Hadoop单机安装详细步骤
环境准备
安装Java
过程简单,这里省略具体安装步骤。安装后确认相应版本的Java已安装,这里选择1.7。
java -version
创建Hadoop账号
为Hadoop创建一个专门的账号是很好的实践:
sudo adduser hadoop
sudo passwd hadoop
授予 Hadoop root权限
为了测试,图方便,这里给Hadoop root权限,生产环境不建议这样做。
使用root权限编辑/etc/sudoers:
sudo vim /etc/sudoers末尾添加一行:
hadoop ALL=(ALL) ALL
切换到Hadoop账号:
su hadoop配置SSH无密码登录
首先生成公私密钥对、
ssh-keygen -t rsa指定key pair的存放位置,回车默认存放于/home/hadoop/.ssh/id_rsa
输入passphrase,这里直接回车,为空,确保无密码可登陆。
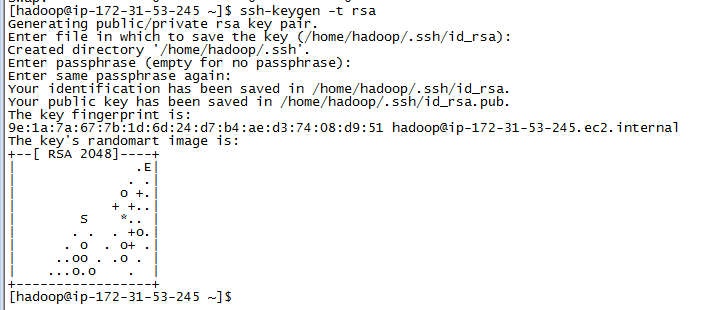
拷贝生成的公钥到授权key文件(authorized_keys)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys改变key权限为拥有者可读可写(0600) :
chmod 0600 ~/.ssh/authorized_keyschomod命令参考:
chmod 600 file – owner can read and write
chmod 700 file – owner can read, write and execute
chmod 666 file – all can read and write
chmod 777 file – all can read, write and execute测试是否成功:
ssh localhost![]()
下载安装
下载Hadoop 2.6.0
cd ~
wget http://apache.claz.org/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
解压:
tar -zxvf hadoop-2.6.0.tar.gz重命名一下:
mv hadoop-2.6.0 hadoop(最好做个关联ln -s hadoop-2.6.0 hadoop)
配置环境变量
vim ~/.bashrc
export JAVA_HOME=/usr/java/jdk1.7.0_79/
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
source ~/.bashrc
配置Hadoop
配置Hadoop
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://localhost:9000value>
property>
configuration>配置HDFS
vim hdfs-site.xml<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.name.dirname>
<value>file:///home/hadoop/hadoopdata/hdfs/namenodevalue>
property>
<property>
<name>dfs.data.dirname>
<value>file:///home/hadoop/hadoopdata/hdfs/datanodevalue>
property>
configuration>配置MapReduce
vim mapred-site.xml <configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>配置YARM:
vim yarn-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>启动集群
格式化HDFS
使用之前,需要先格式化Hadoop文件系统
hdfs namenode -format启动HDFS和YARN
cd $HADOOP_HOME/sbin启动文件系统:
start-dfs.sh
启动YARN:
start-yarn.sh
查看状态
查看HDFS状态,浏览器访问: http://localhost:50070
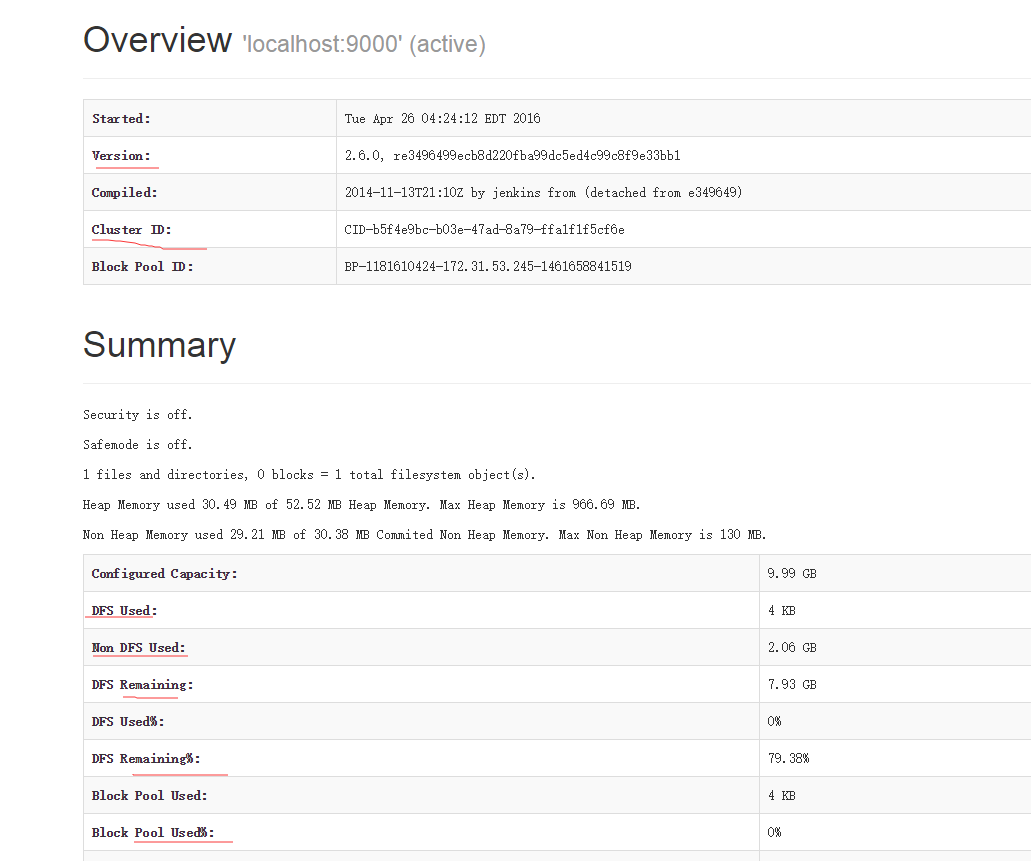
查看second namenode:
http://localhost:50090

查看DataNode:
http://localhost:50075/
http://localhost:50075/dataNodeHome.jsp

简单使用Hadoop:
使用HDFS
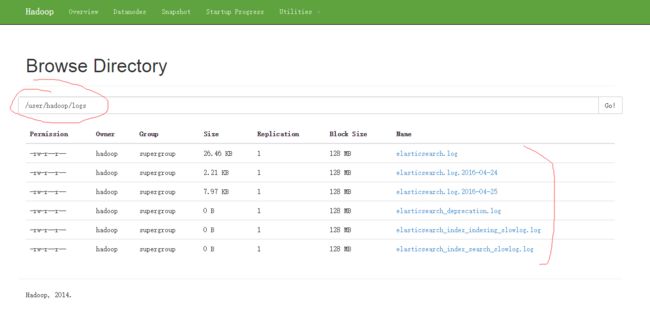
在HDFS创建两个目录:
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hadoop上传:
hdfs dfs -put /opt/modules/elasticsearch-2.3.1/logs logs从管理界面可以看到:
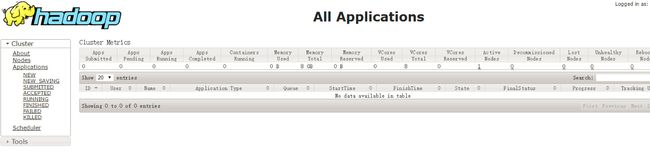
运行MapReduce作业
提交一个MapReduce作业:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep logs output 'dfs[a-z.]+'可以从YARN应用的界面查看作业情况 http://localhost:8088
(完)