Excel03导出优化
Excel03导出优化
文章目录
- Excel03导出优化
- 1. 现象
- 2. 目标
- 3. 原因
- 4. XLS文件解析
- 4.1. Microsoft Excel File Format(2003,BIFF8)
- 4.1.1. Workbook Globals SubStream(WGS)
- 4.1.2. Shared String Table
- 4.1.3. Worksheet SubStream
- 4.1.4. Row Blocks
- 4.1.5. 快速定位数据
- 4.2. Microsoft Compound Document File Format
- 4.2.1. Directory
- 4.2.2. Sector Allocation Table (SAT)
- 4.2.3. Master Sector Allocation Table (MSAT)
- 4.2.4. Header的结构
- 4.3. 参考文献&格式验证工具
- 5. 难点
- 6. 解决方案
- 6.1. 完全占用内存
- 6.2. 功能简化&多文件写入
- 6.3. 解决方案对比
- 7. 总结
1. 现象
业务环境中,在大数据量(3w+)下,经常出现OOM问题。
2. 目标
降低内存占用,解决OOM问题。
3. 原因
第三方导出工具jxl,在导出Excel2003版本(即xls格式)文件时,采用了将数据一次性写入硬盘的做法。在数据量较大时,大量数据滞留在内存,FGC无法回收,导致OOM。经验证,导出工具pom也存在相似的问题。
4. XLS文件解析
对xls文件进行分析后,发现其格式在设计之初,就没有考虑大数据量情况下的流式写(毕竟是2003年)。下面对xls文件格式进行介绍,这里明确一下,我们对文件格式的介绍都是基于Excel2003版本的,2003之前的不介绍。
4.1. Microsoft Excel File Format(2003,BIFF8)
Excel2003的数据结构,遵循BIFF8(Binary File Format 8)格式。本文对BIFF8的解析是文档+实践的结合,对文档的理解有可能存在片面。若出现不一致除,以文档为准,因为文档是官方的。
xls文件的内容存储在一个Workbook Stream中,而Workbook Stream由一个Workbook Globals SubStream和多个Workbook Sheet SubStream组成,其结构见下图。

Workbook Globals记录了一些全局信息,如读取数据使用的全局索引,字符串常量池等。Workbook Sheet记录一个Sheet中的数据。它们都是由多种不同的Record组成的。Record是一组字节,用来存放不同的数据,Record的通用结构见图下图。

不同的Record,其data不同,下面会详细介绍。
一个完整的Workbook Stream,其SubStream的排列顺序见下图。

4.1.1. Workbook Globals SubStream(WGS)
WGS的结构见下图。
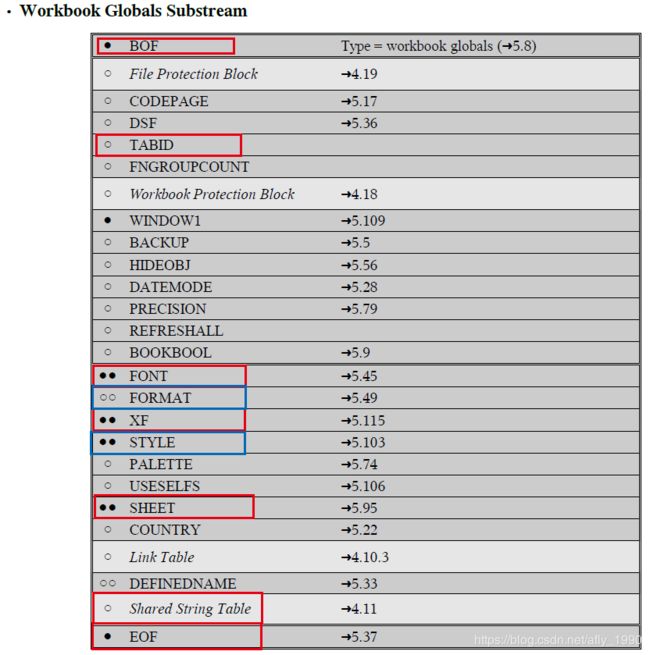
图中红框部分,是比较重要的Record;而蓝框部分,因为有系统或导出工具的默认值,所以没有仔细研究,下面一一介绍。
- BOF: 代表一个SubStream的开始,在此Record中,有字段记录了SubStream的类型。
- TABID: Workbook Document中的Sheet的下标集合。
- FONT: Workbook Document中的所有字体的集合,一个Font Record代表一种字体,所有Font Record集中出现在一处。
- XF: 记录了单元格、行或者列的格式信息,包括指向Font的索引,指向Format的索引,以及其它的一些单元格信息(是否隐藏,是否有边框等)。
- SHEET: 记录Sheet的一些通用信息,一个Sheet对应一个。包括Sheet在文件中的起始Offset、Sheet名、Sheet类型(普通的Sheet,Chart或者Visual Basic Module)、是否隐藏等。
- Shared String Table: 重点,后面详细讲
- EOF: 代表一个SubStream的结束。
4.1.2. Shared String Table
Shared String Table是整个xls文档通用的字符串常量池,其它地方可以通过每个字符串在常量池中的下标引用它。它由一个SST Record、(可能存在的)多个Continue Record组成、(可以不存在的)EXTSST组成,其顺序如下图所示。

Continue Record是在SST过大时的补充,紧跟SST,图中没有画出。
SST Record的结构见下图。

前4个字节,记录了常量池中的字符串被引用的总数,其后的4字节,记录了常量池中字符串的总数(可以计算出利用率),最后是所有字符串,顺序排列,中间没有分隔符。编码是UTF8或UTF16,每个字符串的结构见下图。
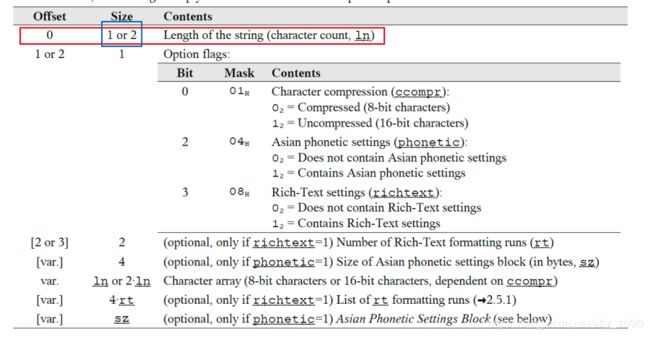
看上去比较复杂,不过Option flags可以写死为0x01(参考的导出工具jxl),其它可有可无的字段暂时都没写。
EXTSST实际上是字符串的散列表,便于读取Excel的时候进行查询,目前并没有生成,实际测试中,6w数据,打开速度也不太受影响。后面如果打开太慢,可以考虑加上。
4.1.3. Worksheet SubStream
这是一个Sheet真正被存储的SubStream,其Record结构见下图。
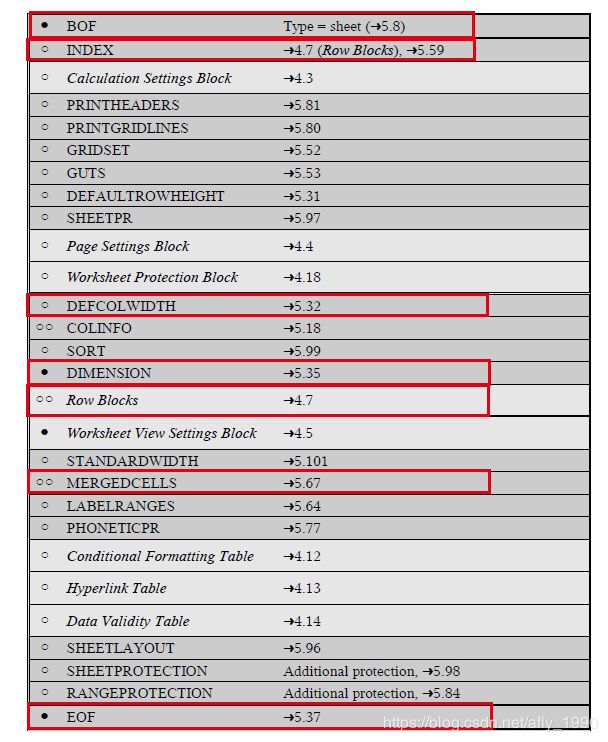
- BOF: 之前介绍过了,Record的开始
- INDEX: 是Sheet中行的索引,用于读取时的快速定位数据,本文后面会专门讲使用原理。
- DEFCOLWIDTH: 默认的列宽度。之所以把它标注出,是因为它的位置要记录在INDEX Record中。
- DIMENSION: 记录Sheet的开始行列和结束行列。
- Row Blocks: 数据真正存放的区域,后面详细讲。
- MERGEDCELLS: 记录所有的单元格合并情况,每个合并单元格都要记录开始行列号和结束行列号。
4.1.4. Row Blocks
Row Blocks是由一组Row Block组成的,每个Row Block的结构见下图。

其中,Row Record记录了一行的信息,包括行号等,结构比较复杂,不详细展示,可以看参考文献,其实很多字段可以写死。需要注意的是,一个Row Block最多包含32个Row,也就是32行数据。
Cell Blocks就是每个单元格的数据Record,下面以常用的数字Number Record和字符串LabelSST Record为例。Number Record见下图。

这个结构比较简单,顺序记录了行号、列号、XF Record(单元格格式)的下标,number的值。LabelSST Record见下图。

这个结构与Number Record很相似,只是记录值的地方变成了SST中字符串的下标。
DBCELL出现在每一个Row Block的最后,记录了每个Row Block中的相对位置,包括第一个Row相对于DBCELL的位置,每一行的第一个Cell Block相对于上一行的第一个Cell Block的位置。一个DBCELL的用法见下图。
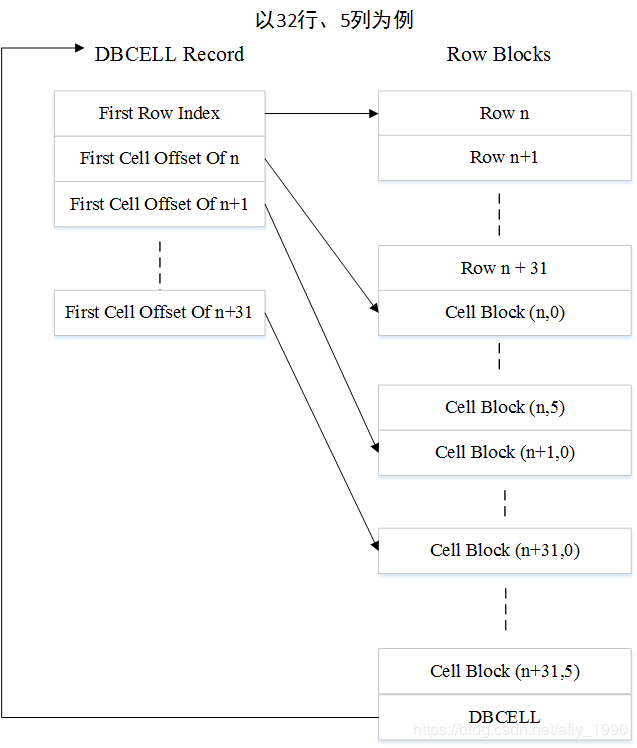
通过图可以看出,DBCELL可以快速定位Row Block中的数据,它与Index Record的作用密切相关,4.1.5会详细介绍。
4.1.5. 快速定位数据
在读取XLS文件的内容时,通过Index Record与DBCELL Record,可以快速定位行|列|单元格所在的字节Offset,其原理见下图。
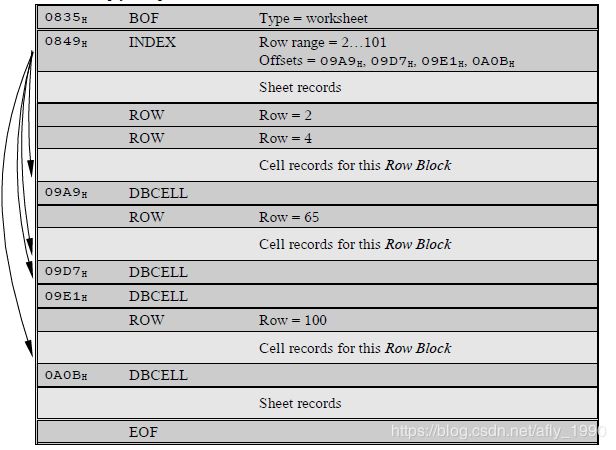
总结步骤如下:
- Index根据每个DBCELL的位置,定位到每个Row Block
- 再根据每个DBCELL中的数据,定位到每个Row Block的开始行
- 最后,根据每个DBCELL中的数据,定位到每一行开始的单元格。
4.2. Microsoft Compound Document File Format
一个xls文件,并不是一个简单的BIFF8文件,而是在BIFF8外层有一种叫做“复合二进制文档”的结构。实际上,这并不是xls的专有格式。根据资料,Office2003的所有文档(word、ppt)在最外层都使用这种结构。这种结构类似于Windows的文件系统(没错,它本身也是微软给出的),其目的就是使得一个文档能存储多个文件(比如除了Excel外,还有引用的图片、内嵌字体文件等)。
这种文档的结构见下图。
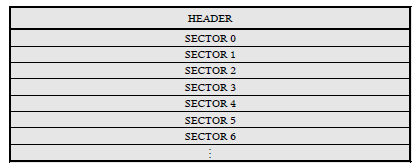
每个Sector是一个512字节的数据块(所以所有的Office2003的文档,其大小都是512的整数倍)。Header是一个特殊的Sector,记录了整个文档的一些信息。除了Header之外,其它的Sector分为三类:Directory、SAT、MSAT。
4.2.1. Directory
整个的文档组织结构是一个树形的,而Directory就是树的节点,代表一个文件或文件夹。
Directory是顺序存储在文档中的,一个Directory占128字节,一个sector可以存放4个Directory。代表文件的Directory,会记录文件开始于第几个Sector。以及文件占了几个Sector。需要注意的是,这些Sector并不要求是连续的,其顺序关系依靠SAT来记录。Directory的结构不详细展开,因为对于一个xls文件来说,可以只有两个Directory:Root Entry和Workbook Document。Workbool Document就是BIFF8文档,是Root Entry的孩子。
4.2.2. Sector Allocation Table (SAT)
SAT从下标0开始,每4个字节记录一个Sector的类型,或者下一个Sector的下标。可能的类型有:
- Free Sec: -1,这个Sector无效,不是文档的任何一部分。
- End Of Chain Sec: -2,这个Sector是一个文档的末尾。
- SAT Sec: -3,这个Sector是SAT的一部分。
- MSAT Sec: -4,这个Sector是MSAT的一部分。
从一个Directory得知文档的起始Sector后,根据SAT一路查找,直到End Of Chain Sector,就可以得到文档的完整内容。举例说明:

如图所示,假设Directory中记录的起始Sector是2,那么文档的Sector顺序就是[0,2,3,-2];起始Sector是10的话,那么就是[10, 6, 7, 8, 9, -2]。
4.2.3. Master Sector Allocation Table (MSAT)
MSAT中,记录的是SAT的Sector下标。MSAT的前109个,记录在Header中,若SAT的大小超过109个Sector,则使用单独的Sector充当MSAT。MSAT的具体结构见参考文献,这里不再介绍。
4.2.4. Header的结构
Header的结构如图所示。

从图中可以看到,Header中记录了第一个Directory-Sector,第一个MSAT-Sector,第一个SAT-Sector的下标。这样在读取Header后,就可以顺利的解析文档格式,找到所需的文件(如xls的Workbook Document)。
4.3. 参考文献&格式验证工具
复合文档结构、Biff8格式、BIFF8格式查看器&源码(C#),这里下载,提取码:j8gh
5. 难点
由第4部分,尤其是SST、Index、DBCELL的设计,可以看出,某些Record的字段,依赖于后续Record 的字段的绝对偏移量,这导致很难通过流式的写入一个文件来生成xls。
6. 解决方案
针对难点,我认为有两种方法。
6.1. 完全占用内存
将所有数据维护在内存中,在结构稳定后,统一写入XLS文件。我想jxl和poi就是采用的这种方案。
6.2. 功能简化&多文件写入
把高级功能的Record固定写死;把数据写入多个不同的文件中,如下图所示。
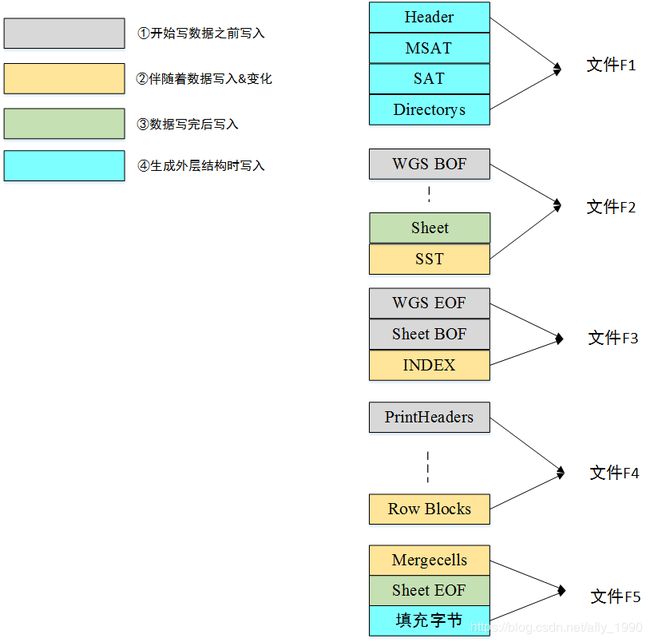
图中用四种不同的颜色代表数据被写入的时段,①②③④的写入遵循严格的实现顺序。可以看到,我们将一个完整的xls文件写入了5个子文件,分割的原则有两个:
- 外层二进制结构,BIFF8,同一个子文件不会同时又这两部分数据(填充字段除外)。这是因为生成BIFF8的过程和生成外层二进制结构的过程是独立的,便于以后其它Office03文档的生成。
- 伴随着数据增长而变化的部分(如SST、INDEX、Row Blocks),几乎都出现在子文件的尾部,这是为了便于扩展它们,也是拆分子文件的核心作用。只有Mergecells是例外,这是因为Mergecells后面的数据都是固定字节,不用计算偏移量,所以没有拆分的必要。
可以看到,子文件几乎都可以按照时序完美的写入,唯一的例外出现在文件F2,Sheet中的某些字段,需要在数据写完之后填充。这要求文件F2有可以回退写的能力。在Java代码中,使用了RandomAccessFile的seek功能,在文件的指定位置处写入数据。
6.3. 解决方案对比
| 方案一 | 方案二 | |
|---|---|---|
| 优点 | 高级功能支持(全局信息随时获得);生成速度快 | 实现流式写,内存占用小 |
| 缺点 | 内存占用太大 | 高级功能难支持(要频繁读写文件,且随机读写多);速度慢(文件读写多,子文件合并等) |
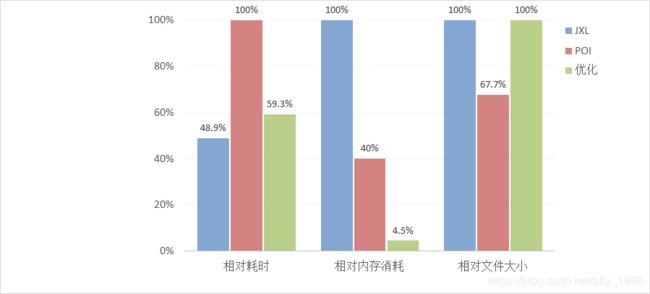
如上图所示,方案二可以很好的解决内存占用的问题,经目前的简单测试,一个6w数据的xls,优化后的峰值内存在9m左右,而JXL在200m左右,POI在80m左右。
但方案二的缺点也很明显。高级功能的扩展困难,不过这个问题,因为我们的导出没用到什么高级功能;速度慢,这是因为最后需要把所有子文件合并在一起,我想这可能也是jxl和poi没有使用这种方案的原因。
但有趣的是,针对我们的业务需求,其实并不需要把子文件合并在一起。 因为我们最终是要把数据上传到CDN(或者直接返回给用户,一样),所以只要 封装一个InputStream,按照子文件的顺序,依次将内容读取出来,并在每一个子文件读完后,删除它,就可以了。在数据流到达CDN或者客户端之后,自然就是一个完整的xls文件了。这个InputStream已经封装好了,可以查看导出代码中的类WriteAndDeleteInputStream。
7. 总结
本文档适合想要了解Excel2003,或者Office2003文档结构的同学阅读。写的可能比较零散(因为内容实在太多了),有任何问题欢迎直接联系我讨论[email protected]。另外,参考文献和工具,大家可能直接点击无法下载,也可以联系我获取,或者后续我会上传到某个页面。