MFS ——利用pacemaker+corosync+pcs实现mfsmaster的高可用
一.什么是mfsmaster的高可用
我们知道mfsmaster是调度器,是mfs最核心的地方,如果mfsmaster挂了,整个mfs架构会挂掉,对此我们要对mfsmaster进行高可用冗余操作。
MFS文件系统中,master负责各个数据存储服务器的管理,文件读写调度,文件空间回收以及恢复。多节点拷贝,是MFS的关键点,显然有极大可能存在单点故障。虽然有Metalogger,但是不能实现故障实时切换,服务要停止之后在Metalogger恢复元数据以及changelog_ml.*.mfs(服务器的变化日志文件),再次重新指定新的mfsmaster节点。
可以采用keepalived实现,但是要注意的是不仅仅是VIP的漂移,mfsmaster的工作目录都要进行漂移,这就涉及存储的共享,在这里采用pacemaker+corosync来实现故障切换)
构建思路:利用pacemaker构建高可用平台,利用iscis做共享存储,mfschunkserver做存储设备。
有人可能要问为什么不用keepalived,我想说的是就是keepalived是可以完全做的,但是keepalived不具备对服务的健康检查;整个corosync验证都是脚本编写的,再通过vrrp_script模块进行调用,利用pacemaker比较方便。
用途:
解决mfs master的单点问题,同样可以作为其他需要高可用环境的标准配置方法
二.部署mfsmaster的高可用
实验环境:
| 主机 | 服务 |
|---|---|
| server1 | mfsmaster,pacemaker,iscsi客户端 |
| server2 | mfschunkserever1,iscsi服务端 |
| server3 | mfschunkserever2 |
| server4 | mfsmaster-backup,pacemaker,iscsi客户端 |
| 物理机 | client |
本来iscsi服务端是要在另外一台虚拟机上进行部署的,这里为了方便,直接将server2作为iscsi的服务端
前提:
停掉之前mfs分布式文件系统启动的服务,并卸载客户端挂载的目录。为后续的pcs集群做准备
[root@server1 ~]# systemctl stop moosefs-master #server1端(moosefs-cgiserv服务可以不用关闭,因为moosefs-cgisev服务只是用来提供web界面的
[root@server2 ~]# systemctl stop moosefs-chunkserver
[root@server3 ~]# systemctl stop moosefs-chunkserver
物理机:
[root@foundation27 ~]# umount /mnt/mfsmeta
[root@foundation27 ~]# umount /mnt/mfs
实验步骤如下所示:
第一步:配置server4作为mfsmaster-backup端
首先要搭建基础的mfs分布式存储架构,本篇不做阐述。可以查看上篇博文。这里只需要在上篇博文的基础上添加server4作为mfsmaster-backup端即可。
server1:将server4需要的包传送给它
[root@server1 ~]# scp moosefs-master-3.0.103-1.rhsystemd.x86_64.rpm server4:

server4:
[root@server4 ~]# yum install -y moosefs-master-3.0.103-1.rhsystemd.x86_64.rpm #安装软件
[root@server4 ~]# vim /etc/hosts #编辑本地解析文件
172.25.27.1 server1 mfsmaster

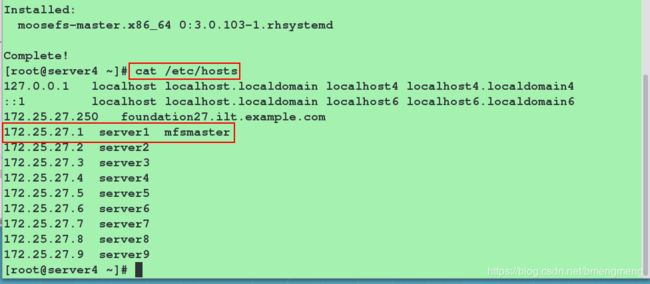
[root@server4 ~]# vim /usr/lib/systemd/system/moosefs-master.service #修改moosefs-master服务的启动脚本
8 ExecStart=/usr/sbin/mfsmaster -a #修改之后的内容
[root@server4 ~]# systemctl daemon-reload
[root@server4 ~]# systemctl start moosefs-master #检查脚本是否有错误,即查看moosefs-master服务是否能够正常启动
[root@server4 ~]# systemctl stop moosefs-master #关闭moosefs-master服务,以便后续实验的开展

第二步:配置 iscsi实现共享存储
server2
添加一块新的磁盘,用于共享
看到新添加的磁盘为/dev/vda
[root@server2 ~]# fdisk -l

对iscsi进行配置
[root@server2 ~]# yum install targetcli -y
![]()
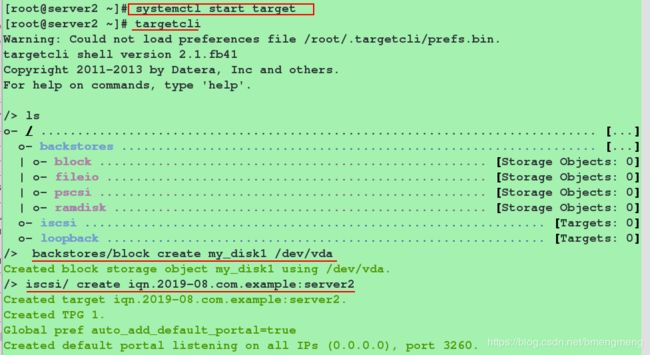
[root@server2 ~]# systemctl start target
[root@server2 ~]# targetcli
targetcli shell version 2.1.fb41
Copyright 2011-2013 by Datera, Inc and others.
For help on commands, type 'help'.
/> ls
o- / .............................................................. [...]
o- backstores ................................................... [...]
| o- block ....................................... [Storage Objects: 0]
| o- fileio ...................................... [Storage Objects: 0]
| o- pscsi ....................................... [Storage Objects: 0]
| o- ramdisk ..................................... [Storage Objects: 0]
o- iscsi ................................................. [Targets: 0]
o- loopback .............................................. [Targets: 0]
/> backstores/block create my_disk1 /dev/vda
/> iscsi/ create iqn.2019-08.com.example:server2
/> iscsi/iqn.2019-08.com.example:server2/tpg1/acls create iqn.2019-08.com.example:client
/> iscsi/iqn.2019-04.com.example:server2/tpg1/luns create /backstores/block/my_disk1

配置server1(iscsi客户端):
[root@server1 ~]# yum install iscsi-* -y #其实就一个包
[root@server1 ~]# vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2019-08.com.example:client
[root@server1 ~]# iscsiadm -m discovery -t st -p 172.25.27.2
[root@server1 ~]# iscsiadm -m node -l #或者命令"iscsiadm -m node -T qn.2019-08.com.example:server2 -p 172.25.27.2 -l"
![]()

可以查看到多了一块磁盘
[root@server1 ~]# fdisk -l
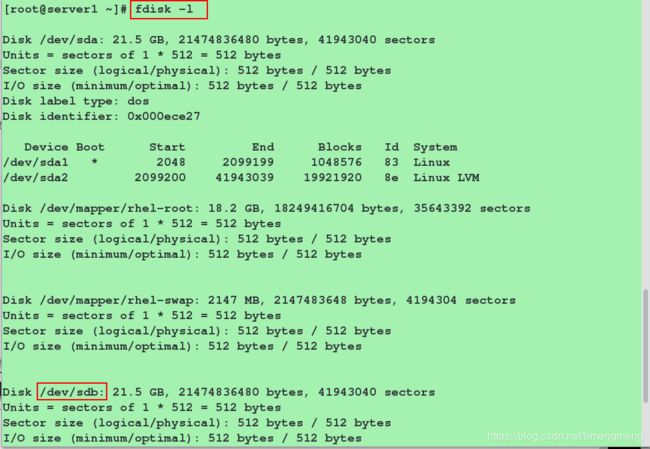
对服务端共享出来的磁盘(这里是/dev/sdb)进行操作(分区,格式化,挂载)
[root@server1 ~]# fdisk /dev/sdb #给磁盘/dev/sda进行分区,当然也可以不分区

[root@server1 ~]# mkfs.xfs /dev/sdb1 #格式化磁盘分区
[root@server1 ~]# mount /dev/sdb1 /mnt/ #下面对mnt目录以及其中的内容进行的修改相当于对/dev/sdb1的修改
[root@server1 ~]# cp -p /var/lib/mfs/* /mnt/ #使用-p同步权限
[root@server1 ~]# ll /mnt/
[root@server1 ~]# chown mfs.mfs /mnt #修改/mnt目录的所属用户和所属组为mfs(相当于修改的是磁盘)
[root@server1 ~]# ll -d /mnt/
[root@server1 ~]# umount /mnt
[root@server1 ~]# ll -d /mnt/ #此时的/mnt是普通的/mnt,用户和用户组是root

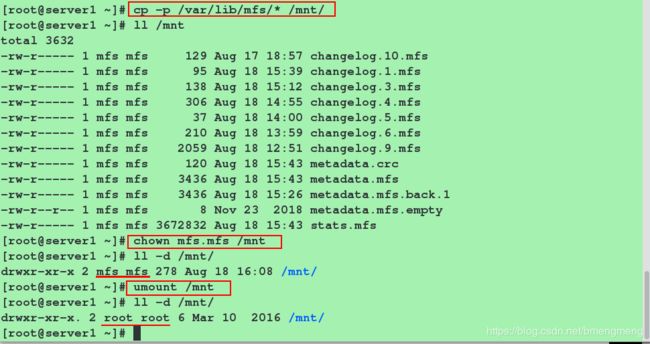
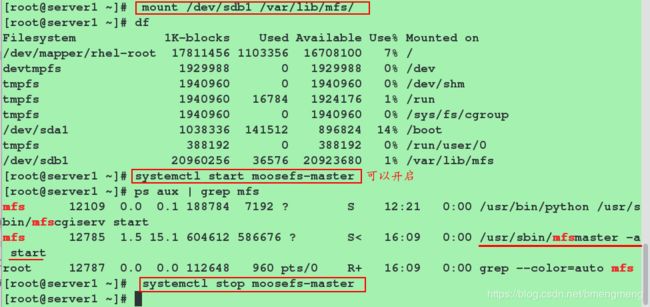
[root@server1 ~]# mount /dev/sda1 /var/lib/mfs/
[root@server1 ~]# df
#验证moosefs-master服务是否可以正常启动,因为/var/lib/mfs目录中的文件是挂载过来的。
[root@server1 ~]# systemctl start moosefs-master
[root@server1 ~]# systemctl stop moosefs-master
配置server4(iscsi客户端):这里的操作与server1故只贴图
![]()

连接,查看多了一块磁盘:

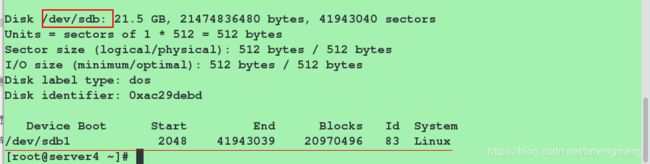
挂载并测试服务是否可以开启:

第三步:配置 pacemaker+corosync+pcs
首先要配置高可用的yum源:
[root@server1 ~]# vim /etc/yum.repos.d/westos.repo
#添加以下内容
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.27.250/westos/addons/HighAvailability
gpgcheck=0
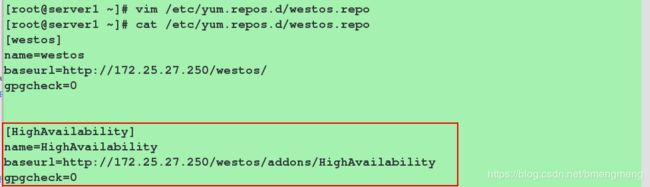
验证yum源是否添加成功
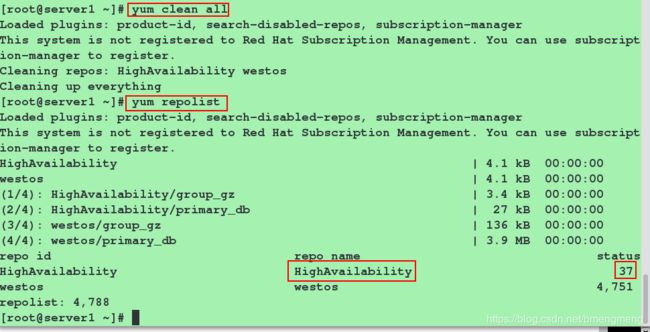
将此yum配置文件发送到server4端
[root@server1 ~]# scp /etc/yum.repos.d/dvd.repo server4:/etc/yum.repos.d/dvd.repo

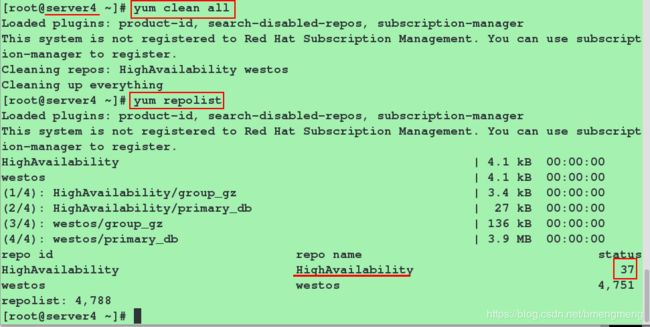
安装pacemaker+corosync+pcs,开启pcsd服务,并设置pcsd服务开机自启:
server1/4端:
#在server1/4端安装软件pacemaker,corosync和pcs(集群化管理工具)
[root@server1 ~]# yum install pacemaker corosync -y
[root@server1 ~]# yum install pcs -y
#在server1/4端开启pcsd服务,并设置为开机自启
[root@server1 ~]# systemctl start pcsd
[root@server1 ~]# systemctl enable pcsd
- server1
![]()

- server4
![]()


server1/4
#安装完pacemaker+corosync+pcs软件之后,会自动生成hacluster用户
[root@server1 ~] id hacluster
[root@server1 ~]echo redhat | passwd --stdin hacluster


设置server1——>server1,server1——>server4的免密,为后续集群各节点之间的认证做准备
server1
[root@server1 ~]# ssh-keygen #一路敲击回车
[root@server1 ~]# ssh-copy-id server1
[root@server1 ~]# ssh-copy-id server4

验证免密是否成功
[root@server1 ~]# ssh server1
[root@server1 ~]# logout
[root@server1 ~]# ssh server4
[root@server4 ~]# logout

集群各节点(这里是server1和server4)之间进行认证并创建名为my_cluster的集群,其中server1和server4为集群成员
server1
#集群各节点认证
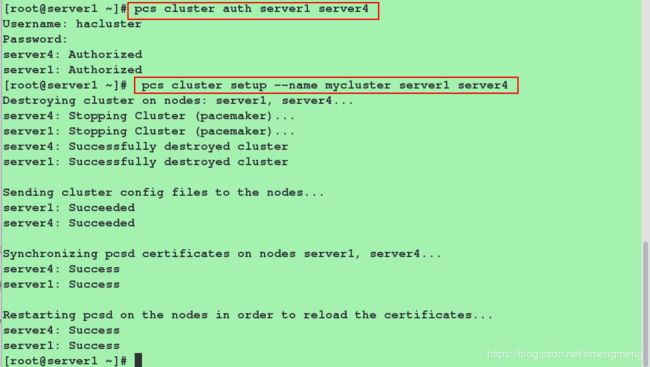
[root@server1 ~]# pcs cluster auth server1 server4
Username: hacluster (此处需要输入的用户名必须为pcs自动创建的hacluster,其他用户不能添加成功)
Password:
server4: Authorized
server1: Authorized
#创建集群
[root@server1 ~]# pcs cluster setup --name mycluster server1 server4 #该集群的名字mycluster
启动集群,并设置集群开机自启:
[root@server1 ~]# pcs cluster start --all #启动集群
[root@server1 ~]# pcs cluster enable --all #设置集群开机自启

查看并设置集群属性:
#查看当前集群状态:
[root@server1 ~]# pcs cluster status
#查看集群中节点的状态:
[root@server1 ~]# pcs status nodes


#检查pacemaker服务:
[root@server1 ~]# ps aux | grep pacemaker

#检验corosync的安装及当前corosync状态:
[root@server1 ~]# corosync-cfgtool -s
[root@server1 ~]# pcs status corosync #检查配置是否正确(假若没有输出任何则配置正确):
[root@server1 ~]# crm_verify -L -V #这里的错误是由于没有设置fence导致的,后面我们会设置
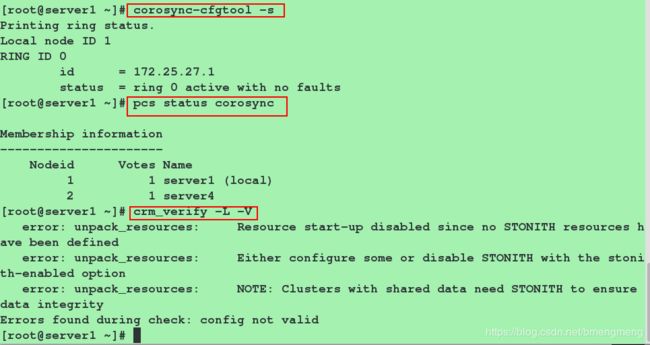
#查看我们创建的集群:
[root@server1 ~]# pcs status
Cluster name: mycluster #我们之前创建的集群的名字
No resources #我们还没有添加资源,所以资源这里什么都没有
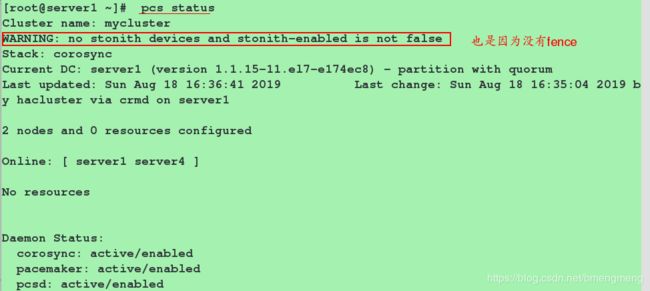
禁用STONITH:
pcs property set stonith-enabled=false
[root@server1 ~]# pcs property set stonith-enabled=false
禁用STONITH之后,再次检查配置,发现没有错误;再次查看我们创建的集群,发现没有警告
[root@server1 ~]# crm_verify -L -V #没有报错
[root@server1 ~]# pcs status #没有警告

查看的内容:pcs resource资源属性配置(不需要进行操作)
Pacemaker / Corosync 是 Linux 下一组常用的高可用集群系统。Pacemaker 本身已经自带了很多常用应用的管理功能。但是如果要使用 Pacemaker来管理自己实现的服务或是一些别的没现成的东西可用的服务时,就需要自己实现一个资源了。
其中Pacemaker 自带的资源管理程序都在 /usr/lib/ocf/resource.d 下。其中的 heartbeat目录中就包含了那些自带的常用服务。那些服务的脚本可以作为我们自己实现时候的参考。更多关于自定义资源请参考博文:http://blog.csdn.net/tantexian/article/details/50160159
接下来针对一些常用的pcs命令进行简要讲解。
查看pcs resource针对资源操作用法: pcs resource help 查看pcs支持的资源代理标准: [root@server1 ~]# pcs resource standards ocf lsb service systemd注:Pacemaker 的资源主要有ocf、lsb、service、systemd几大类。
LSB是为了促进Linux不同发行版间的兼容性, LSB(Linux Standards Base)开发了一系列标准,使各种软件可以很好地在兼容LSB标准的系统上运行, LSB即Linux标准服务, 通常就是/etc/init.d目录下那些脚本。Pacemaker可以用这些脚本来启停服务,可以通过pcs resource list lsb查看。另一类OCF实际上是对LSB服务的扩展,增加了一些高可用集群管理的功能如故障监控等和更多的元信息。可以通过pcs resource list ocf看到当前支持的资源。
要让pacemaker可以很好的对服务进行高可用保障就得实现一个OCF资源。CentOS7使用systemd替换了SysV。
Systemd目的是要取代Unix时代以来一直在使用的init系统,兼容SysV和LSB的启动脚本,而且够在进程启动过程中更有效地引导加载服务。查看默认资源管理器: pcs resource providers [root@server1 ~]# pcs resource providers heartbeat openstack pacemaker 查看某个资源的代理: pcs resource agents [standard[:provider]] [root@server1 ~]# pcs resource agents ocf:heartbeat #查看ocf:heartbeat这个资源的代理 查看pacemaker支持资源高可用的列表: pcs resource list
第四步:配置mfsmaster高可用(主/备)
首先要做的是配置一个IP地址,不管集群服务在哪运行,我们要一个固定的地址来提供服务。在这里我选择 172.25.27.100作为浮动IP,给它取一个好记的名字vip 并且告诉集群每30秒检查它一次。
另外一个重要的信息是
ocf:heartbeat:IPaddr2。这告诉Pacemaker三件事情,第一个部分ocf,指明了这个资源采用的标准(类型)以及在哪能找到 它。第二个部分标明这个资源脚本的在ocf中的名字空间,在这个例子中是heartbeat。最后一个部分指明了资源脚本的名称。
添加资源:vip
[root@server1 ~]# pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.25.27.100 cidr_netmask=32 op monitor interval=30s #其中vip这个资源的名字随意给
#查看添加vip资源后的情况
[root@server1 ~]# pcs status
[root@server1 ~]# pcs resource #查看我们创建好的资源
[root@server1 ~]# pcs resource show #同命令"pcs resource"
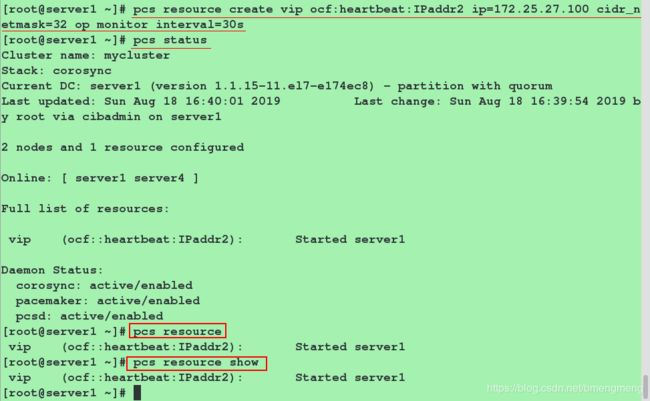
[root@server1 ~]# ip addr show eth0 #可以看到172.25.27.100这个ip

当然也可以在server4端打开监控,来实时监控集群中资源的状态
[root@server4 ~]# crm_mon #使用Ctrl+c退出监控
![]()
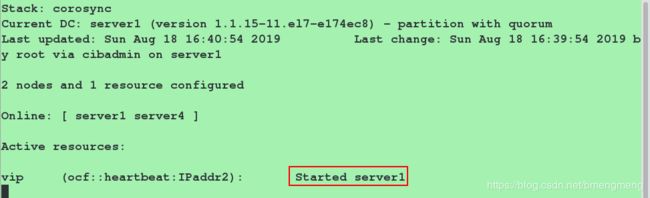
为了验证vip这个资源的高可用,我们停掉pcs集群中的server1端,看vip是否在server4上运行
[root@server1 ~]# pcs cluster stop server1
[root@server1 ~]# ip addr 此时已经没有vip
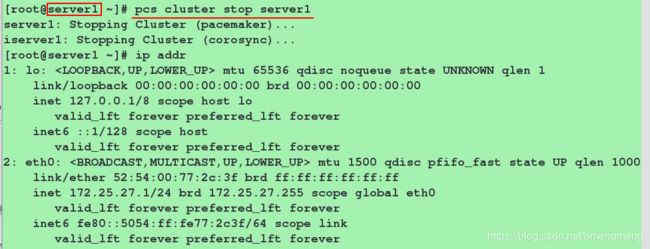
查看server4端的监控

此时vip在server4上面

为了查看是否回切,我们打开pcs集群中的server1端,看vip是在server4上运行还是在server1上运行
[root@server1 ~]# pcs cluster start server1
#在server4端查看监控,发现并没有回切
![]()
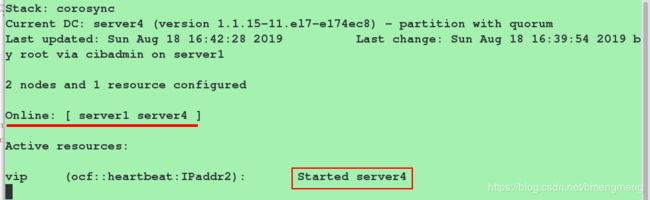
第五步:继续添加资源
添加资源:mfsdata(挂载信息)
[root@server1 ~]# pcs resource create mfsdata ocf:heartbeat:Filesystem device=/dev/sdb1 directory=/var/lib/mfs fstype=xfs op monitor interval=30s
添加资源:mfsd(启动moosefs-master服务)
[root@server1 ~]# pcs resource create mfsd systemd:moosefs-master op monitor interval=1min

在上述上各资源添加完成之后,在server4端查看监控,监控内容如下:

从上图我们可以看到三个资源(vip,mfsdata,mfsd)不在同一个服务端运行,这显然是不合理的。因此需要进行下面的操作,将这三个资源添加到一个资源组中
将上述三个资源添加到一个资源组中:确保资源在同一个节点运行
[root@server1 ~]# pcs resource group add mfsgroup vip mfsdata mfsd #添加资源vip,mfsdata,mfsd到同一个资源组mfsgroup中。(其中mfsgroup这个资源组的名字是随意给的)
#其中添加的顺序是有严格限制的,按照资源添加的顺序,进行添加。
![]()
再次在server4端查看监控,监控内容如下:
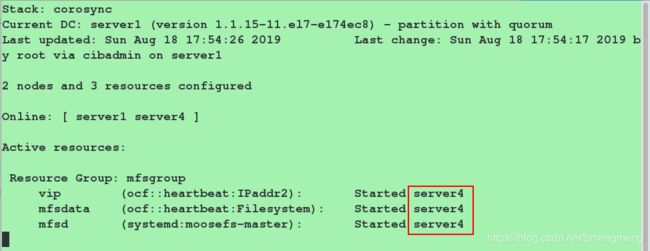
我们可以看到三个资源都在server4端运行,表示配置成功
再次测试:

此时都运行在server1上面,说明我们实现了高可用:
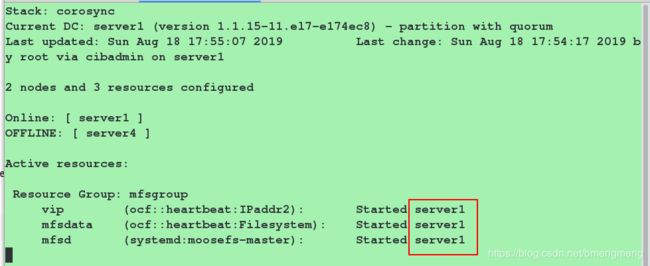
为了下来的实验,记得启动server4:
![]()
第六步:补充
修改server1,server2,server3,server4,物理机的本地解析文件
#server1端
[root@server1 ~]# vim /etc/hosts
172.25.27.1 server1
172.25.27.100 mfsmaster
#server2端,server3端,server4的操作同server1
[root@foundation83 ~]# vim /etc/hosts
172.25.27.100 mfsmaster
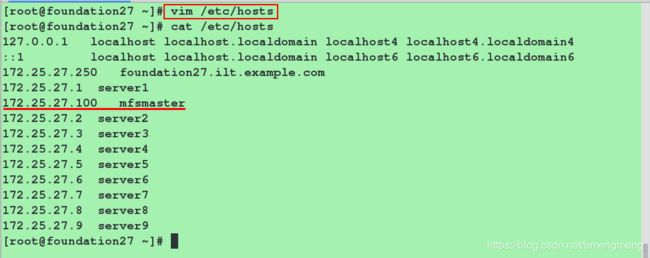
开启server2和server3端的moosefs-chunkserver服务
[root@server2 ~]# systemctl start moosefs-chunkserver
[root@server3 ~]# systemctl start moosefs-chunkserver
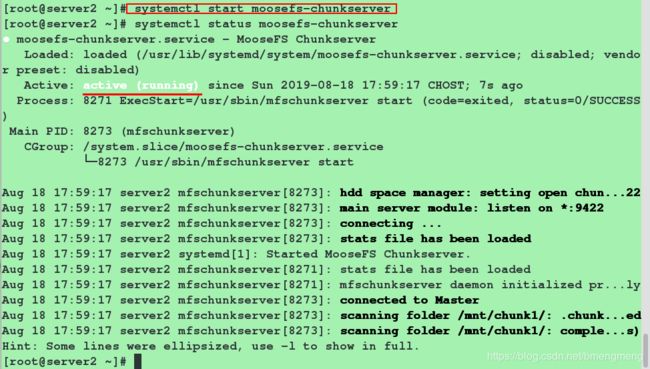

在客户端(物理机)进行测试:
[root@foundation27 ~]# cd /mnt/mfs
[root@foundation27 ~]# mfsmount
[root@foundation27 ~]# df
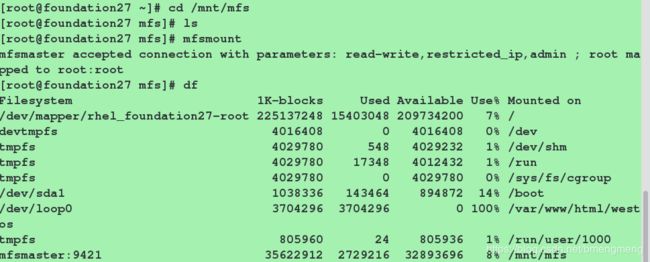
访问浏览器,看到的内容

为了表现实现mfsmaster高可用的优点,我们进行下面的实验:客户端往mfs分布式文件系统中写入内容,此时服务端(mfsmaster)端挂掉了,我们看看客户端会不会收到影响。
前提(因为我之前将客户端的操作删除了,没删除的可以忽略这一步):

如下操作:
#客户端往mfs分布式文件系统中写内容。
[root@foundation83 mfs]# dd if=/dev/zero of=dir1/bigfile3 bs=1M count=1000
#同时mfsmaster端挂掉mfsmaster服务
[root@server1 ~]# pcs cluster stop server4
#值的注意的是:两端的操作要同时进行,即两端都要卡顿一下


查看状态,切换到了server4:

我们发现客户端没有受到一丁点的影响,这就是实现mfsmatser高可用的好处
