Python3数据分析——Pandas快速入门基础
目录
一、Pandas基础
二、Series数据结构(一维数据)
三、DataFrame数据结构(二维数据)
四、Panel数据结构(三维数据)
一、Pandas基础
Pandas的名称来自于面板数据(panel data)和Python数据分析(data analysis)。
Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Pandas特点:
- 一个强大的分析和操作大型结构化数据集所需的工具集
- 基础是NumPy,提供了高性能矩阵的运算
- 提供了大量能够快速便捷地处理数据的函数和方法
- 应用于数据挖掘,数据分析
- 提供数据清洗功能
Pandas的数据结构:
import pandas as pd
Pandas有两个最主要也是最重要的数据结构: Series 和 DataFrame
Pandas中使用频率较低的一种数据结构:Panel(Pandas 决定在未来的版本中将 Panel 移除,转而使用 MultiIndex DataFrame 来表示多维数据结构)
Pandas的对齐运算:
是数据清洗的重要过程,可以按索引对齐进行运算,如果没对齐的位置则补NaN,最后也可以填充NaN
二、Series数据结构(一维数据)
1、简要介绍:
(1)Series是一种类似于一维数组的对象,由一组数据(各种NumPy数据类型)以及一组与之对应的索引(数据标签)组成。
(2)类似一维数组的对象,由数据和索引组成(索引(index)在左,数据(values)在右,索引是自动创建的)
(3)Series 是 Pandas 中最基本的一维数据形式。其可以储存整数、浮点数、字符串等形式的数据。Series 的新建方法如下:s = pandas.Series(data, index=index);其中,data 可以是字典、numpy 里的 ndarray 对象等。index 是数据索引,索引是 pandas 数据结构中的一大特性,它主要的功能是帮助我们更快速地定位数据。
2、通过字典(dict)构建Series

数据值是 10, 20, 30,索引为 a, b, c 。
我们也可以直接通过 index= 参数来设置新的索引,如下
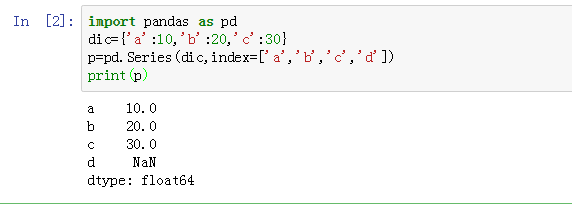
pandas 会自动匹配人为设定的索引值和字典转换过来的索引值。而当索引无对应值时,会显示为 NaN 缺失值。
3、通过ndarray构建Series
ndarray 是著名数值计算包 numpy 中的多维数组。我们也可以将 ndarray 直接转换为 Series。
(1)指定了 index 的值

(2)非人为指定索引值时,Pandas 会默认从 0 开始设置索引值。

(3)从一维数据 Series 中返回某一个值时,可以直接通过索引完成

(4)对Series 直接进行运算

(5)Series的对齐运算
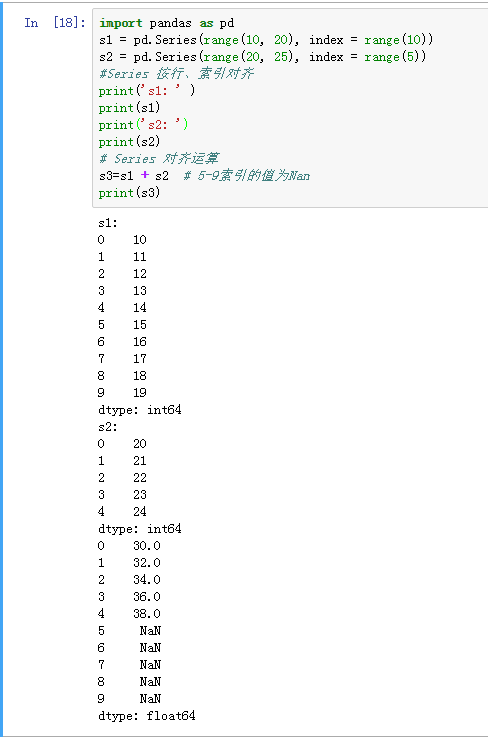
注意:填充未对齐的数据进行运算
使用add, sub, div, mul的同时,通过fill_value指定填充值,未对齐的数据将和填充值做运算
示例代码:print(s1)
print(s2)
s1.add(s2, fill_value = -1)
三、DataFrame数据结构(二维数据)
1、简要介绍
(1)DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同类型的值。DataFrame既有行索引也有列索引,它可以被看做是由Series组成的字典(共用同一个索引),数据是以二维结构存放的。
(2)特点:类似多维数组/表格数据 (如,excel, R中的data.frame);每列数据可以是不同的类型;索引包括列索引和行索引
(3)DataFrame 可以用于储存多种类型的输入:
- 一维数组、列表、字典或者 Series 字典。
- 二维 numpy.ndarray。
- 结构化的 ndarray。
- 一个 Series。
- 另一个 DataFrame。
2、通过字典(dict)构建DataFrame
(1)通过Series的字典构建DataFrame

行索引为 a, b, c, d ,而列索引为 one, two
(2)通过ndarray或list的字典构建DataFrame

3、通过带字典的列表构建DataFrame

4、DataFrame.from_ 方法
pandas的 DataFrame 下面还有 4 个以 from_ 开头的方法,这也可以用来创建 Dataframe。

5、DataFrame中列的选择、删除和添加
在一维数据结构Series中,我们用 df['标签']来选择行。在二维数据DataFrame中,df['标签']表示选择列。
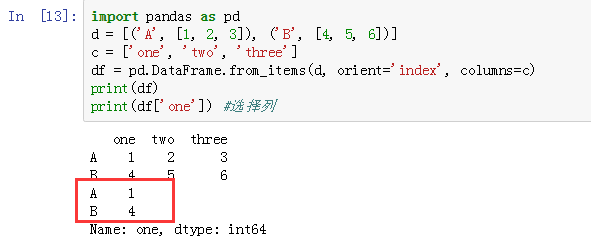
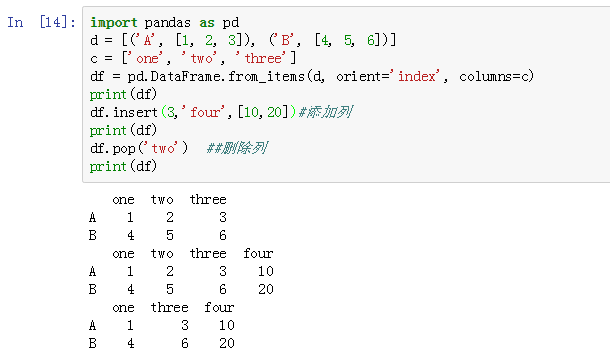
6、DataFrame的对齐运算

四、Panel数据结构(三维数据)
1、简要介绍
(1)Panel是Pandas中使用频率较低的一种数据结构,但它是三维数据的重要容器。
(2)Panel data又称面板数据,它是计量经济学中派生出来的一个概念。在计量经济学中,数据大致可分为三类:截面数据,时间序列数据,面板数据。而面板数据即是截面数据与时间序列数据综合起来的一种数据类型。
简单来讲,截面数据指在某一时间点收集的不同对象的数据。而时间序列数据是指同一对象在不同时间点所对应的数据集合。
这里引用一个城市和 GDP 关系的示例来解释上面的三个概念:
截面数据:
- 例如城市:北京、上海、重庆、天津在某一年的 GDP 分别为10、11、9、8(单位亿元)。
时间序列数据:
- 例如:2000、2001、2002、2003、2004 各年的北京市 GDP 分别为8、9、10、11、12(单位亿元)。
面板数据:
- 2000、2001、2002、2003、2004 各年中国所有直辖市的 GDP 分别为(单位亿元):北京市分别为 8、9、10、11、12;上海市分别为 9、10、11、12、13;天津市分别为 5、6、7、8、9;重庆市分别为 7、8、9、10、11。
(3)Panel 构成
在 Pandas 中,Panel 主要由三个要素构成:
- items: 每个项目(item)对应于内部包含的 DataFrame。
- major_axis: 每个 DataFrame 的索引(行)。
- minor_axis: 每个 DataFrame 的索引列。
简言之,在 Pandas 中,一个 Panel由多个 DataFrame 组成。
2、生成一个Panel
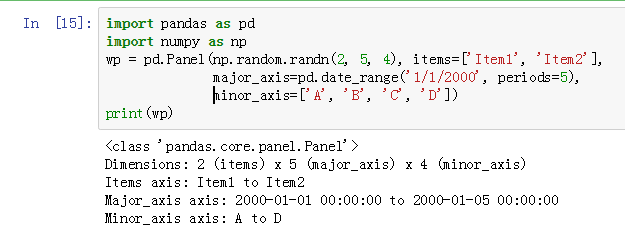
可以看到,wp 由 2 个项目、5个主要轴和4个次要轴组成。其中,主要轴由2000-01-01 到2000-01-05这5天组成的时间序列,次轴从A到D。
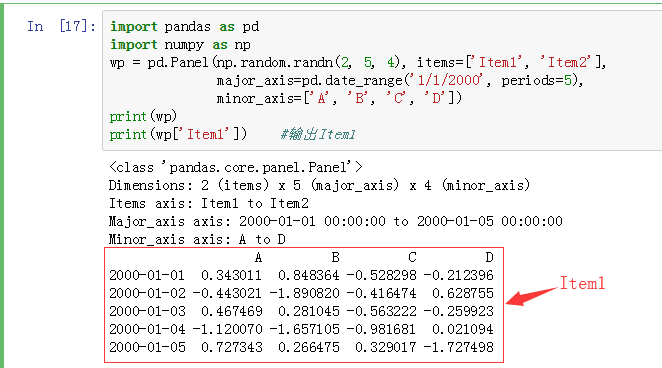
3、由于 Panel 在 Pandas 中的使用频率远低于 Series 和 DataFrame,所以 Pandas 决定在未来的版本中将 Panel 移除,转而使用 MultiIndex DataFrame 来表示多维数据结构。
补充:Pandas统计计算和描述
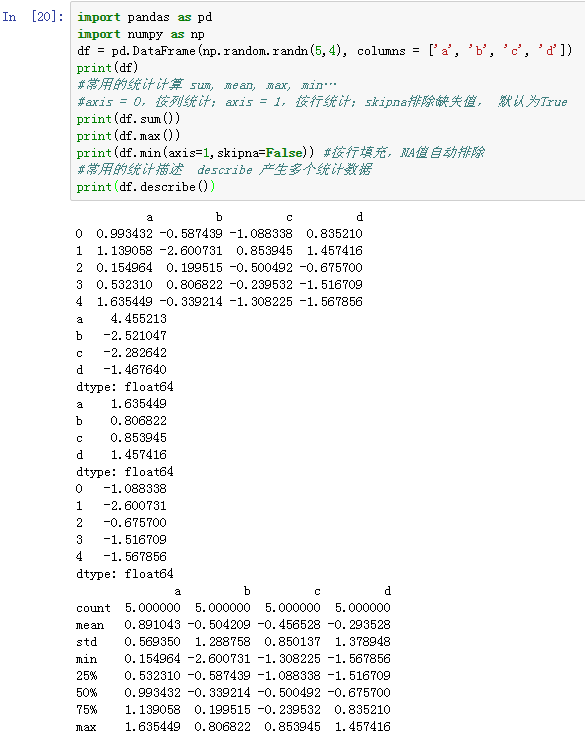
#描述和汇总的方法
count 非Nan数量
describe 针对个列汇总统计
min和max 最大最小值
argmin、argmax 计算最大值或最小值对应的索引位置
quantile 计算样本的分位数(0-1)
mean 均值
median 中位数
mad 平均绝对离差
var 样本方差
std 样本的标准差
skew 样本值的偏度
kurt 样本值的峰度
cumsum样本值的累计和
注:
1、Pandas官网
2、Pandas官方文档
3、Pandas详细学习教程