【周志华】新智元 AI World 2018 世界人工智能峰会
主题:
- 万物互联,人机共生将带来美好的世界
转载 :
- 周志华:关于机器学习的一点思考
- “AI WORLD 2018世界人工智能峰会”开幕,深度探索AI智能世界,中关村海淀园从未停歇
- 机器学习教父激辩人机共生未来!AI WORLD 2018干货大放送
文章目录
- 1 机器学习取得了这么多的成功,这些成功的背后到底是什么呢?
- 能找到有效的深度模型
- 存在很多很强的监督信息
- 任务都是比较稳定的环境
- 2 能找到有效的深度模型
- 2.1 天下没有免费的午餐,深度神经网络必然有不适用的任务
- 2.2 基于非可微构件、非神经网络的深度模型,是下一步很值得探索的方向
- 3 存在很多很强的监督信息
- 3.1 当前机器学习高度依赖于强监督信息,弱监督学习还有很大空白
- 4 开放环境下的机器学习研究是通往鲁棒人工智能的重要环节
- 5 AI Era创新大奖揭晓
- 5.1 华人AI人物TOP10
- 5.2 国际AI企业TOP10
- 5.3 中国AI领军企业TOP10
- 5.4 中国AI创业企业TOP10
- 5.5 AI产品影响力TOP10
- 6 其它精彩演讲
- 6.1 生命3.0
- 6.2 认知智能
- 6.3 狭义深度学习已死,广义深度学习永生
- 6.4 深度网络在极端复杂任务前不堪一击
- 6.5 做医疗人工智能需要保持对医疗领域的敬畏态度
全程回顾
新智元于9月20日在北京国家会议中心举办AI WORLD 2018世界人工智能峰会,邀请机器学习教父、CMU教授 Tom Mitchell,迈克思·泰格马克,周志华,陶大程,陈怡然等AI领袖一起关注机器智能与人类命运。
爱奇艺
上午(周老师第一个讲):https://www.iqiyi.com/v_19rr54cusk.html
下午:https://www.iqiyi.com/v_19rr54hels.html
新浪:http://video.sina.com.cn/l/p/1724373.html

各位朋友,大家上午好!谢谢新智元杨总的邀请,前面一直没有机会参加,今天很高兴有这个机会。我本人从事的是机器学习方面的研究,今天就和大家汇报一些关于机器学习方面粗浅的看法,谈一谈机器学习发展取得了哪些成功,后面会有哪些问题值得进一步关注。

大家都知道,这一轮的人工智能热潮很大程度上是由于机器学习,特别是其中深度学习技术取得了巨大的成功。可以说今天每个人、每天都在谈机器学习,机器学习已经无所不在,各种各样的智能应用当中如果离开了机器学习,基本上是不可想像的。

我们可能要问这样一个问题:
1 机器学习取得了这么多的成功,这些成功的背后到底是什么呢?
大家常说,现在成功的智能应用后面有三个重要的条件:
- 现在有大数据了,
- 现在有很强大的计算能力了,
- 我们在算法方面取得了很多突破。
这三个因素都特别重要,但今天我们将主要聚焦于机器学习技术本身,谈一谈机器学习技术本身取得这些进展,背后到底有哪些原因。

其实,无外乎就是三个因素:
能找到有效的深度模型
存在很多很强的监督信息
任务都是比较稳定的环境
现在所有成功的机器学习应用背后都离不开这三者,下面我们分别来看。

2 能找到有效的深度模型
2.1 天下没有免费的午餐,深度神经网络必然有不适用的任务
首先是深度模型。
现在深度学习在图像、视频、语音这些数字信号建模任务当中取得了巨大的成功。如果我们问一问大家, “深度学习” 是什么?我想从绝大多数人那里得到的答案都会是:
深度学习就是深度神经网络**,甚至认为“深度学习”就是“深度神经网络”的同义词,谈到深度学习就要从深度神经网络或者从神经网络谈起。
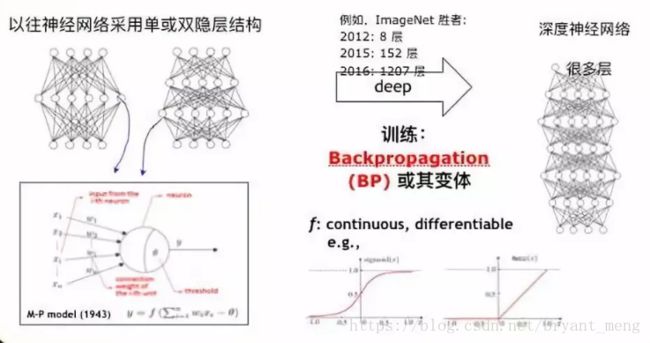
事实上,神经网络并不是新事物,我们已经研究了半个多世纪,只不过以前我们通常研究的是有一个隐层或两个隐层这种比较浅的神经网络,其中每个计算单元都是非常简单的模型。早在1943年,我们就已经把它抽象成了这样一个非常简单的数学公式,就是从外界收到输入X,经过W放大,总的输入如果要比θ高,我们就会用激活函数处理进行输出。这样的模型到今天依然在沿用。
深度神经网络带来的最大区别是什么呢?虽然有各种各样的模型,各种各样的算法,但是最根本的差别就是现在我们用了很多很多层。
深度神经网络最著名、最早的成功来自2012年,在计算机视觉领域最著名的ImageNet比赛上获胜。当时这个获胜的模型用了8层,2015年获胜的模型用了152层,2016年就用到了1207层,今天几千层的模型比比皆是。
实际上,这样的模型当中有大量参数需要计算,所以需要非常复杂、非常庞大的计算系统。虽然现在我们有了很强的计算设备和很巧妙的算法,但是我们能够做到这一切,根本的原因之一是神经网络中基本计算单元激活函数是连续可微的。原来浅层神经网络用的是左边的函数,也是连续可微的,深度学习的年代我们通常会用右边这样的函数或变体。
不管怎么样,可微性给我们带来了非常重要的结果,就是可以很容易地计算出梯度,基于梯度的调整就可以用著名的BP算法来训练整个模型。
这一点非常重要,因为如果不是从事机器学习研究的朋友会觉得, 神经网络半个世纪之前就有了,到了今天我们之所以能够做更深的神经网络,只不过是因为计算能力强,现在能够训练了。 实际上不是这样的。
2006年之前,可以说我们都不知道怎么训练出5层以上的神经网络,根本原因是一旦层数高了以后,用BP算法梯度就会消失,然后就不知道怎么学习下去。所以,2006年的时候Geoffrey Hinton做了很重要的工作,通过逐层训练来缓解梯度消失,使得深层模型能够被训练出来。后来有了一系列深度学习的工作,包括到今天为止的很多前沿研究,都是在防止深层网络中梯度消失,使得梯度更新搜索能持续下去使训练能够完成。

神经网络取得了非常大的成功,但任何一个模型都必然存在缺陷,神经网络也是这样。
常用神经网络的朋友知道,现在深度神经网络有很多问题。大家经常说的一件事情就是要花大量的精力调整参数,参数实在太多了。不仅如此,这还会带来另外一个严重的问题:哪怕我告诉你同样的算法、用同样的数据,如果不告诉你参数是怎么调的,可能就没有办法得到同样的结果。
此外,还有很多别的问题,比如我们现在用的神经网络模型的复杂度是固定的,一旦先确定了一个模型,就把这个模型用下去。问题是,在解决一个现实问题之前,我们怎样才能知道什么样的模型是最恰当的呢?我们不知道,所以通常会用一个过度复杂的模型来做问题,做的过程当中不断把它简化。
最近如果大家关心深度学习方面的一些前沿研究,可能就会发现现在有大量的论文是关于模型压缩、模型简化等等,事实上都是由这个原因导致的。 我们能不能在使用模型的最初不要使用那么复杂的东西?先使用一个比较简单的,然后随着数据和训练的过程让它自适应地、自动地提升复杂度呢?很遗憾,我们对神经网络很难做到这一点,因为我们一旦用BP算法基于梯度搜索来做这件事情,如果事先结构都完全不知道,那么求梯度的对象也就不知道了。
这里有很多的问题,更不用说还有其它的缺陷,比如大的训练数据、理论分析很困难、黑箱模型等等。
有些工业界的朋友可能会说,前面你们谈到的这些缺陷都是从学术角度来说的,我关心实践,只要性能好就行,至于学术上有什么缺点我不关心。实际上就算从这个角度来看,可能也还有很多的需求希望我们去研究其它的模型。
如果我们真正看一看今天的深度神经网络到底在哪些任务上取得了成功,其实我们可以看到无外乎主要就是图像、视频、语音,涉及到这些对象的任务。它们非常典型,都是一些数值信号建模的任务。而在很多其他的任务上,深度神经网络表现并没有那么好,比如可能有的朋友接触过Kaggle这个数据分析竞赛的网站,上面每天都有很多数据分析的任务,有订机票的,有订旅馆的,到今天为止,虽然深度学习网络这么成功,很多这样的任务上我们可以看到获胜的通常还是一些相对传统的机器学习技术,而不是深度神经网络。

事实上,机器学习界早就很清楚这件事情了,我们有一个经过严格证明的定理,叫做 “没有免费的午餐定理”,也就是任何一个模型可能只有一部分任务是适用的,另外一些任务是不适用的。
所以,虽然深度神经网络在有些任务上很成功,但对别的应用来说,我们有没有可能设计出新的模型,在这些任务取得以往没有取得的效果? 这可能也是非常值得关注的一件事情。
2.2 基于非可微构件、非神经网络的深度模型,是下一步很值得探索的方向

如果我们重新审视深度模型自身的话,会发现今天我们所谈的深度模型其实都是指深度神经网络,而用更学术的话来说,这是由多层参数化可微的非线性模块搭建起来的模型,而它本身能够用BP算法去训练。
最近有些深度学习网络的研究在考虑怎样用一些不可微的激活函数,但是实际上是怎么做的呢?先用了一个不可微的激活函数对现实建模,然后在优化的过程当中逐渐近似放松,最后还要把它变成一个可微的东西求解,所以最终还是离不开可微性。
但是,现实世界当中并不是所有规律都是可微的,或者能够利用可微构件最优建模的,而且另一方面我们机器学习界早就经过了很多年的研究,也有很多不可微的构件,这些构件以后有没有用呢?现在我们就在考虑这样一个很基础的问题,就是能不能基于不可微构件进行深度学习?

这个问题如果得到答案,我们可以得到一系列其它问题的答案,比如深度模型是不是只能用深度神经网络来做?我们有没有可能不通过BP算法来做出这种深度模型?我们能不能在图像、视频、语音之外的任务也能够获得一些深度模型,帮助我们获得更好的性能?

最近我们的课题组做了一些研究,提出了一个新的模型叫做 “深度森林”,这是不基于神经网络来做的模型,它的基本构件是决策树,本身是不可微的,所以不能用BP训练,模型复杂度可以自己根据数据调整,超参数比深度神经网络要小。除了大规模的图像类任务之外,很多的任务上它的性能已经达到或者接近了深度神经网络的性能。从学术上来说,特别值得关注的就是它是第一个非神经网络,不使用BP算法训练的深度学习模型。

后来国际上关于这件事情也有一些反响和探讨。Keras的创始人说,这种可微层是当前深度学习模型的根本弱点,现在我们的模型本身是不使用可微层的;深度学习的奠基人Geoffrey Hinton说放弃BP从头开始,现在我们的模型就完全没有使用BP算法。
这类模型不一定仅限于“深度森林”这样的模型,基于非可微构件、非神经网络的深度模型可能是下一步很值得探讨的方向。大家知道深度神经网络已经研究了二十多年,再往下研究的空间可能不见得那么大,但是其它的模型有没有可能做深呢?一旦我们往前走了一步,可能会给我们带来巨大的空间。
这只是学术上的意义,来自工业界做应用的朋友可能会问,应用上到底有什么东西用它做比较好?在图像、视频、语音这些纯的数值建模之外,涉及到符号数据、离散数据、混合建模的问题,可能是这种不可微模型能够发挥作用的地方。

比如最近我们和国内一个非常大的互联网金融公司合作,做在线支付的非法套现检测。这个公司非常大,大家每天都在接触它,每天有大量的网上交易,比如在2016年“双11”这一天,一天就有1亿多交易是通过网上支付来做的。非法套现是一个很大的问题。
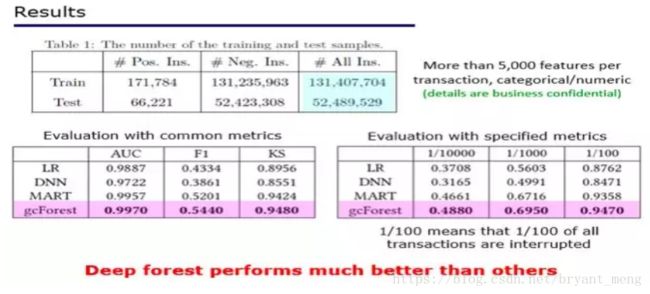
我们给大家看个结果 ,训练数据用了1亿3千多万的真实交易,测试数据用了5千多万真实交易,这可能是世界上最大的关于互联网交易非法套现的数据。这家公司内部有一个大型分布式机器学习系统,他们的工程师很厉害,做了深度森林的大规模分布式实现,实测结果来看比系统中以往的模型包括深度神经网络在内的性能都还要更好一些。这也验证了我们所猜想的,在很多其它任务上,图像、视频、语音之外的任务上,非神经网络模型能找到用武之地。

另外一方面,这毕竟只是一个起点,因为深度神经网络研究了20多年,深度神经网络经过几十万上百万研究实践者这么多年的探索改进,而非神经网络深度学习的研究才刚刚开始,只有几个人做了一点点事情,未来有非常多可以探索的东西。任何一个新技术往前走的话都有很多工作要做。关于深度模型真正重要的意义是,以前我们以为深度学习只有深度神经网络,现在知道这里面可以有很多其它的东西。
3 存在很多很强的监督信息
3.1 当前机器学习高度依赖于强监督信息,弱监督学习还有很大空白
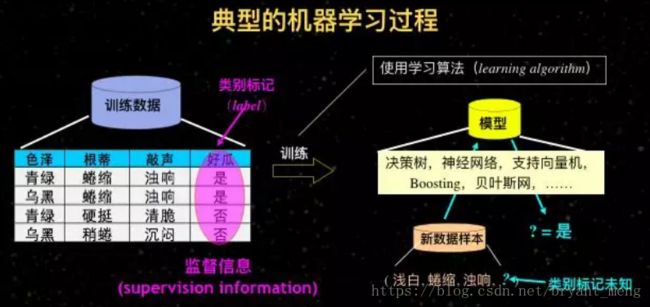
关于监督信息。对于一个机器来说,我们拿到很多数据之后,经过训练得到模型,这个模型能够发挥作用,能够做精确预测。这里面很重要的是我们需要有很多数据,而且这些数据需要有监督信息。

深度学习需要大量的样本,2012年ImageNet获胜的网络已经用到超过1500多万样本,而现在的网络越来越大,所需要的样本越来越多。 大家可能会有一个误解,大数据时代数据样本是不是不成问题?

其实不是的。
样本需要标记,我们现在大量的人力物力都花在这件事上,比如前段时间有讨论人工智能会不会使得一些职业消亡。是不是消亡我们没看到,但是我们已经看到一个新的职业,就是数据标注已经变成一个产业。这件事情不管它好还是不好,反正它就在那儿,至少告诉我们机器学习技术现在对强监督信息是高度依赖的。

谈到这件事可能有的朋友会想到前段时间很热门的AlphaGo,最早的AlphaGo使用人类职业六段以上的所有棋局,超过16万棋局进行学习。后来发明了AlphaZero,不使用人类棋局, 通过两个程序直接对弈提升性能,这样是不是不需要监督信息了呢?
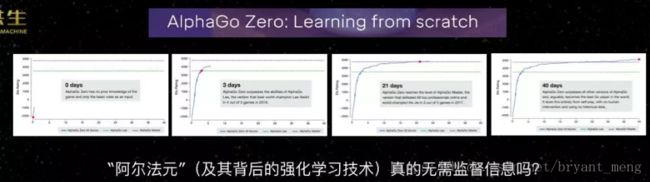
所谓的AlphaZero,DeepMind说它是“从零开始学习”,第一天没有任何数据,第三天超过战胜李世石的版本,第21天超过Alpha Master,第40天达到人类见到的最强能力。 中间没有用任何人类的棋局,这是不是意味着它背后的强化学习技术真的不需要监督信息?

其实不是这样的。 因为非常重要的一点,是当两个程序在对弈的时候,我们一定能够判断出胜负,而胜负规则是非常强的监督信息,是上帝判断。
打个比方来说,我要建一个能抵抗18级台风的桥,事先不知道怎么建,没有人教我怎么建,不管怎么样,如果我能建出一个东西来,就有一个“上帝”告诉我,你这个东西能扛过去、那个东西扛不过去,有了这个指导信息,经过不断摸索最后就可能把这个桥建出来。
真正的现实应用中哪里能得到这样的上帝规则? 根本得不到。我们也不可能通过无成本探索像围棋这样获得大量的样本。我们没有办法去做真正的不需要任何数据,不需要任何标记的学习。

我们现在能做的还是要往弱监督学习上做。
所谓的弱监督学习,就是希望监督信息不用那么多了,稍微少一点,它还是能够工作得很好。举几个典型的弱监督学习的例子:在医院里诊断乳腺图像的影像,希望看到影像中有没有钙化点。一个医院有很多数据,比如100万幅图像,但是医生只标注了一万幅,有99万幅没有标记,这种叫做监督信息不完全。
第二种情况,可能医生只告诉我们这个图像里面有病灶,但是病灶在哪儿没标出来,这时候我们把它叫监督信息不具体。
还有更多的情况,比如医生由于疲劳、疏忽等标注中间有错误,我们就把它叫做监督信息不精确,这是三种典型的情况。

事实上很多应用里这些问题都普遍存在,大量的应用都能看到这三种情况。对这些情况事实上机器学习界有一些探索,比如第一种情况我们做半监督学习、主动学习;第二种情况有多示例学习,有MIML;第三种有众包学习、带噪学习。这是好的一方面。
另一方面,强监督学习我们已经研究很多,非常典型的弱监督学习也已经有研究,但是还有更多的弱监督状态,例如这个图中几朵云之间的过渡状态,这些状态有的连学术探讨的文献都还很少见。
关于弱监督学习,应该说还有大量的事情需要我们去做。

4 开放环境下的机器学习研究是通往鲁棒人工智能的重要环节
接下来谈一谈任务环境。
机器学习现在取得胜利,基本上都是在封闭静态环境里面。我们要假定很多东西都是固定的,比如我们要假定所有的数据都来自于独立同分布,数据分布恒定。
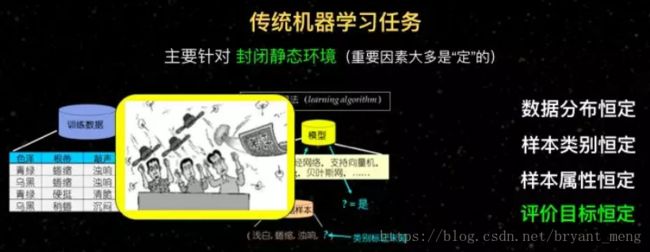
我们通常要假定样本类别恒定,训练数据只能让我识别苹果和梨,以后给我的东西我就只会识别成苹果和梨,给我一个菠萝也会只从苹果和梨当中选择一个,判断到底是两个中间的哪个。
样本属性也是恒定的。样本里面用一百个属性来描述我的数据,预测的时候也要把这一百个属性给我,中间不能发生变化。
甚至我们的目标也要恒定。一个模型好,我们就认为它就是好的,不管对谁来说都应该是一个好的模型。

事实上,我们现在越来越多地碰到所谓的开放动态环境。在这样的环境中可能一切都会发生变化。
现在有一条船开到海上去,我们不断搜集海面的数据来做导航,可以知道今年在海上碰到的海冰分布和去年就是不一样的,这个数据其实每年都在变。这就是数据分布发生变化。
我们碰到以前没有见过的困难情况,这是新的类别。如果把船开到两极地区,由于环境恶劣,接入困难等等,有的属性丢失了拿不到,这时候我们怎么办?是不是属性不够就不能做预测,不能用了呢?
最后,我们同时要兼顾很多目标,只考虑一种目标得出来的模型往往可能是不能用的模型,必须要多个目标都不错才能用。
可能会出现很多的变化,但是不管什么样的变化出现,我们都希望好的时候要好,坏的时候不能太坏。这时候模型的鲁棒性是一个很根本的要求。
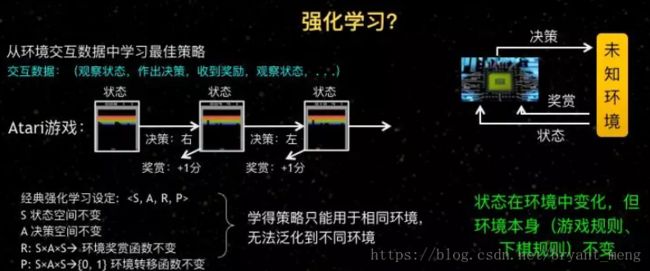
关于这个问题,可能有的朋友如果对机器学习比较熟悉的话,马上就会想到,不是有一种强化学习技术吗? 这种强化学习技术是通过跟环境交互来进行学习的,它不就自动能适应环境吗?
事实上这可能是一个误解,现在虽然已经有很多强化学习的研究,包括用强化学习来打游戏,在很多游戏上获得胜利等等,看起来是和环境交互,但事实上,在整个强化学习的经典假定里面,它所考虑的是状态在环境中的变化,但是环境本身的基本规则比如下围棋的游戏规则,在游戏过程中是不变的。
绝对不是说在学习的过程中是一种环境,在用的时候环境变化了,我这个模型还能用,那是不行的。比方说训练下棋模型的时候原来是什么规则,以后模型使用的时候仍然是这样一种规则环境。
这个问题使用传统强化学习技术还远远解决不了。

国际上怎么看这件事?
在国际人工智能大会(AAAI)Tom Dietterich教授做了一个主席报告,叫 “通往鲁棒的人工智能”,特别提到现在人工智能技术取得巨大发展,越来越多地面临高风险应用。

所谓高风险应用是指自动驾驶汽车、自主武器、远程辅助外科手术等等,这一类应用无一例外都是一旦出现了问题,会造成巨大的损失。所以,我们才希望不要出问题,希望学习过程必须有鲁棒性。

他提出未来的人工智能系统需要能够应对未知情况,他给了一个说法,叫做 “Unknown Unknowns” ,指的就是开放环境。开放环境下机器学习研究是通往鲁棒人工智能的非常重要的环节。
最近有另外一个消息,美国国防部宣布开发下一代人工智能技术,用一句话来说,“旨在开发能够进行学习并适应不断变化环境的机器”。 这句话其实就是把所谓的开放动态环境下的学习换了一个表述,并且用到军事应用里去。

从学术上来说,我们组里对这件事关注得比较早,有一些探索,前面Dietterich教授的报告也提到了我们的一点工作。这张片子里面是我们最近关于应付各种变化的一些探索性工作。

最近OpenAI组织了一个强化学习的比赛,比赛内容是打游戏。最近这段时间可能大家听到关于人工智能技术来打游戏的消息有不少了,比如DeepMind的消息等等。现在我们说的这件事和其他那些有什么不同呢?
以前打游戏的时候是把告诉你要打什么游戏,学习程序可以把整个游戏都玩一遍,玩够之后再和人玩,也就是说训练的时候可以看到所有的场景。
而这个比赛和以前不太一样的是,它给我们的训练场景和测试场景是完全不一样的,训练场景58个关卡,测试11个关卡,环境变化非常明显,最重要的是考验我们怎么去适应环境变化的能力。
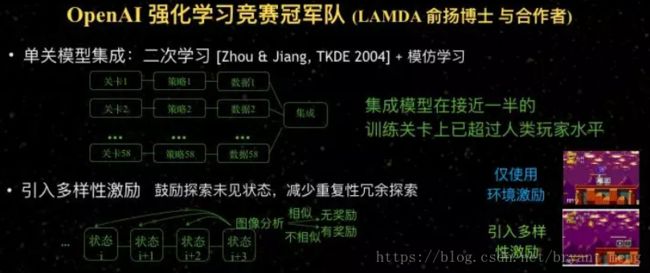
OpenAI首届迁移学习竞赛,南大阿里团队夺冠,中科院第二
他们最重要是使用了两个小技术,都是我们自己做出来的技术。
第一个是2004年我们提出的叫 “二次学习技术” ,先学一个模型,再做第二次学习得到进一步的加强。这个技术后来被 Geoffrey Hinton 重新命名为Knowledge Distillation。
另外一个技术是我们通过集成学习研究得到启发,引入多样性激励。如果只使用传统强化学习环境的激励,进去好的状态之后就很难再探索了;而现在引入多样性激励之后,一个地方做得好,会自动去探索别的地方。
我们这两个原创的小技术结合起来得到一个好的结果,比拿别人发明的技术获胜做起来更好玩。

总结一下,现在机器学习成功的背后主要有三个原因,有效的深度模型,存在强监督信息以及学习环境比较稳定。但是,现实应用里面这三件事情都不成立,有的场合可能还没有很适合的深度学习模型,监督信息也不够强,任务环境不断变化等等。
所以下一步,机器学习的研究或者应用特别要关注研究新型深度模型、弱监督学习以及开放环境的学习。
这只是我自己一些非常粗浅的看法,不一定准确,仅供大家批评,谢谢!
5 AI Era创新大奖揭晓
AI Era创新大奖是根据新智元智库专家评选、新智元用户票选、网络影响力指数、财务指数等四大维度大数据综合评定,评选出2018年度对AI领域作出重大贡献,切实推动AI进步和发展的人物、企业和产品。
5.1 华人AI人物TOP10

5.2 国际AI企业TOP10
5.3 中国AI领军企业TOP10
5.4 中国AI创业企业TOP10
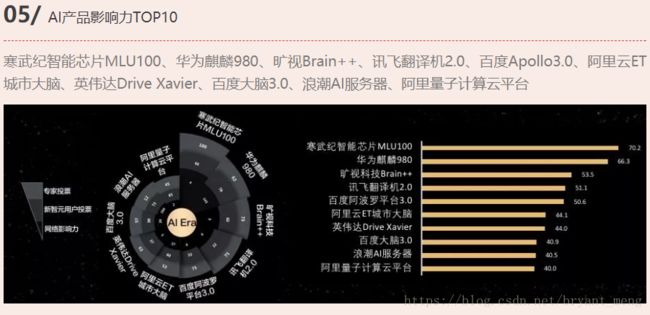
5.5 AI产品影响力TOP10
6 其它精彩演讲
6.1 生命3.0

生命1.0就是最原始的生命形式,如细胞,生命只是在不停复制。
到了生命2.0阶段,这是人类所在的地方:人类能够学习,适应不断变化的环境,并能有意地改变这些环境。但我们还不能改变我们的身体自身,不能改变我们的生物遗传。Tegmark 将这种对比比喻成软件和硬件之间的对比。
第三个阶段,即生命 3.0 阶段。在这个阶段,我们把人工智能用于所有任务,也就是所谓的AGI(通用人工智能)。人类不仅可以重新设计自身的软件,还可以重新设计自身的硬件。
6.2 认知智能

胡国平表示人工智能被分为三个台阶:计算智能、感知智能和认知智能,尽管机器在计算智能方面已经超过人类,感知智能方面也几乎可以达到人类水平,但在强调知识、推理能力的认知智能方面,机器与人类仍有差距。
表示现在多数产业在认知智能上面的做法大多停留在纯文字层面,然而语言只是人类智慧的载体和表层,如果只纯粹在文字层面做认知智能,可能会有着极矮的天花板。若想在认知智能路上走得更远,需要关注的是语言之下智慧本质。
6.3 狭义深度学习已死,广义深度学习永生

- 不可微深度学习
- 应用
6.4 深度网络在极端复杂任务前不堪一击

我们还需要从有限的数据集中学习,但学出的模型必须在无限大的测试集上也保持有效和稳定。当然,创造无限大的测试集是不现实的,不过,Yuille教授指出,换一种思路,“敌人的敌人即是朋友”,我们可以用最极端的情况来测试模型。
6.5 做医疗人工智能需要保持对医疗领域的敬畏态度

做医疗人工智能需要保持对医疗领域的敬畏态度,不可小看医学数据和疾病本身的复杂度