详解分布式寻址算法
引言
在分布式系统中,对数据的准确定位以及整个系统的结构具有很高的要求。下现代分布式寻址算法中,主要以下面三种算法为代表:
- hash 算法(大量缓存重建)
- 一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡)
- redis cluster 的 hash slot 算法(也叫hash槽)
hash算法比较适合固定分区或者分布式节点的集群架构。一致性hash算法比较适合需要动态扩容的分布式架构以及一些动态负载均衡的分布式中间件和RPC中间件。hash slot是Redis对hash算法的一种实现。
hash算法
将不同的请求hash后碰撞到数目固定的“hash桶”里。如有3个服务器,当不同请求过来时,通过hash碰撞指定到所对应的服务器处理该请求。
s h a r d = h a s h ( i p ) % ( N U M S _ H A N D L E R ) shard=hash(ip)\%( NUMS\_ HANDLER) shard=hash(ip)%(NUMS_HANDLER)
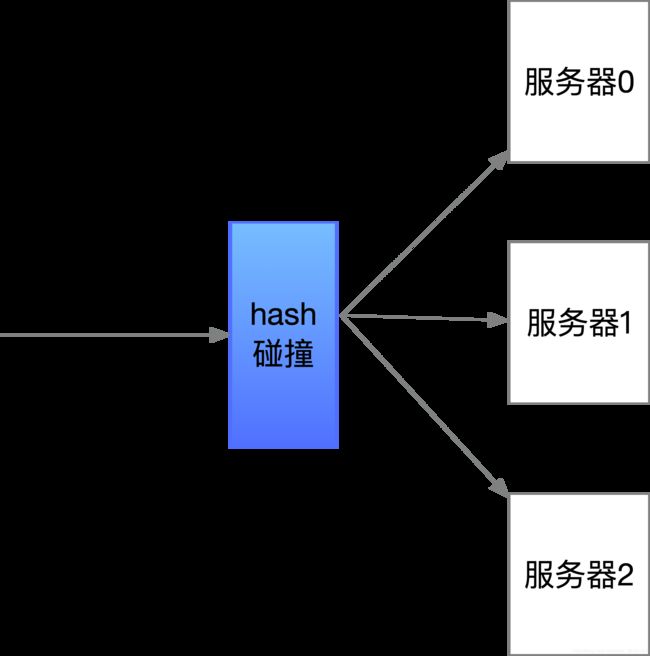
当系统需要对服务器进行扩容时,那么整个已经保存到服务器中的数据都得重新进行hash碰撞,当系统具有海量数据时将会是场灾难。
一致性hash
它就是为了能动态扩容,减少扩容时带来的大量数据迁移。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:
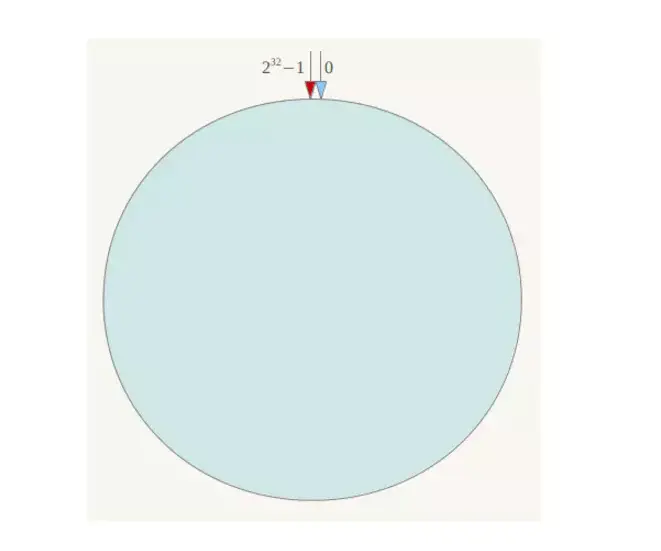
s h a r d = h a s h ( i p ) % 2 32 shard=hash(ip)\%2^{32} shard=hash(ip)%232
在集群服务器确定以后,将各个服务器使用Hash函数进行一个哈希计算,哈希计算可以选择服务器的ip地址或者主机名等关键字进行哈希,这样就完成了节点在hash环上的位置分配,假设集群有四台服务器,最终效果如下:
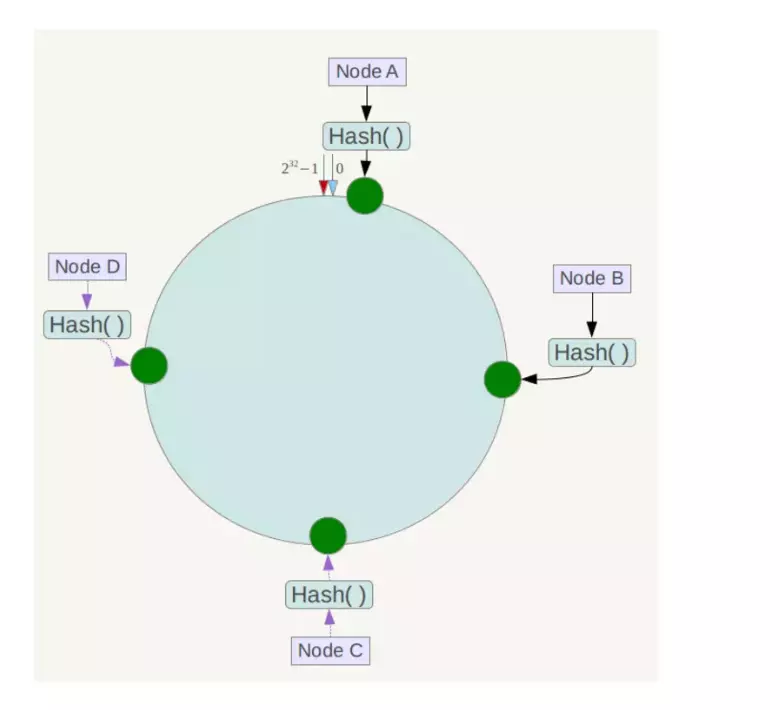
接下来,每台服务器在hash环上的位置分配完成后,在客户端对缓存key进行同样函数的hash运算,得出hash值,同样得到环上的一个位置,从这个位置顺时针找到最近的一个服务器节点,比如遍历所有节点位置和key位置差值取最小值,这样就完成了路由。
当我们需要对系统扩容时,我们依然需要进行数据的迁移,但是只是部分的,只需要迁移1-2节点之间的数据即可。相对hash取模,一致性hash算法减少了扩容带来的数据迁移量太大的问题。
一致性hash算法的缺陷是它无法控制节点分布的均匀性,因为hash的结果并不一定均匀分布在环上对称的位置,极端的情况,举个例子,现在有A、B、C三个服务器节点,hash的结果紧挨在一起,那么根据一致性hash,一定是极少量的key会访问到从0点开始顺时针数到的第二、三个节点,绝大部分key都会访问到顺时针数到的第一个节点。如下图:
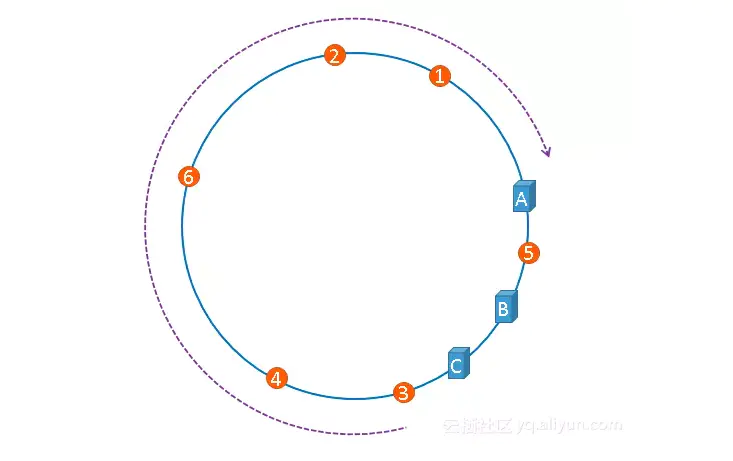
这就造成了大量的请求都交给了A和C服务器,而B服务器请求量很少。这就造成了负载不均衡的情况。
解决方法:
添加虚拟节点。具体操作就是将一台服务器加上编号尾缀进行哈希,每台服务器就会有多个结果,简单来说就是将一台服务器映射成不同的多个hash值。

hash slot
先来看一下hash slot的基本模型:
记录和物理机之间引入了虚拟桶层,记录通过hash函数映射到虚拟桶,记录和虚拟桶是多对一的关系;第二层是虚拟桶和物理机之间的映射,同样也是多对一的关系,即一个物理机对应多个虚拟桶,这个层关系是通过内存表实现的。对照抽象模型章节,key-partition是通过hash函数实现的,partition-machine是通过内存表来实现的。
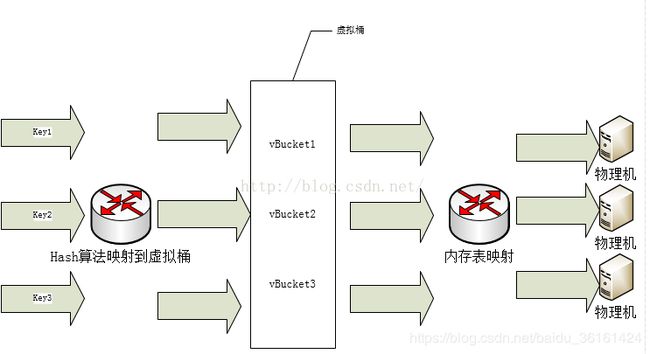
虚拟桶层采用预设固定数量, 根据系统扩容上限,可根据实现需要预先定义好即可。
虚拟桶对实际节点
举个例子,项目刚开始只有两个服务器,使用时配置节点映射:
Redis Server1对应桶的编号为0到500。
Redis Server2对应桶的编号为500到1024。
缓存数据量增长后需要增加新节点,在加之前需要重新分配节点对应虚拟桶的编号。 比如增加server3并配置对应桶的编号400到600,这时对于key映射虚拟桶层完全无影响。 实际上mod 400到600的真实数据还在另外两台节点上,请求过来后还会发生无法命中的影响。这就要求在增加新节点前,需要在后台把另外二台的400到600编号数据拷贝到新节点上面,完成后再添加配置到映射上面。 因为新来请求会命中到新节点,所以另外2台的400到600编号数据就无用了,需要进行删除。这种做法就能最大限度(100%)的保证动态扩容后,对缓存系统无影响,具体实现细节后续还需深入进行研究。
在redis集群的设计中也是采用的这个思路。
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:
s h a r d = C R C 16 ( k e y ) % 16384 。 shard=CRC16(key) \% 16384。 shard=CRC16(key)%16384。
我们假设现在有3个节点已经组成了集群,分别是:A, B, C 三个节点,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么,采用哈希槽 (hash slot)的方式来分配16384个slot 的话,它们三个节点分别承担的slot 区间是:
节点A覆盖0-5460;
节点B覆盖5461-10922;
节点C覆盖10923-16383.
如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。比如可以像如下操作:
节点A覆盖1365-5460
节点B覆盖6827-10922
节点C覆盖12288-16383
节点D覆盖0-1364,5461-6826,10923-12287
如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线。
参考文献
1.一致性hash算法
2. hash slot(虚拟桶)