大数据告诉你,世纪佳缘都是谁在相亲(python爬虫&分析,附全部代码)
公众号: 数据小斑马,关注即可获得价值1000元的数据分析学习资料
数据分析学习目录:
一、Excel系列——四大常用函数及十大高级图表
二、SQL系列——性能优化/多表关联/窗口分析函数等
三、统计学系列——概率论/置信区间/相关/抽样等
四、Pandas系列——数据读取/清洗/规整/分析实战等
五、Python做图系列——箱型图/散点图/回归图/热力图等
六、业务积累系列——流水预测/精细化运营/排序算法等
七、Kmeans系列——原理/评价指标/RFM实战等
八、决策树系列——算法原理/调参/python实现/项目实战
九、贝叶斯系列——算法原理/3种模型/文本分类实战
十、神经网络系列——BP算法原理/最小二乘法/项目实战
520已经过去,你是否收到了心爱的TA精心准备的礼物呢?或者你的TA还迟迟未出现?
小编一直认为相亲也是一个不错的交友方式,毕竟工作后,生活圈变得很窄,接触异性的机会实在太少。认识-了解-相爱-走入婚姻,就是一个漏斗转化的过程,第一个口子开得越大,就越有可能发现你的TA。
因此本文通过对世界佳缘网进行一次数据爬取分析,想更多地了解目前在网上相亲的人的特征,也希望能够通过此分析,折射出婚恋现状。
-------先放结论,感兴趣者可详细阅读---------
1、TA们来自哪里?
大部分来自繁华的一二线城市,TOP4是北京、深圳、成都和广州
2、他们自身条件如何?
年龄:男性的年龄有两个小高峰,一个是在30-40岁,另一个是在60-70岁,女性则集中在30-50岁。
身高:男性的身高集中在170-180cm,女性在160-170cm
学历:男女性都是本科占比最高,其次是大专。男性在本科以上学历人数要多于女性,女性在本科以下人数多于男性
财产:男性有房占比44%,女性有房占比38%,男女性有房有车的占比均达到31%,经济状况较好
3、他们婚姻状况如何?
男女性都是离异最多,女性未婚要多于男性,丧偶低于男性
4、他们对另一半的诉求?
年龄:希望对方年龄与自己较为匹配,差距不要过大。女性普通希望男性大自己3-5岁,男性则普通希望女性小自己5-10岁
身高:男性对身高要求集中在160-170cm,女性要求集中在173-183cm。整体而言,女性对身高要求要更严苛一些。
情感:品性善良、为人简单、待人真诚、性格合适
本篇以讲解可视化技巧为主,具体的分析过程如下(文末有超大福利赠送):
- request + post爬虫
- 数据清洗
- 数据规整
- 数据分析及可视化
公众号: 数据小斑马,关注即可获得价值1000元的数据分析学习资料
Part 1 利用request&post爬取世纪佳缘数据
一、爬虫逻辑
打开世纪佳缘网PC端,要寻找包含用户信息的页面,在点击了众多按钮之后,终于搜索中发现了玄机

通过页面右击-检查-Netword-XHR,刷新后拉到页面底部,点击下一页,发现加载了新的json文件,点击Response,复制里面的内容到文本编辑器,就是我们想要的内容,说明我们可以通过链接直接获取API文件,而不用进行网页解析


点开Header,发现两个文件的URL是一样的,让我误以为只要多次爬取这个链接就可以获得不同的数据,但结果发现每次爬都是一样的。
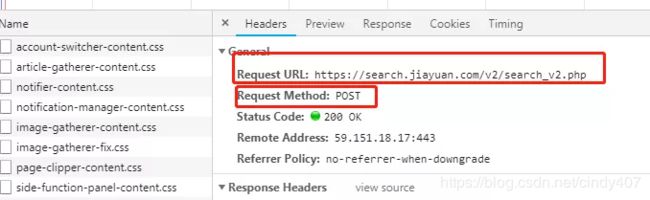
后来拉到页面底部,研究了POST参数发现:其中P就是页面,sex是性别,其余参数都是可以不管的

所以通过上传POST参数 + URL,成功爬取了男女数据各10万条(花费了4h~~)
# 一、数据获取(request + post)
all_data = []
for i in ['m','f']:
for j in range(1,500):
# post方式,需要上传参数获取数据
post = {
'sex': i,
'key': '',
'stc': '',
'sn': '',
'sv': 1,
'p': j,
'f': '',
'listStyle': '',
'pri_uid': '',
'jsversion': ''
}
# 在点击下一页时,url不变,说明要上传参数才能获取新的数据
url = r'https://search.jiayuan.com/v2/search_v2.php'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400'}
r = requests.get(url, params=post, headers=headers)
df = json.loads(r.text)
df = df["userInfo"]
print(df)
for k in range(len(df)):
all_data.append(df[k])
# 暂停0.2s,避免反爬
time.sleep(0.2)
print(all_data)
data = pd.DataFrame(all_data)
# 设置pandas行列全部展示
pd.options.display.max_rows=None
pd.options.display.max_columns=None
print(data.head())
# 保存本地
data.to_excel(r'C:\Users\cindy407\Desktop\love_data_2.xlsx')

Part 2 数据清洗和规整
公众号: 数据小斑马,关注即可获得价值1000元的数据分析学习资料
在数据清洗时,很伤心地发现,20万条数据,删除重复项后,不到2000条,我推测是搜索的排名规则问题,导致很多人大量重复地出现。不过2000条也差不多可以做个有模有样的小数据分析了,哈哈。
# 二、数据清洗
data = pd.read_excel(r'C:\Users\cindy407\Desktop\love_data.xlsx')
# 1 删除重复值
print(data.duplicated(subset=['realUid']).value_counts())
data.drop_duplicates(subset=['realUid'],keep='first',inplace=True)
# 2 删除掉不必要的字段
df = data.drop(['count','helloUrl','image','income','online','randAttr','sendMsgUrl','realUid', 'sexValue','userIcon','work_sublocation'],axis=1)
# 3 删除缺失值
df.dropna(subset=['matchCondition','work_location'],how='any',axis=0,inplace=True)
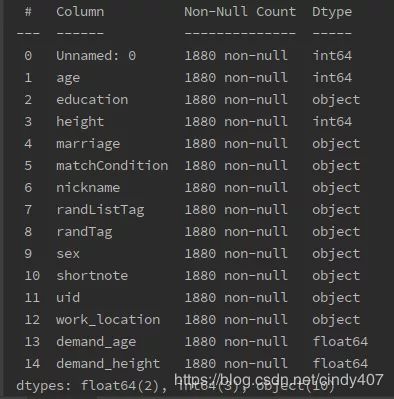
print(df.info())
# 4 看是否有异常值
print(df.describe())
# 5 保存本地
df.to_excel(r'C:\Users\cindy407\Desktop\love_data_deal.xlsx')
鉴于要进行男女性对比,目前样本数女性偏多,因此进行了随机抽样,保证男女性都是940条数据。至此,就可以开始进行分析啦
# 数据规整
df = pd.read_excel(r'C:\Users\cindy407\Desktop\love_data_deal.xlsx')
df['uid'] = df['uid'].astype('str')
# 1 随机抽取,保持男女样本数量一致,便于对比分析
print(df.groupby(['sex'])['uid'].count())
df1 = df[df['sex']=='女'].sample(n=940,random_state=None)
df2 = df[df['sex']=='男']
df = pd.concat([df1,df2],axis=0,ignore_index=True)
print(df.info())
Part 3 数据分析和可视化
公众号: 数据小斑马,关注即可获得价值1000元的数据分析学习资料
(分析过程不附代码,文末有全部代码下载方式)
一、描述性分析
1、年龄分布情况
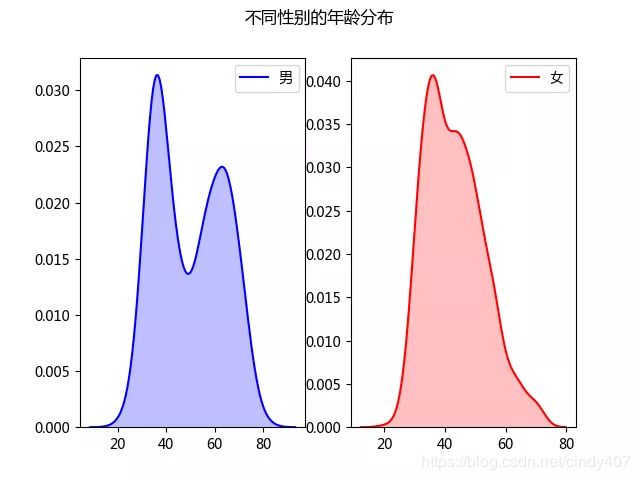
男性的年龄有两个小高峰,一个是在30-40岁,另一个是在60-70岁,女性则集中在30-50岁。
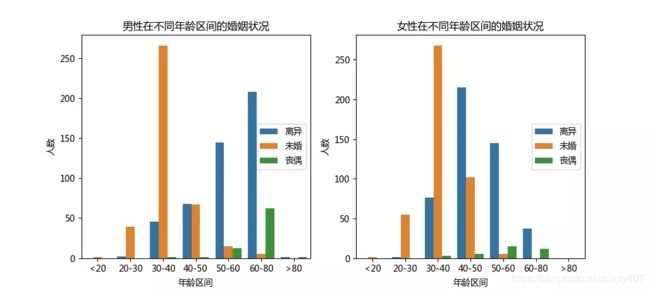
通过不同年龄区间的婚姻状况看,男女性在30-40岁均是未婚居多,而在40岁以上离异为主。其中不少60岁以上的男性处于丧偶状态。
2、身高分布情况
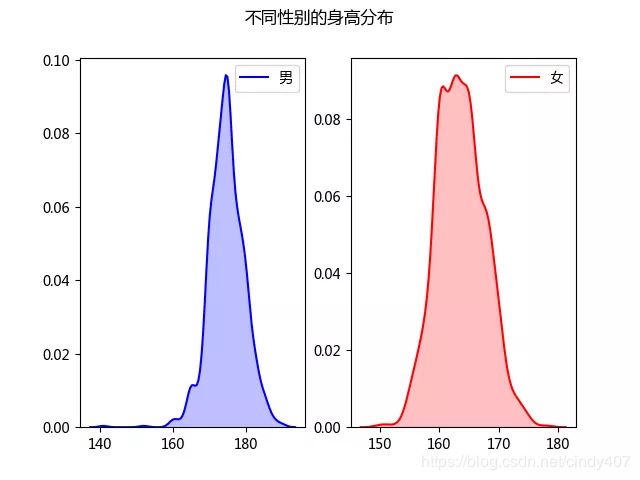
男性的身高集中在170-180cm,女性在160-170cm
3、学历分布情况

男女性都是本科占比最高,其次是大专。男性在本科以上学历人数要多于女性,女性在本科以下人数多于男性,男性的受教育水平要高一些
4、婚姻状况
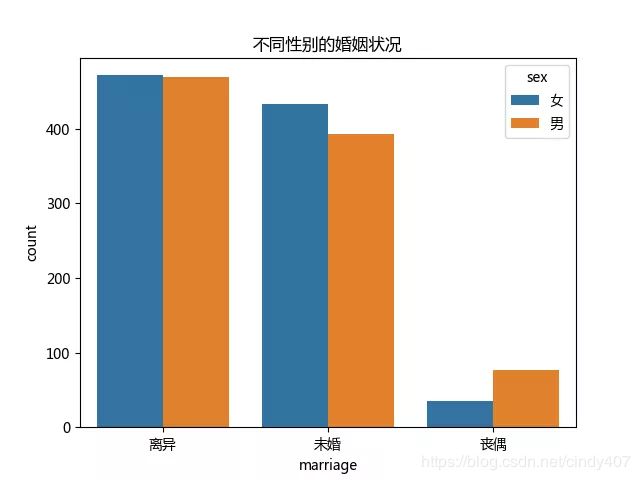
男女性都是离异最多,女性未婚要多于男性,丧偶低于男性。
这个结果是我意料之外的,因为世纪佳缘经常推荐一些年轻的小哥哥们去非诚勿扰,还以为多半以年轻未婚居多呢。
5、经济状况

女性有房占比38%,男性有房占比44%,男女性有房有车的占比均达到31%,说明经济状况还是较好的
6、地域分布情况
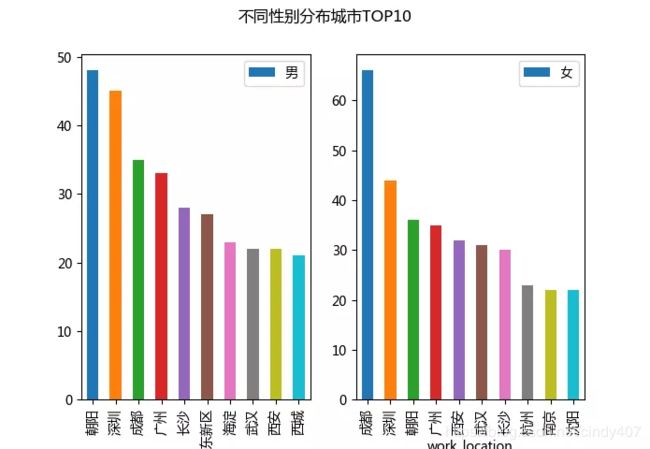
TOP10均是一二线城市,北京、深圳、成都、广州纷纷进入前四强,说明经济较为发达地区,人们对待网上相亲接受成都更高。
二、探索性分析
1、未婚与学历的关系

未婚当中,本科学历占比55%以上,而更高学历的未婚占比较少
三、诉求分析
1、年龄诉求

整体来说呈正相关,希望对方年龄与自己较为匹配,差距不要过大。女性普通希望男性大自己3-5岁,男性则普通希望女性小自己5-10岁
2、身高诉求
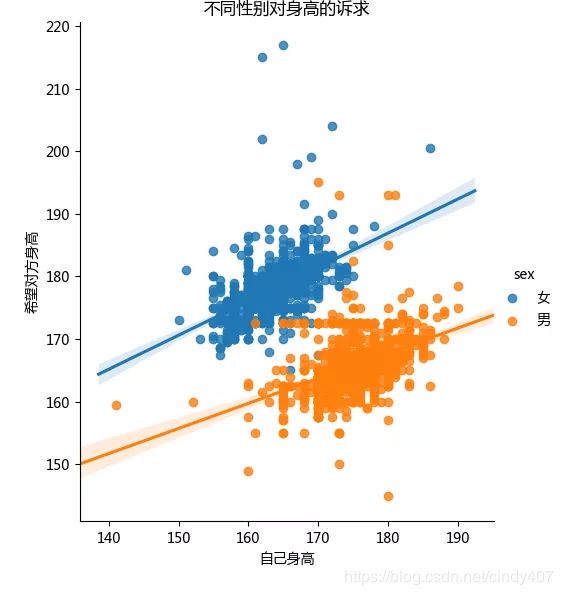
男性对身高要求集中在160-170cm,女性要求集中在173-183cm。整体而言,女性对身高要求要更严苛一些。
3、情感诉求
世纪佳缘网用户可以写短评,内容可以是自我介绍,也可以抒写对对方的期许。通过对短评分词,分别对不同婚姻状况的用户做了词云图,如下:






不管是男性女性,不管是未婚离异丧偶,他们的情感诉求中:品性善良、为人简单、待人真诚、性格合适都是非常重要的几点。
拥抱爱情,走向婚姻是每个人内心的渴望。希望每个人都能找到属于自己的幸福。
本人互联网数据分析师,目前已出Excel,SQL,Pandas,Matplotlib,Seaborn,机器学习,统计学,个性推荐,关联算法,工作总结系列。
福利:
1、关注公众号<数据小斑马>,回复’世纪'即可获得本文全部代码和数据集
2、回复"分析"可以免费获得如下9本数据分析经典书籍电子版
