大数据学习笔记之HBase(六):HBase表类型的设计、预分区、rowkey的设计技巧
文章目录
- 三十八、HBase表类型的设计
- 38.1、短宽
- 38.2、高瘦
- 38.3、短宽-高瘦的对比
- 38.3.1、短宽
- 38.3.2、高瘦
- 三十九、HBase的预分区
- 39.1、为何要预分区?
- 39.2、如何预分区?
- 39.3、如何设定预分区?
- 39.3.1、手动指定预分区
- 39.3.2、使用16进制算法生成预分区
- 39.3.3、分区规则创建于文件中
- 39.3.4、使用JavaAPI创建预分区
- 四十、HBase的rowKey设计技巧
- 40.1、设计宗旨与目标
- 40.2、设计方式案例
- 40.2.1、案例一:生成随机数、hash、散列值
- 40.2.2、案例二:字符串反转
- 40.2.3、案例三:字符串拼接
三十八、HBase表类型的设计
38.1、短宽
这种设计一般适用于:
- 有大量的列
- 有很少的行
38.2、高瘦
这种设计一般适用于:
- 有很少的列
- 有大量的行
38.3、短宽-高瘦的对比
38.3.1、短宽
- 使用列名进行查询不会跳过行或者存储文件
- 更好的原子性
- 不如高瘦设计的可扩展性
38.3.2、高瘦
如果使用列名进行查询,建议使用高瘦的,不然会跳行的。
- 如果使用ID进行查询,会跳过行
- 不利于原子性
- 更好的扩展
为什么有更好的扩展?后面再增加列也没有问题,数据压缩也会更高效一点
建议大部分情况下用高瘦的,大部分都能满足需求。
三十九、HBase的预分区
39.1、为何要预分区?
- 增加数据读写效率
- 负载均衡,防止数据倾斜
- 方便集群容灾调度region
- 优化Map数量
在地球上查找附近的人,GeoHash算法,把地球撕开,近似看成一个矩形,查找附近一千米以内的人,已经知道了自己的经纬度,通过地球的经纬度数据库,通过勾股定理找到直线距离是一千米以内的,这样找到都设么时候了?
怎样优化一下呢?
将地球进行分区,每一个网格都是有一定位数的十六进制编码,想找这个点附近一千米以内的人,指向找到某一个网格内所有的点,在这个网格内用球面的Geo定力。
可以把这个思想用到HBase上面
如果没有分区的话,可能会出现数据倾斜,什么叫做数据倾斜
假如目前有一个region,然后往里面存入数据,假如往后面存的数据都是热点数据,就会导致,最开始的region很“闲”,后面产生的region很“累”
39.2、如何预分区?
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。
startkey,endkey,当前维护的rowkey的范围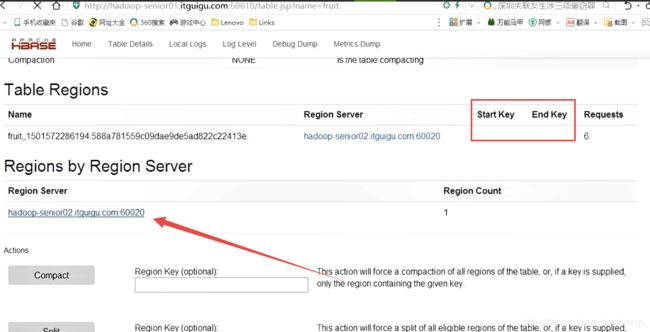
点进去查看RegionServer
39.3、如何设定预分区?
39.3.1、手动指定预分区
create ‘staff’,‘info’,‘partition1’,SPLITS => [‘1000’,‘2000’,‘3000’,‘4000’]
partition1分区1
假如现在rowkey是数字类型的[‘1000’,‘2000’,‘3000’,‘4000’]
完成后如图:
点进去
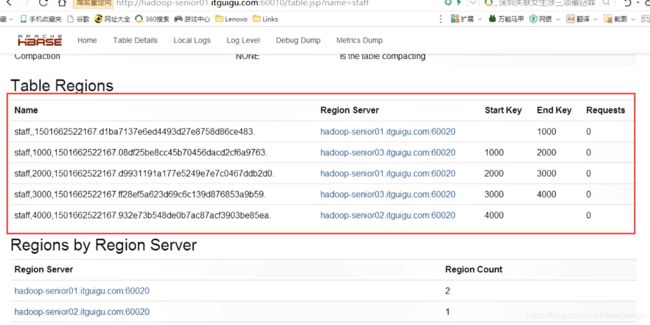
上图中的Region Server的意思是当前的region是哪个RegionServer在维护,在没有数据的时候就已经设计出了这样的“架构图”,在数据产生的时候,就会根据rowkey放在对应的RegionServer上维护,比如现在rowkey是2005,就会落在第三个RegionServer,如果没有设置这个分区的话就会导致,业务在某一个region里面,然后一直在增加,然后到达某个程度再切分,这样效率就会很低,不如提前切好,这样的话读写都会很快。
有了业务的时候,根据业务设计rowkey,不能将上图中的startkey 和 endkey设计的和rowkey毫无关系,例如上面设计的数字,实际业务是rowkey是“小明”
39.3.2、使用16进制算法生成预分区
create ‘staff2’,‘info’,‘partition2’,{NUMREGIONS => 15, SPLITALGO => ‘HexStringSplit’}
HexStringSplit 自带的函数,十六进制的字符串
完成后如图:
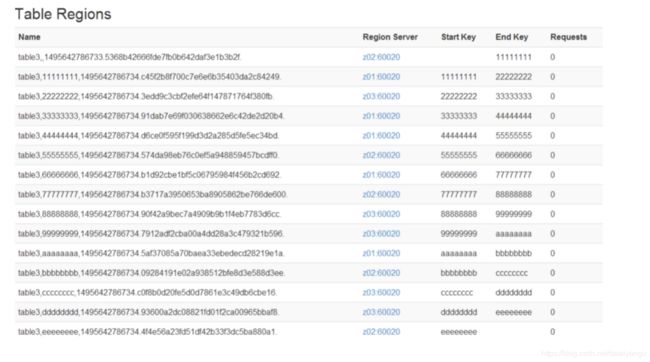
39.3.3、分区规则创建于文件中
创建splits.txt文件内容如下:

然后执行:
create ‘table2’,‘partition2’,SPLITS_FILE => ‘splits.txt’,成功后如图:
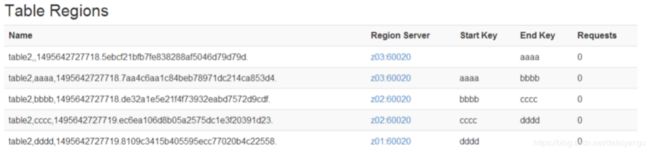
39.3.4、使用JavaAPI创建预分区
Java代码如下:

//自定义算法,产生一系列Hash散列值存储在二维数组中
byte[][] splitKeys = 某个散列值函数
//创建HBaseAdmin实例
HBaseAdmin hAdmin = new HBaseAdmin(HBaseConfiguration.create());
//创建HTableDescriptor实例
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
//通过HTableDescriptor实例和散列值二维数组创建带有预分区的HBase表
hAdmin.createTable(tableDesc, splitKeys);
四十、HBase的rowKey设计技巧
40.1、设计宗旨与目标
主要目的就是针对特定的业务模型,按照rowKey进行预分区设计,使之后面加入的数据能够尽可能的分散于不同的rowKey中。比如复合RowKey。
40.2、设计方式案例
40.2.1、案例一:生成随机数、hash、散列值
比如:
原本rowKey为1001的,MD5后变成:b8c37e33defde51cf91e1e03e51657da
原本rowKey为3001的,MD5后变成:908c9a564a86426585b29f5335b619bc
原本rowKey为5001的,MD5后变成:03b264c595403666634ac75d828439bc
在做此操作之前,一般我们会选择从数据集中抽取样本,来决定什么样的rowKey来Hash后作为每个分区的临界值。
40.2.2、案例二:字符串反转
比如:
20170524000001转成10000042507102
20170524000002转成20000042507102
这样也可以在一定程度上散列逐步put进来的数据。
假如HBase里面存的是按照时间增长的数据,每秒都会有增长,现在按照2017.5.4第一秒开始,每一秒独占一行,假如第一个region的rowkey范围是第1秒到第10000秒,这样就会出现一种现象,在第10000秒之前,数据都是在这个region中的,不会出现在其他的region里面,正常的应该是,第一秒给第一个RegionServer,第二秒给第二个RegionServer,就出现了上面这种,将字符串点颠倒过来,颠倒过来之后,数字的跨度比较大,每一行都会被分到不同的region里面,这样负载就比较均衡。
40.2.3、案例三:字符串拼接
比如:
20170524000001_a12e
20170524000001_93i7
前面是时间戳,后面是hash值,这样不能保证百分之百的散列到不同的region中,但是有一定的随机性。
如果是这种方式,去方位rowkey的时候如何访问?
Get get = new Get(rowkey)
HBase中有一个机制是Filter,就是说可以按照前置匹配的原则找到rowkey,简而言之就是不一样要把长个rowkey匹配到才能找到 这个rowkey, 而是只要前面匹配到了,就可以找到这条数据,也可以后置匹配