大数据学习笔记之HBase(三):HBase API使用、HBase与Hive相关、HBase shell
文章目录
- 二十、HBaseAPI的使用
- 20.1、解压Maven离线仓库到指定目录
- 20.2、新建Eclipse的Maven Project,添加pom.xml的dependency如下:
- 20.3、编写HBaseAPI代码
- 二十一、文件格式的说明
- 21.1、tsv格式的文件:字段之间以制表符\t分割
- 21.2、csv格式的文件:字段之间以逗号,分割
- 二十二、HBase的MapReduce的调用
- 22.1、查看HBase执行MapReduce所依赖的Jar包
- 22.2、执行环境变量导入
- 22.3、运行官方的MapReduce任务
- 22.3.1、案例一:统计student表中有多少行数据
- 22.3.2、案例二:使用MapReduce任务将数据从文件中导入到HBase
- 二十三、BulkLoad加载文件到HBase表(推荐)
- 23.1、功能
- 23.2、原理
- 23.3、作用
- 23.4、案例
- 二十四、HBase自定义MapReduce
- 案例1、HBase表数据的转移
- Step1、构建ReadFruitMapper类,用于读取fruit表中的数据
- Step2、构建WriteFruitMRReducer类,用于将读取到的fruit表中的数据写入到fruit_mr表中
- Step3、构建Fruit2FruitMRJob extends Configured implements Tool,用于组装运行Job任务
- Step4、主函数中调用运行该Job任务
- 案例2、将文件中的数据导入到HBase数据表
- Step1、构建Mapper用于读取HDFS中的文件数据
- Step2、构建WriteFruitMRFromTxtReducer类
- Step3、组装Job
- Step4、提交运行Job
- 二十五、HBase与Hive的对比
- 25.1、Hive
- 25.1.1、数据仓库
- 25.1.2、用于数据分析、清洗
- 25.1.3、基于HDFS、MapReduce
- 25.2、HBase
- 25.2.1、数据库
- 25.2.2、用于存储结构化和非结构话的数据
- 25.2.3、基于HDFS
- 25.2.4、延迟较低,接入在线业务使用
- 总结:Hive与HBase
- 二十六、HBase与Hive交互操作
- 26.1、环境准备
- 26.2、案例1:创建Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase
- Step1、在Hive中创建表同时关联HBase
- Step2、在Hive中创建临时中间表,用于load文件中的数据(注:不能将数据直接load进Hive所关联HBase的那张表中)。
- Step3、向Hive中间表中load数据
- Step4、通过insert命令将中间表中的数据导入到Hive关联HBase的那张表中
- Step5、测试,查看Hive以及关联的HBase表中是否已经成功的同步插入了数据
- 26.3、案例2:比如在HBase中已经存储了某一张表hbase_emp_table,然后在Hive中创建一个外部表来关联HBase中的hbase_emp_table这张表,使之可以借助Hive来分析HBase这张表中的数据。
- 小总结
- 二十七、HBase与Sqoop集成
- 27.1、案例:将RDBMS中的数据抽取到HBase中
- 问题
- hive可以关联HBase的多个列族
- mysql需要开启远程权限访问
- RegionServer再分析
- 二十八、HBase中计算存储数据的大小
- 28.1、固定大小 fixed size
- 28.2、可变大小 variable size
- 二十九、HBase Shell
- 29.1、status
- 29.2、whoami
- 29.3、list
- 29.4、count
- 29.5、describe
- 29.6、exist
- 29.7、is_enabled、is_disabled
- 29.8、alter
- 29.9、disable
- 29.10、drop
- 29.11、delete
- 29.11、truncate
- 29.12、create
- 29.13、更多后续拓展
二十、HBaseAPI的使用
20.1、解压Maven离线仓库到指定目录
$ tar -zxf /opt/softwares/hbase+hadoop_repository.tar.gz -C ~/.m2/
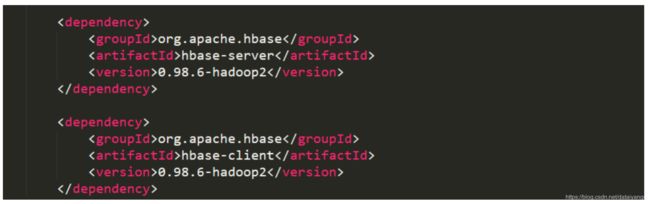
20.2、新建Eclipse的Maven Project,添加pom.xml的dependency如下:
20.3、编写HBaseAPI代码
详见项目代码
package com.z.hbase;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hdfs.server.namenode.decommission_jsp;
public class HBaseDemo {
//创建Hadoop以及HBased管理配置对象
public static Configuration conf;
static{
//使用HBaseConfiguration的单例方法实例化
conf = HBaseConfiguration.create();
}
/**
* 判断表是否已存在
* @param args
* @throws IOException
* @throws ZooKeeperConnectionException
* @throws MasterNotRunningException
*/
public static boolean isTableExist(String tableName) throws MasterNotRunningException, ZooKeeperConnectionException, IOException{
//在HBase中管理、访问表需要先创建HBaseAdmin对象
HBaseAdmin admin = new HBaseAdmin(conf);
//判断表是否存在
return admin.tableExists(tableName);
}
/**
* 创建表
* @param args
* @throws IOException
* @throws ZooKeeperConnectionException
* @throws MasterNotRunningException
*/
public static void createTable(String tableName, String... columnFamily) throws MasterNotRunningException, ZooKeeperConnectionException, IOException{
HBaseAdmin admin = new HBaseAdmin(conf);
//判断表是否存在
if(isTableExist(tableName)){
System.out.println("表" + tableName + "已存在");
//System.exit(0);
}else{
//创建表属性对象,表名需要转字节(valueOf(tableName))
HTableDescriptor descriptor = new HTableDescriptor(TableName.valueOf(tableName));
//创建多个列族
for(String cf : columnFamily){
descriptor.addFamily(new HColumnDescriptor(cf));
}
//根据对表的配置,创建表
admin.createTable(descriptor);
System.out.println("表" + tableName + "创建成功!");
}
}
/**
* 删除表
* @param args
* @throws IOException
* @throws ZooKeeperConnectionException
* @throws MasterNotRunningException
*/
public static void dropTable(String tableName) throws MasterNotRunningException, ZooKeeperConnectionException, IOException{
HBaseAdmin admin = new HBaseAdmin(conf);
if(isTableExist(tableName)){
//删除表之前先要让表变成不可用,之后再删除。
admin.disableTable(tableName);
admin.deleteTable(tableName);
System.out.println("表" + tableName + "删除成功!");
}else{
System.out.println("表" + tableName + "不存在!");
}
}
/**
* 向表中插入数据
* @param tableName
* @param rowKey
* @param columnFamily
* @param column
* @param value
* @throws IOException
*/
public static void addRowData(String tableName, String rowKey, String columnFamily, String column, String value) throws IOException{
//创建HTable对象
HTable hTable = new HTable(conf, tableName);
//向表中插入数据
Put put = new Put(Bytes.toBytes(rowKey));
//向Put对象中组装数据
put.add(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));
//put同样可以插入list,即多条数据
hTable.put(put);
hTable.close();
System.out.println("插入数据成功");
}
/**
* 删除多行数据
* @param tableName
* @param rows rowkey
* @throws IOException
*/
public static void deleteMultiRow(String tableName, String... rows) throws IOException{
HTable hTable = new HTable(conf, tableName);
List<Delete> deleteList = new ArrayList<Delete>();
for(String row : rows){
Delete delete = new Delete(Bytes.toBytes(row));
deleteList.add(delete);
}
hTable.delete(deleteList);
hTable.close();
}
/**
* 得到所有的数据
* @param tableName
* @throws IOException
*/
public static void getAllRows(String tableName) throws IOException{
HTable hTable = new HTable(conf, tableName);
//得到用于扫描region的对象
Scan scan = new Scan();
//使用HTable得到resultcanner实现类的对象
ResultScanner resultScanner = hTable.getScanner(scan);
for(Result result : resultScanner){
//拿到当前这行的内容,内容是存在单元格(cell)中的,一个单元格存储一个数据,若干个数据
//应该用数组表示
Cell[] cells = result.rawCells();
for(Cell cell : cells){
//得到rowkey,CellUtil.cloneRow 将cell转化为字节数组,CellUtil是工具类
System.out.println(Bytes.toString(CellUtil.cloneRow(cell)));
//得到列族
System.out.println(Bytes.toString(CellUtil.cloneFamily(cell)));
//得到列名
System.out.println(Bytes.toString(CellUtil.cloneQualifier(cell)));
//得到列的内容
System.out.println(Bytes.toString(CellUtil.cloneValue(cell)));
}
}
}
public static void main(String[] args) {
try {
// System.out.println(isTableExist("student"));
// createTable("person", "basic_info", "job", "heathy");
// dropTable("person");
// addRowData("person", "1001", "basic_info", "name", "Nick");
// addRowData("person", "1001", "basic_info", "sex", "Male");
// addRowData("person", "1001", "basic_info", "age", "18");
// addRowData("person", "1001", "job", "dept_no", "7981");
// deleteMultiRow("person", "person");
//(deleteMultiRow这里的第二个person不要被误导,第二个参数是rowkey,教程中有名字为person的rowkey,
//这里的rowkey对应于addRowData第二个参数)
getAllRows("person");
} catch (Exception e) {
e.printStackTrace();
}
}
}
二十一、文件格式的说明
21.1、tsv格式的文件:字段之间以制表符\t分割
21.2、csv格式的文件:字段之间以逗号,分割
二十二、HBase的MapReduce的调用
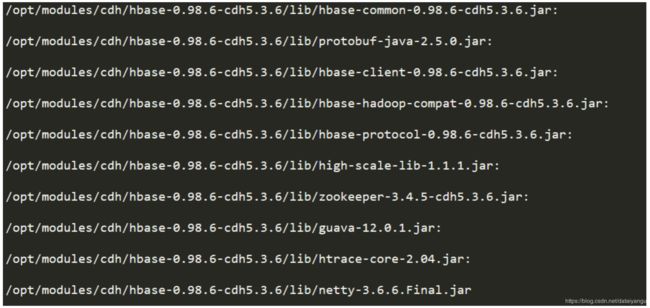
22.1、查看HBase执行MapReduce所依赖的Jar包
执行命令:
$ bin/hbase mapredcp (hbase根目录下)
出现如下内容:
22.2、执行环境变量导入
$ export HBASE_HOME=/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/
$ export HADOOP_HOME=/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6
$ export HADOOP_CLASSPATH=${HBASE_HOME}/bin/hbase mapredcp
22.3、运行官方的MapReduce任务
22.3.1、案例一:统计student表中有多少行数据
- 执行代码
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/yarn jar lib/hbase-server-0.98.6-cdh5.3.6.jar rowcounter student
注意:hbase-server-0.98.6-cdh5.3.6.jar 在hbase的lib目录下,上面的命令根据实际的目录做相应的更改,后者在hbase的根目录下再执行
hbase-server-0.98.6-cdh5.3.6.jar是官方提供的一个实例的jar

22.3.2、案例二:使用MapReduce任务将数据从文件中导入到HBase

将tsv文件上传到HDFS,这个数据最终会存在HBase的region中,region维护了很多的hfile,HBase中没有其他的数据类型,全是字节数组,把HDFS中的数据转换成bytes,写入到Hlog中,写完之后再接入到内存中,最后再写入到region中
Step1、创建一个tsv格式的文件
$ vi fruit.tsv,内容如下:

Step2、创建HBase表
$ bin/hbase shell
hbase(main):001:0> create ‘fruit’,‘info’
Step3、在HDFS中创建input_fruit文件夹并上传fruit.tsv文件
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -mkdir /input_fruit/
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put fruit.tsv /input_fruit/

Step4、执行MapReduce到HBase的fruit表中
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/yarn jar lib/hbase-server-0.98.6-cdh5.3.6.jar
importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color fruit
hdfs://hadoop-senior01.itguigu.com:8020/input_fruit
如果是导入csv格式的话importtsv这个命令改成importcsv
info:name,info:color fruit 列族 列 表名
hdfs://hadoop-senior01.itguigu.com:8020/input_fruit 指定文件在哪里
注意:导入HBase数据必须通过MapReduce

Step5、使用scan命令查看导入后的数据即可

二十三、BulkLoad加载文件到HBase表(推荐)
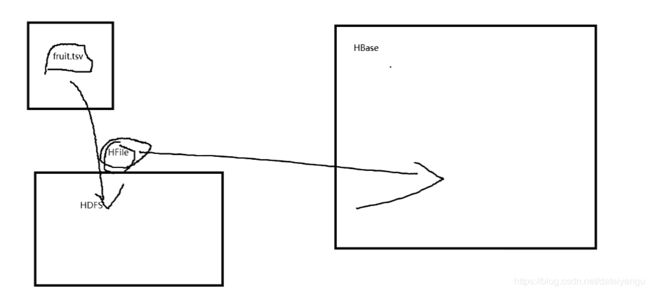
tsv文件导入到HDFS上的时候,直接放到Hfile中,HBase只需要将已经转好的Hfile文件关联到原数据里面就可以了,这样就可以专门开几个进程将可视化的tsv转化为不可视化的Hfile,然后HBase不停的将转换好的数据进行关联就好了,这样可以加快HBase转换的速度,减小压力
23.1、功能
将本地数据导入到HBase中
23.2、原理
BulkLoad会将tsv/csv格式的文件编程hfile文件,然后再进行数据的导入,这样可以避免大量数据导入时造成的集群写入压力过大。
23.3、作用
- 减小HBase集群插入数据的压力
- 提高了Job运行的速度,降低了Job执行时间
23.4、案例
Step1、配置临时环境变量
$ export HBASE_HOME=/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/
$ export HADOOP_HOME=/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6
$ export HADOOP_CLASSPATH=${HBASE_HOME}/bin/hbase mapredcp
Step2、创建一个新的HBase表
$ bin/hbase shell
hbase(main):001:0> create ‘fruit_bulkload’,‘info’
Step3、将tsv/csv文件转化为HFile (别忘了要确保你的fruit格式的文件fruit.tsv在input目录下)
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/yarn jar \
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/hbase-server-0.98.6-cdh5.3.6.jar importtsv \
-Dimporttsv.bulk.output=/output_file \
-Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color \
fruit hdfs://hadoop-senior01.itguigu.com:8020/input_fruit
-Dimporttsv.bulk.output=/output_file \ 这句话的意思是输出的类型是Bulk,把fruit.tsv这样的文件转换成HFile的时候输出的路径是哪里
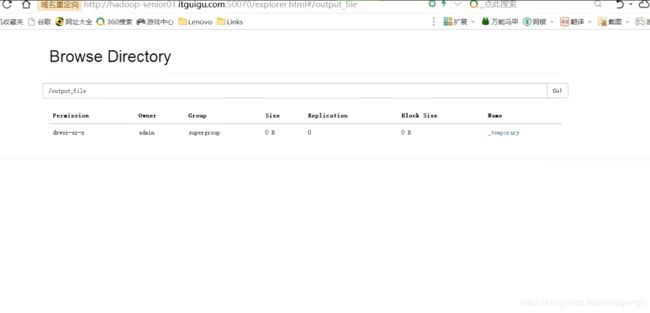
这是是temprary,因为任务还在执行
等任务执行完了之后,就能看到这个文件了,这是一个字节码的文件
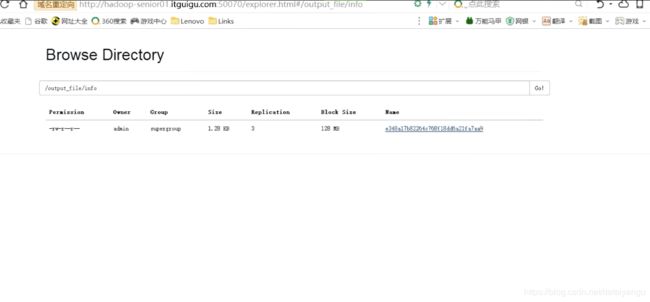
Step4、把HFile导入到HBase表fruit_bulkload
上一步完成之后,你会发现在HDFS的根目录下出现了一个output_file文件夹,里面存放的就是HFile文件,紧接着:把HFile导入到HBase表fruit_bulkload
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/yarn jar \
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/hbase-server-0.98.6-cdh5.3.6.jar \
completebulkload /output_file fruit_bulkload
completebulkload /output_file fruit_bulkload completebulkload完成导入, /output_file HFile的存储目录,fruit_bulkload存储的那张表。
Step5、查看使用bulkLoad方式导入的数据
hbase(main):001:0> scan ‘fruit_bulkload’

二十四、HBase自定义MapReduce
案例1、HBase表数据的转移
在转移的过程中可以实现什么操作?数据的清洗,还可以只拿某几个列的数据。转移的过程中是可以伴随数据的操作的,清洗、转换都可以
在Hadoop阶段,我们编写的MR任务分别进程了Mapper和Reducer两个类,而在HBase中我们需要继承的是TableMapper和TableReducer两个类。
目标:将fruit表中的一部分数据,通过MR迁入到fruit_mr表中
Step1、构建ReadFruitMapper类,用于读取fruit表中的数据
package com.z.hbase_mr;
import java.io.IOException;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
//现在是从HBase中读数据
//输出的键和值分别是ImmutableBytesWritable(可写的字节对象),Put
public class ReadFruitMapper extends TableMapper<ImmutableBytesWritable, Put> {
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context)
throws IOException, InterruptedException {
//key.get()拿到了rowkey
Put put = new Put(key.get());
//遍历该rowkey下面的所有单元格
for(Cell cell: value.rawCells()){
//如果当前单元格访问到的数据是info列族,则进行下一步操作
if("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))){
//添加/克隆列:name ,提取name列
if("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {
//将该列cell加入到put对象中
//如果数据需要清洗和转换,则需要取出具体数据,然后重新封装cell
put.add(cell);
//添加/克隆列:color
}else if("color".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){
//向该列cell加入到put对象中
put.add(cell);
}
}
}
//将从fruit读取到的每行数据写入到context中作为map的输出
context.write(key, put);
}
}
Step2、构建WriteFruitMRReducer类,用于将读取到的fruit表中的数据写入到fruit_mr表中
package com.z.hbase_mr;
import java.io.IOException;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
//ImmutableBytesWritable, Put对接前面mapper的输出
//NullWritable不需要输出任何内容
public class WriteFruitMRReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context)
throws IOException, InterruptedException {
//读出来的每一行数据写入到fruit_mr表中
for(Put put: values){
context.write(NullWritable.get(), put);
}
}
}
Step3、构建Fruit2FruitMRJob extends Configured implements Tool,用于组装运行Job任务
public class Fruit2FruitMRJob extends Configured implements Tool{
//组装Job
public int run(String[] args) throws Exception {
//得到Configuration
Configuration conf = this.getConf();
//创建Job任务
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
//当前的类
job.setJarByClass(Fruit2FruitMRJob.class);
//配置Job
Scan scan = new Scan();
//下面这两个不设置是完全没有影响的
//扫描的时候是否需要缓存
scan.setCacheBlocks(false);
//扫描的时候缓存的行数
scan.setCaching(500);
//设置Mapper,注意导入的是mapreduce包下的,不是mapred包下的,后者是老版本
TableMapReduceUtil.initTableMapperJob(
"fruit", //数据源的表名,mapper操作的表名
scan, //scan扫描控制器
ReadFruitMapper.class,//设置Mapper类
ImmutableBytesWritable.class,//设置Mapper输出key类型
Put.class,//设置Mapper输出value值类型
job//设置给哪个JOB
);
//设置Reducer
//fruit_mr要输出到哪张表
TableMapReduceUtil.initTableReducerJob("fruit_mr", WriteFruitMRReducer.class, job);
//设置Reduce数量,最少1个
job.setNumReduceTasks(1);
//把结果等待返回,要通过返回的值退出系统
boolean isSuccess = job.waitForCompletion(true);
if(!isSuccess){
throw new IOException("Job running with error");
}
return isSuccess ? 0 : 1;
}
}
Step4、主函数中调用运行该Job任务
//还在刚才的类中写main函数
public class Fruit2FruitMRJob extends Configured implements Tool{
public static void main( String[] args ) throws Exception{
Configuration conf = HBaseConfiguration.create();
//拿到任务最后的状态码
int status = ToolRunner.run(conf, new Fruit2FruitMRJob(), args);
System.exit(status);
}
}
在mapreduce的任务执行之前,执行一下创建表的操作
然后执行上面MapReduce中的操作
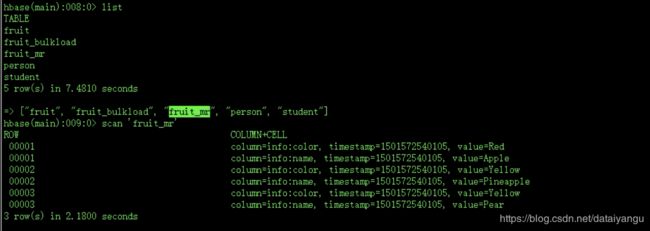
成功的将fruit表中的数据放到了fruit_mr表中
案例2、将文件中的数据导入到HBase数据表
拓展:
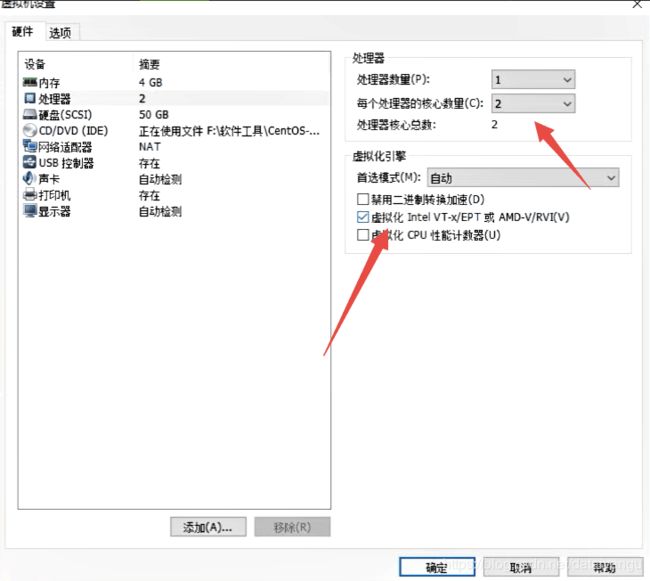
这里设置为多核,并且勾选下面的虚拟化,能够明显的提升虚拟机的运行速度。
其实该案例的思想和案例1没有太大不同,思路总体还是一样的,只不过这次Mapper不是从HBase的表里读取数据了,而是从HDFS上的文件中读取数据,所以Mapper可直接继承自HDFS的Mapper。
将HDFS上结构化或者非结构化的数据导入到HBase上,因为可以再MapReduce上灵活的处理非结构化的数据
Step1、构建Mapper用于读取HDFS中的文件数据
package com.z.hbase.mr2;
import java.io.IOException;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//这个mapper是从hdfs中读取数据
//ImmutableBytesWritable可以理解为rowkey,Put可以理解为列族、列、单元格
//根据rowkey,把put代表的列族、列、单元格归并到一起
public class ReadFruitFromHDFSMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//从HDFS中读取的数据
String lineValue = value.toString();
//读取出来的每行数据使用\t进行分割,存于String数组
String[] values = lineValue.split("\t");
//根据数据中值的含义取值
//收取字段数据
// 00001
//apple
//red
//00002 bannana yellow
String rowKey = values[0];
String name = values[1];
String color = values[2];
//初始化rowKey
//创建rowkey对象
ImmutableBytesWritable rowKeyWritable = new ImmutableBytesWritable(Bytes.toBytes(rowKey));
//初始化put对象
//创建cell对象,组装cell
Put put = new Put(Bytes.toBytes(rowKey));
//参数分别:列族、列、值
put.add(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(name));
put.add(Bytes.toBytes("info"), Bytes.toBytes("color"), Bytes.toBytes(color));
context.write(rowKeyWritable, put);
}
}
Step2、构建WriteFruitMRFromTxtReducer类
package com.z.hbase.mr2;
import java.io.IOException;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
public class WriteFruitMRFromTxtReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
//读出来的每一行数据写入到fruit_hdfs表中
for(Put put: values){
//注意这里的put不一定要全部写进去,
//0002
//banana
//yellow
//这样的不是再一行上面的数据,不能通过这种方式
//可以通过如果一行中不是三个数据的话,就拿一个数据
//然后缓存下来,知道组装成一条完整的数据,具体情况具体分析
context.write(NullWritable.get(), put);
}
}
}
Step3、组装Job
public classHDFS2HBaseDriver extends Configured implements Tool{
public int run(String[] args) throws Exception {
//得到Configuration
Configuration conf = this.getConf();
//创建Job任务
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(HDFS2HBaseDriver.class);
// Path inPath = new Path("/input/fruit.txt");
//输入的路径
Path inPath = new Path("hdfs://hadoop-senior01.itguigu.com:8020/input_fruit/fruit.tsv");
//FileInoutStream导包FileInput- org.apache.hadoop.mapreduce.lib.input不要导错了
FileInputFormat.addInputPath(job, inPath);
//设置Mapper
job.setMapperClass(ReadFruitFromHDFSMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
//设置Reducer
//fruit_hdfs输出的表
TableMapReduceUtil.initTableReducerJob("fruit_hdfs", WriteFruitMRFromTxtReducer.class, job);
//设置Reduce数量,最少1个
job.setNumReduceTasks(1);
boolean isSuccess = job.waitForCompletion(true);
if(!isSuccess){
throw new IOException("Job running with error");
}
return isSuccess ? 0 : 1;
}
}
Step4、提交运行Job
public classHDFS2HBaseDriver extends Configured implements Tool{
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
int status = ToolRunner.run(conf, new HDFS2HBaseDriver(), args);
System.exit(status);
}
}
运行之前不要忘了创建表

执行MapReduce之后

二十五、HBase与Hive的对比
25.1、Hive
25.1.1、数据仓库
Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
25.1.2、用于数据分析、清洗
Hive适用于离线的数据分析和清洗,延迟较高
25.1.3、基于HDFS、MapReduce
Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。(不要钻不需要执行MapReduce代码的情况的牛角尖)
25.2、HBase
25.2.1、数据库
是一种面向列存储的非关系型数据库。
25.2.2、用于存储结构化和非结构话的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
适合菲关系型的比如
0001
apple
red
如果是hive就会当做脏数据扔掉,hbase会进行处理
25.2.3、基于HDFS
数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理。
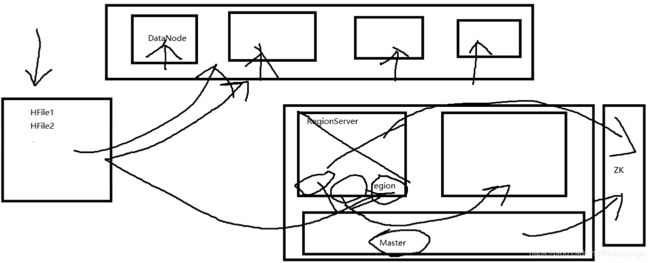
这里注意RegionServer维护的是region,这个region到底是什么东西?是一个概念,是不存在的东西,是逻辑上的东西,region可以理解为一个对象,这个对象管理了一些实际的东西,比如说数据的分发,比如说实际数据的存储,而不是真正存储的。那么region管理的是谁呢?region管理的是DataNode上的Hfile文件,他只是个管理者,regoin又被RegionServer管理,也就是说hbase的从节点RegionServer节点从来没有真正的存储数据,只是做一个调度、周转操作,真正的存储永远是在DataNode上面,以Hfile的形式体现。这也是为什么RegionServer在崩掉的时候HMaster可以把他负责的那块数据,移到其他的RegionServer上面,加入当前的RegionServer退役了,新的的RegionServer要接管原来的RegionServer的活,需要把实际存储的数据转移过来,如果这样的话,会产生大量的磁盘io,只需要在zookeeper里面改变原数据的字节就行了,RegionServer及region的信息是在zookeeper上面保存着的,HMaster可以拿到并且访问,如果RegionServer退役了,HMaster是会收到消息的,退役之后它原来负责的RegionServer的逻辑,需要转交给新的RegionServer,那怎么转交呢?HMaster把原数据拿过来,告诉RegionServer现在要接管活了,把一系列原数据都给RegionServer,这个过程是很快的,因为原来存放的数据还在DataNode中。这里可能有一个歧义的地方,当前说的RegionServer退役,说的是当前的RegionServer这个服务蹦了,不是说的机器蹦了,如果RegionServer和DataNode在同一个机器上面,当前的机器崩了,那么,就不是上面说的这么简单了。
RegionServer崩了之后,HMaster将RegionServer的元数据,转移给其他的RegionServer的时候,这里的元数据指的是什么?是Hfile具体存在哪个DataNode上面
HDFS和HBase最好部署在同一台机器上,计入HDFS在123机器,HBase在456机器,这样虽然可以,但是这样并不是一个很好的方案,因为会产生大量的网络io。
一般不把HMaster和RegionServer部署在namenode上面,理论上可以,当时经验上来讲这是不合理的。
zookeeper一般都是开单独的机器的,zookeeper跑的时候磁盘io和网络io是非常大的
25.2.4、延迟较低,接入在线业务使用
面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
会定时的把在线的业务抽取到HDFS里面,抽取的多了之后对信息进行一些分析和汇总,但是如果在关系型数据库中进行分析汇总的话,效率会比较低,如果放到HDFS里面,效率很高。
总结:Hive与HBase
Hive和Hbase是两种基于Hadoop的不同技术,Hive是一种类SQL的引擎,并且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL 的Key/vale数据库。这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也可以从Hive写到HBase,或者从HBase写回Hive。
一个是用来做数据存储的,一个是用来做数据分析的,数据的存储和分析可以有交集,至于交集,请看下文。
二十六、HBase与Hive交互操作
26.1、环境准备
因为我们后续可能会在操作Hive的同时对HBase也会产生影响,所以Hive需要持有操作HBase的Jar,那么接下来拷贝Hive所依赖的Jar包(或者使用软连接的形式)。
$ export HBASE_HOME=/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/
$ export HIVE_HOME=/opt/modules/cdh/hive-0.13.1-cdh5.3.6/
$ ln -s $HBASE_HOME/lib/hbase-common-0.98.6-cdh5.3.6.jar $HIVE_HOME/lib/hbase-common-0.98.6-cdh5.3.6.jar
$ ln -s $HBASE_HOME/lib/hbase-server-0.98.6-cdh5.3.6.jar $HIVE_HOME/lib/hbase-server-0.98.6-cdh5.3.6.jar
$ ln -s $HBASE_HOME/lib/hbase-client-0.98.6-cdh5.3.6.jar $HIVE_HOME/lib/hbase-client-0.98.6-cdh5.3.6.jar
$ ln -s $HBASE_HOME/lib/hbase-protocol-0.98.6-cdh5.3.6.jar $HIVE_HOME/lib/hbase-protocol-0.98.6-cdh5.3.6.jar
$ ln -s $HBASE_HOME/lib/hbase-it-0.98.6-cdh5.3.6.jar $HIVE_HOME/lib/hbase-it-0.98.6-cdh5.3.6.jar
$ ln -s $HBASE_HOME/lib/htrace-core-2.04.jar $HIVE_HOME/lib/htrace-core-2.04.jar
$ ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-0.98.6-cdh5.3.6.jar $HIVE_HOME/lib/hbase-hadoop2-compat-0.98.6-cdh5.3.6.jar
$ ln -s $HBASE_HOME/lib/hbase-hadoop-compat-0.98.6-cdh5.3.6.jar $HIVE_HOME/lib/hbase-hadoop-compat-0.98.6-cdh5.3.6.jar
$ ln -s $HBASE_HOME/lib/high-scale-lib-1.1.1.jar $HIVE_HOME/lib/high-scale-lib-1.1.1.jar
同时在hive-site.xml中修改zookeeper的属性,如下:

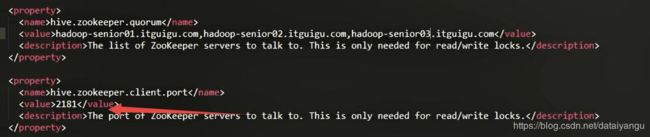
这里就不需要在quorum中配置端口了,因为下面已经配置了
26.2、案例1:创建Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase
给我们直观的感觉是,向hive中导入数据,导入完了之后,hive的仓库中有了,hbase中也有了。
Step1、在Hive中创建表同时关联HBase
//到hive目录下
bin/hive
CREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
//:key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno
//是映射关系,以:开头
//key就是rowkey,对应于hive中员工表的 员工编号empno
//info是列族 info:ename 对应于hive中员工表的 ename列,以此类推,
//注意这两个表的字段的顺序必须一致,如果中间的顺序发生了变化,数据结构就改变了
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
//指定HBase中的表具体是哪一张
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
上面语句中的org.apache.hadoop.hive.hbase.HBaseStorageHandle和hbase.columns.mapping直接用就可以了,不要问为什么
(尖叫提示:完成之后,可以分别进入Hive和HBase查看,都生成了对应的表)
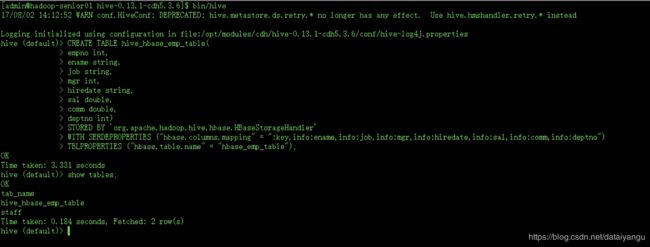
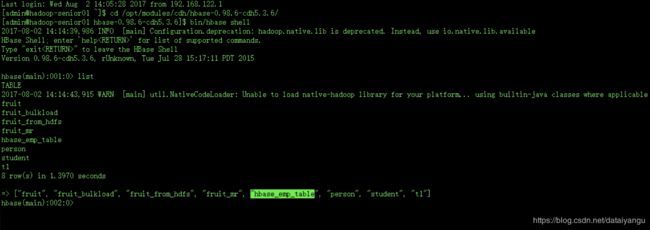 在创建hive那张表的时候,如果关联了Hbase这张表,Hbase这张表就自动创建了,如果之前Hbase的表已经创建了,也是可以关联的。
在创建hive那张表的时候,如果关联了Hbase这张表,Hbase这张表就自动创建了,如果之前Hbase的表已经创建了,也是可以关联的。
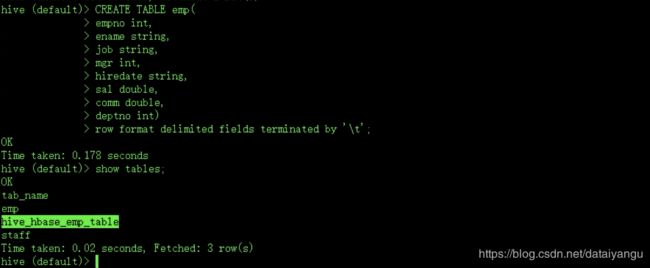
Step2、在Hive中创建临时中间表,用于load文件中的数据(注:不能将数据直接load进Hive所关联HBase的那张表中)。
HDFS中的数据不能直接加入到hive表中,然后直接关联给Hbase,而应该通过load data加入到中间的临时表中,然后临时表通过insert语句插入到hive表中,然后hive仓库会自动把数据关联到HBase上面
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
Step3、向Hive中间表中load数据
hive> load data local inpath ‘/home/admin/Desktop/emp.txt’ into table emp;
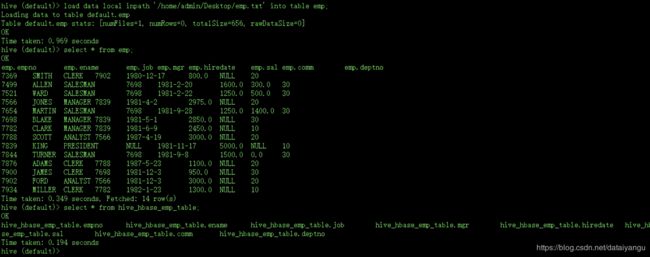

把本地的文件加入到临时表,查看临时表是否加了进去,同时查看hibe_hbase_emp_table中是没有数据的
在HBase中也是没有数据的
Step4、通过insert命令将中间表中的数据导入到Hive关联HBase的那张表中
hive> insert into table hive_hbase_emp_table select * from emp;
Step5、测试,查看Hive以及关联的HBase表中是否已经成功的同步插入了数据
如图所示:
Hive中:
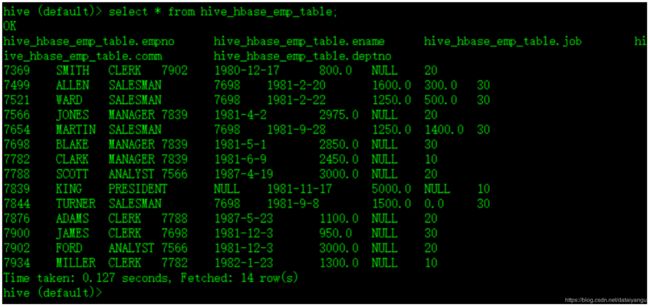
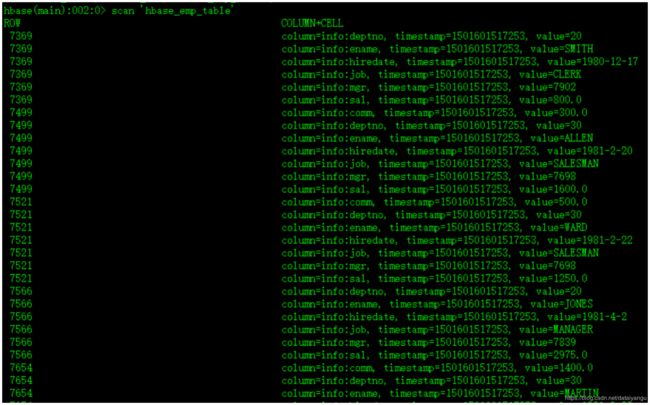
HBase中:
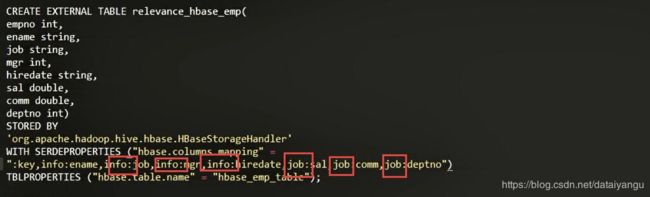
26.3、案例2:比如在HBase中已经存储了某一张表hbase_emp_table,然后在Hive中创建一个外部表来关联HBase中的hbase_emp_table这张表,使之可以借助Hive来分析HBase这张表中的数据。
如果在hbase中已经实现了某一张表,需要对表中的数据进行分析,又不想写MapReduce,让hive关联上这个hbase这个表,就可以直接在hive里面操作数据了。
该案例2紧跟案例1的脚步,所以完成此案例前,请先完成案例1。
Step1、在Hive中创建外部表
//外部表,可以再任何地方,不一定在数据仓库中,外部表在删除的时候是不删除原数据的
//如果是内部表的话,一删,hbase中的数据可能也会被删掉
CREATE EXTERNAL TABLE relevance_hbase_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
//hbase_emp_table要把HBase这张表关联到一张新的表上面。
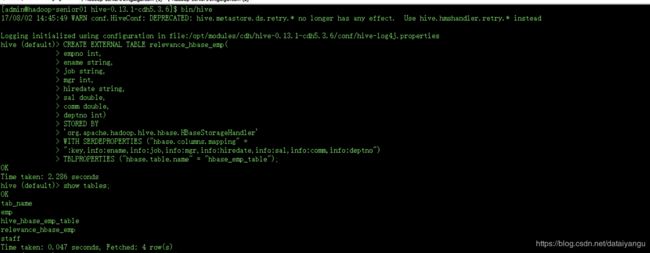
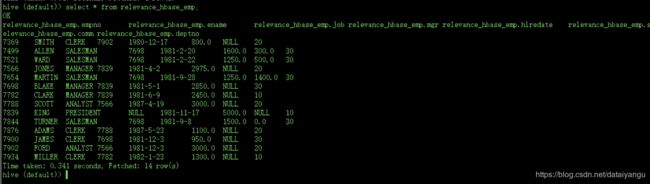
发现HBase表中的数据被关联到hive的这张新表中了
Step2、关联后就可以使用Hive函数进行一些分析操作了
在此,我们查询一下所有数据试试看
hive (default)> select * from relevance_hbase_emp;
小总结
把HDFS中的文件直接关联到hive上面,需要首先在hive中创建一个关联的表,然后导入数据,其实就是做了一个移动,mysql中的映射关系发生了变化,然后就可以通过select name from fruit;在源文件里面查找数据了
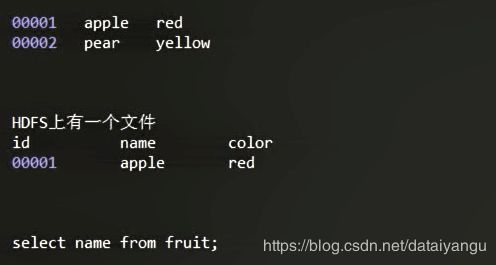
不改变文件的路径,直接通过hive访问HBase中的数据,如何关联
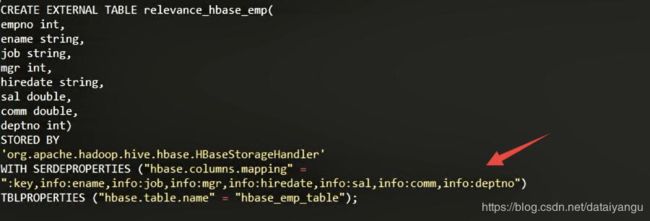
就是这句话
中间为什么要有一个临时表,教程中没有说,老师准备研究下。
二十七、HBase与Sqoop集成
回顾之前Sqoop案例:
1、RDBMS到HDFS的数据导入
场景:就是简单的当做存储、想要先存储到HDFS上,然后通过MapReduce进行数据处理、机房迁移,因为没有存储关系型数据库没有第二台服务器可用,中间可以先存储到HDFS上面,
2、RDBMS到Hive的数据导入
场景:数据处理
3、Hive/HDFS到RDBMS的数据导出
场景:把分析完的记过存储到关系型数据库中
今天我们来讨论一下如何使用Sqoop将RDBMS中的数据导入到HBase当中。
27.1、案例:将RDBMS中的数据抽取到HBase中
场景:新浪微博每日、每周、每月的排行热搜,时间频率低的用实时的计算去做,时间频率高的需要汇总的,比如需要统计一个月中的热搜,这个时候如果在关系型数据库中操作的话,会很慢,可以把数据放在HBase中,结合HBase的特性,结合Hive做一个离线分析。HBase访问亿万级的数据是很快的,而且性能高,容灾性强。
Step1、配置sqoop-env.sh如下:

配置之前没有配置的HBASE_HOME
ZOOCFGDIR,刚开始配置的是zookeeper的绝对目录,然后报错zookeeper home没有配置,所以在下面配置上zookeeper home,然后ZOOCFGDIR根据注释的描述,应该加上conf目录
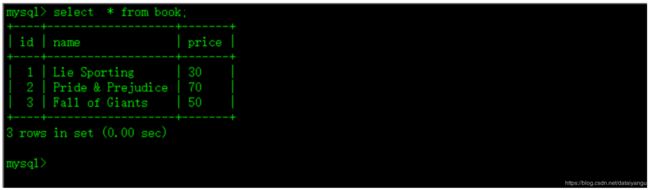
Step2、在Mysql中创建一张数据库library,一张表book
规律:凡是外面的数据进入到集群里面,都会自动创建表,集群里面的东西到外面,都需要自己创建数据库的
CREATE DATABASE library;
CREATE TABLE book(
id int(4) PRIMARY KEY NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
price VARCHAR(255) NOT NULL);
Step3、向表中插入一些数据
INSERT INTO book(name, price) VALUES('Lie Sporting', '30');
INSERT INTO book (name, price) VALUES('Pride & Prejudice', '70');
INSERT INTO book (name, price) VALUES('Fall of Giants', '50');
完成后如图:
Step4、执行Sqoop导入数据的操作
//RDMS到Hbase
$ bin/sqoop import \
--connect jdbc:mysql://hadoop-senior01.itguigu.com:3306/db_library \
--username root \
--password 123456 \
--table book \
--columns "id,name,price" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_book" \
--num-mappers 1 \
--split-by id
注意用sqoop的前提是RDMS关系型数据库的表中有唯一的表示能够当rowkey
到sqoop对应的目录下执行
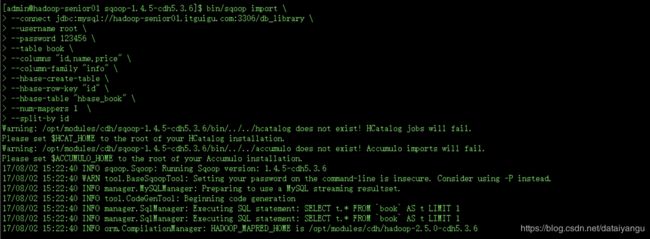
通过网页查看是否完成
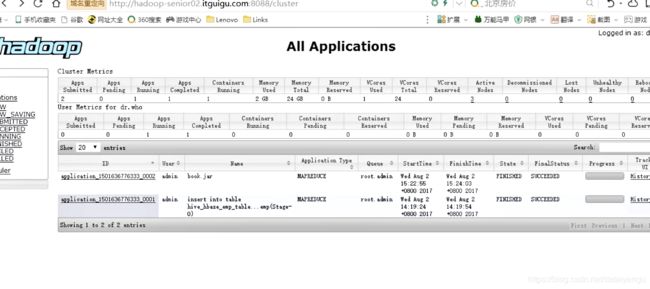
Step5、在HBase中scan这张表得到如下内容
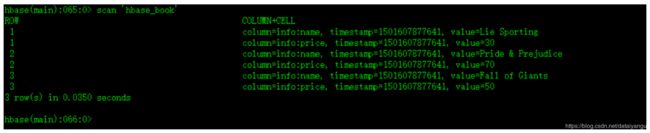
(尖叫提示:在导入之前,HBase中的表如果不存在则会自动创建)
问题
hive可以关联HBase的多个列族
mysql需要开启远程权限访问
如果没有开启的话,加入现在在第二台机器的DataNode访问mysql,然后失败了,这个时候在尝试第三台,还是失败了,然后又会尝试第一台,和mysql在同一台机器上,所以成功了,但是不会无限的尝试

虽然最终成功了,但是在MapReduce页面是有失败记录的,下图中没有失败的记录,因为这只是举个栗子,没有进行实践

RegionServer再分析
为什么需要HMaster,因为需要对RegionServer进行负载均衡,为什么需要负载均衡?因为RegionServer“很累“,为什么它”很累“?如上图
上图中第一个RegionServer崩了,HMaster将第一个维护的region给了第二个,原来维护的数据在第一个的DataNode上,HMaster将region负载给了第二个,hfile是不是也要移到第二个的datenode上面呢?肯定不是吖,这样的话集群压力太大了,下次客户端访问region的时候,只需要region提供Hfile所存储的DataNode在哪里就可以了。
之前的RegionServer是有切分region的功能的,现在负载到第二台机器上面,还怎么负载?第二台要去切数据,会不会产生大量的网络io?HDFS不能直接改变原数据的内容,要想且数据,就生成两个,这里所说的切是region,不是切Hfile, 一个reion是逻辑上的概念,包含很多的hfile,他这个切其实是在逻辑上进行了一个划分,原数据肯定也会变动,region很大。
这里所说的切不是切Hfile,是region,切region,就意味着切存储在regoin中的原数据,即指向DataNode上的Hfile的指针
二十八、HBase中计算存储数据的大小
28.1、固定大小 fixed size
即,当前表设计时,预算的字段名所占用的空间,比如:
RowKey:6个字节
Value:4个字节
TimeStamp:9个字节
KeyType:1个字节
CF:1个字节
那么固定大小fixed size = 6 + 4 + 9 + 1 + 1 = 21字节
当然这只是一个近似估计。
28.2、可变大小 variable size
即,存入的数据的具体指可能会产生波动,比如全世界人类表,俄罗斯的人名比较长,从早上读到晚上都没有念完,中国人名短,这就造成了存入的数据可能是一个可变的大小。
那么总的数据量估算就是:total = fixed size + variable size
二十九、HBase Shell
29.1、status
例如:显示服务器状态
hbase> status ‘hadoop-senior01.itguigu.com’
29.2、whoami
显示HBase当前用户,例如:
hbase> whoami
这个命令的作用,比如HBase对某张表设置了权限了,访问不了,这个时候我想知道我是谁,为什么我访问不了。
![]()
29.3、list
显示当前所有的表
29.4、count
统计指定表的记录数,例如:
hbase> count ‘hbase_book’
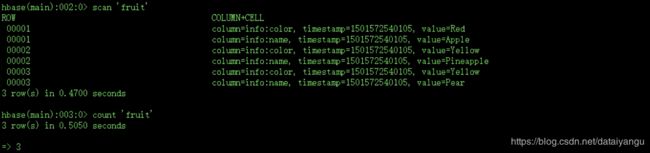
有几个rowkey,就有几条数据,count的值就是几,并不是scan命令有几行就有几条数据
29.5、describe
展示表结构信息
29.6、exist
检查表是否存在,适用于表量特别多的情况

29.7、is_enabled、is_disabled
检查表是否启用或禁用

29.8、alter
该命令可以改变表和列族的模式,例如:
为当前表增加列族:
hbase> alter ‘hbase_book’, NAME => ‘CF2’, VERSIONS => 2
VERSIONS => 2是版本号
为当前表删除列族:
hbase> alter ‘hbase_book’, ‘delete’ => ’CF2’

还有另一种写法

29.9、disable
禁用一张表
29.10、drop
删除一张表,记得在删除表之前必须先禁用(disable)
29.11、delete
删除一行中一个单元格的值,例如:
hbase> delete ‘hbase_book’, ‘rowKey’, ‘CF:C’
需要制定roekwy 列族 列
29.11、truncate
清除表
具体:
禁用表-删除表-创建表
29.12、create
创建表,例如:
hbase> create ‘table’, ‘cf’
创建多个列族:
hbase> create ‘t1’, {NAME => ‘f1’}, {NAME => ‘f2’}, {NAME => ‘f3’}