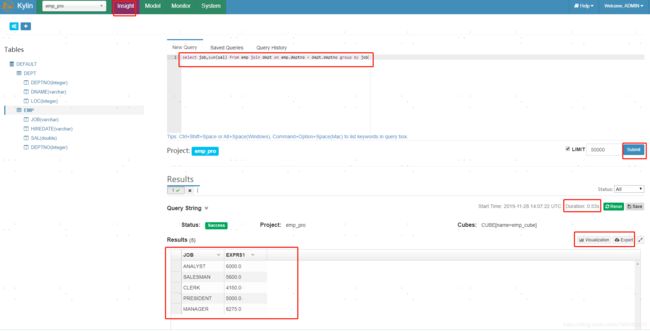
at java.lang.Thread.run(Thread.java:748)8.查询数据。
cube构建完成后,我们可以运行sql来查询结果,结果可以以图表的形式展示,也可导出最终结果。