SVD全称Singular value decomposition,奇异值分解。线性代数里重要的一种分解形式,其矩阵的特殊含义可以用来做处理线性相关。如在自然语言处理中,对新闻的分类,就可以采用SVD的方法,而且已取得不错的效果。把新闻中的核心词,用一个向量进行表示,每条新闻一个向量,组成一个矩阵,对矩阵进行SVD分解。如:可以用一个大矩阵A来描述这一百万篇文章和五十万词的关联性。这个矩阵中,每一行对应一篇文章,每一列对应一个词。

在上面的图中,M=1,000,000,N=500,000。第 i 行,第 j 列的元素,是字典中第 j 个词在第 i 篇文章中出现的加权词频(比如,TF/IDF)。读者可能已经注意到了,这个矩阵非常大,有一百万乘以五十万,即五千亿个元素。
奇异值分解就是把上面这样一个大矩阵,分解成三个小矩阵相乘,如下图所示。比如把上面的例子中的矩阵分解成一个一百万乘以一百的矩阵X,一个一百乘以一百的矩阵B,和一个一百乘以五十万的矩阵Y。这三个矩阵的元素总数加起来也不过1.5亿,仅仅是原来的三千分之一。相应的存储量和计算量都会小三个数量级以上。

三个矩阵有非常清楚的物理含义:
第一个矩阵X中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大越相关。
第三个矩阵Y中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。
第二个矩阵B则表示类词和文章之间的相关性。因此,我们只要对关联矩阵A进行一次奇异值分解,我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。
特征向量物理意义
我国著名数学家华罗庚曾说过:“数缺形时少直观,形少数时难入微;数形结合百般好,隔离分家万事休”。数学中,数和形是两个最主要的研究对象,它们之间有着十分密切的联系,在一定条件下,数和形之间可以相互转化,相互渗透。 数形结合的基本思想,就是在研究问题的过程中,注意把数和形结合起来考察,斟酌问题的具体情形,把图形性质的问题转化为数量关系的问题,或者把数量关系的问题转化为图形性质的问题,使复杂问题简单化,抽象问题具体化,化难为易,获得简便易行的成功方案。
我们知道,矩阵乘法对应了一个变换,是把任意一个向量变成另一个方向或长度都大多不同的新向量。在这个变换的过程中,原向量主要发生旋转、伸缩的变化。如果矩阵对某一个向量或某些向量只发生伸缩变换,不对这些向量产生旋转的效果,那么这些向量就称为这个矩阵的特征向量,伸缩的比例就是特征值。
来看一个只有两行两列的简单矩阵。第一个例子是对角矩阵:

从几何的角度,矩阵可以描述为一个变换:用矩阵乘法将平面上的点(x, y)变换成另外一个点(3x, y):
这种变换的效果如下:平面在水平方向被拉伸了3倍,在竖直方向无变化。
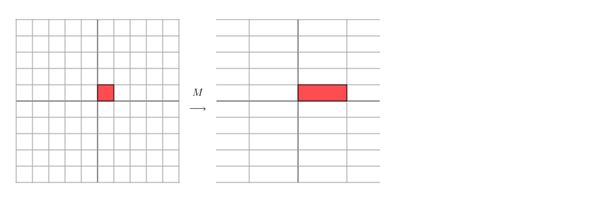
再看下这个矩阵
它会产生如下的效果
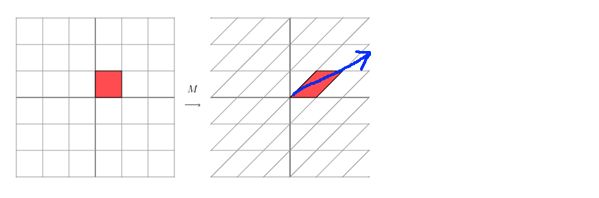
这其实是在平面上对一个轴进行的拉伸变换(如蓝色的箭头所示),在图中,蓝色的箭头是一个最主要的变化方向(变化方向可能有不止一个)。如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。
如果说一个向量v是方阵A的特征向量,这时候λ就被称为特征向量v对应的特征值。
其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。
意义
分解得到的Σ矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)。
也就是说矩阵A的信息可以由其特征值和特征向量表示。
对于矩阵为高维的情况下,那么这个矩阵就是高维空间下的一个线性变换。可以想象,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。
总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
奇异值分解
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有N个学生,每个学生有M科成绩,这样形成的一个N * M的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
假设A是一个N * M的矩阵,那么得到的U是一个N * N的方阵(里面的向量是正交的,U里面的向量称为左奇异向量),Σ是一个N * M的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),V’(V的转置)是一个N * N的矩阵,里面的向量也是正交的,V里面的向量称为右奇异向量),从图片来反映几个相乘的矩阵的大小可得下面的图片
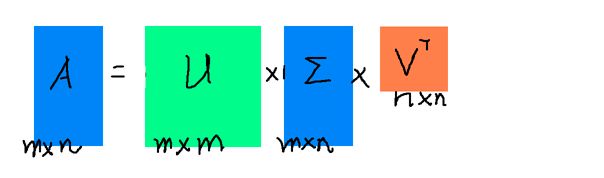
三个矩阵有非常清楚的物理含义。
第一个矩阵X中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大越相关。最后一个矩阵Y中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。中间的矩阵则表示类词和文章雷之间的相关性。因此,我们只要对关联矩阵A进行一次奇异值分解,w 我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。
例子
对物品进行推荐,某些用户买了某些东西,要来算出,物品跟物品之间的相识度,这是很常见的推荐问题,用 SVD 算法,在 python中numpy 的 linalg 可以计算矩阵的 SVD。分解完矩阵就可以用距离算法或者其他,可以求出相识性。
代码如下:





奇异值与潜在语义索引LSI
Latent Semantic Analysis (LSA)也被叫做Latent Semantic Indexing (LSI),从字面上的意思理解就是通过分析文档去发现这些文档中潜在的意思和概念。假设每个词仅表示一个概念,并且每个概念仅仅被一个词所描述,LSA将非常简单(从词到概念存在一个简单的映射关系)
不幸的是,这个问题并没有如此简单,因为存在不同的词表示同一个意思(同义词),一个词表示多个意思,所有这种二义性(多义性)都会混淆概念以至于有时就算是人也很难理解。
潜语义分析(Latent Semantic Analysis)源自问题:如何从搜索query中找到相关的文档。当我们试图通过比较词来找到相关的文本时,存在着难以解决的局限性,那就是在搜索中我们实际想要去比较的不是词,而是隐藏在词之后的意义和概念。潜语义分析试图去解决这个问题,它把词和文档都映射到一个‘概念’空间并在这个空间内进行比较(注:也就是一种降维技术)。
为了让这个难题更好解决,LSA引入一些重要的简化:
文档被表示为”一堆词(bags of words)”,因此词在文档中出现的位置并不重要,只有一个词的出现次数。
概念被表示成经常出现在一起的一些词的某种模式。例如“leash”(栓狗的皮带)、“treat”、“obey”(服从)经常出现在关于训练狗的文档中。
词被认为只有一个意思。这个显然会有反例(bank表示河岸或者金融机构),但是这可以使得问题变得更加容易。(这个简化会有怎样的缺陷呢?)
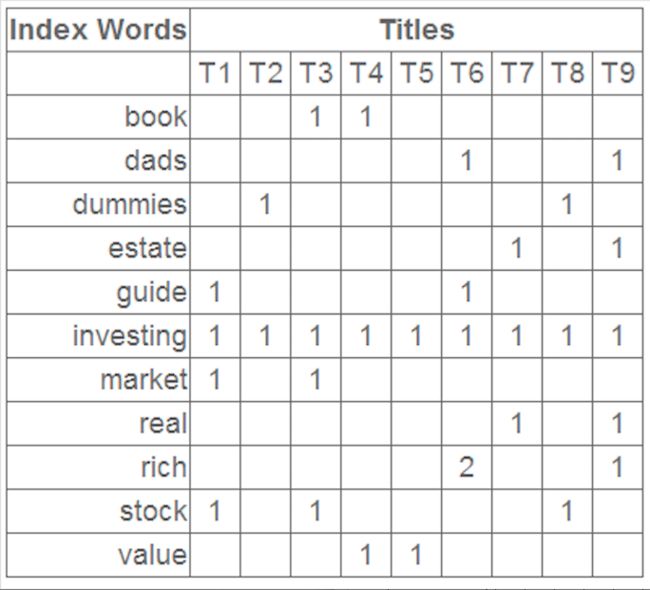
这就是一个矩阵,不过不太一样的是,这里的一行表示一个词在哪些title中出现了(一行就是之前说的一维feature),一列表示一个title中有哪些词,(这个矩阵其实是我们之前说的那种一行是一个sample的形式的一种转置,这个会使得我们的左右奇异向量的意义产生变化,但是不会影响我们计算的过程)。比如说T1这个title中就有guide、investing、market、stock四个词,各出现了一次,我们将这个矩阵进行SVD,得到下面的矩阵:

左奇异向量表示词的一些特性,右奇异向量表示文档的一些特性,中间的奇异值矩阵表示左奇异向量的一行与右奇异向量的一列的重要程序,数字越大越重要。
继续看这个矩阵还可以发现一些有意思的东西,首先,左奇异向量的第一列表示每一个词的出现频繁程度,虽然不是线性的,但是可以认为是一个大概的描述,比如book是0.15对应文档中出现的2次,investing是0.74对应了文档中出现了9次,rich是0.36对应文档中出现了3次;
其次,右奇异向量中一的第一行表示每一篇文档中的出现词的个数的近似,比如说,T6是0.49,出现了5个词,T2是0.22,出现了2个词。
然后我们反过头来看,我们可以将左奇异向量和右奇异向量都取后2维(之前是3维的矩阵),投影到一个平面上,可以得到:
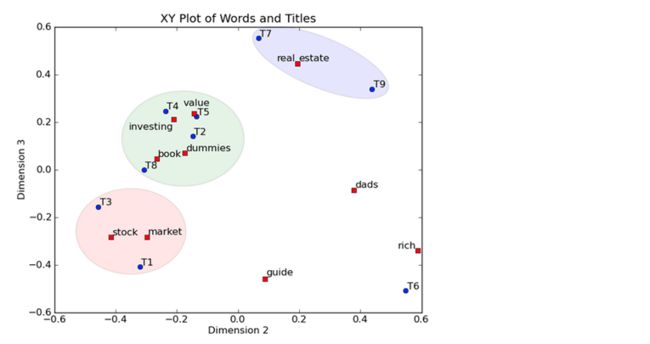
在图上,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一篇文档,这样我们可以对这些词和文档进行聚类,比如说stock 和 market可以放在一类,因为他们老是出现在一起,real和estate可以放在一类,dads,guide这种词就看起来有点孤立了,我们就不对他们进行合并了。按这样聚类出现的效果,可以提取文档集合中的近义词,这样当用户检索文档的时候,是用语义级别(近义词集合)去检索了,而不是之前的词的级别。这样一减少我们的检索、存储量,因为这样压缩的文档集合和PCA是异曲同工的,二可以提高我们的用户体验,用户输入一个词,我们可以在这个词的近义词的集合中去找,这是传统的索引无法做到的。
代码如下:





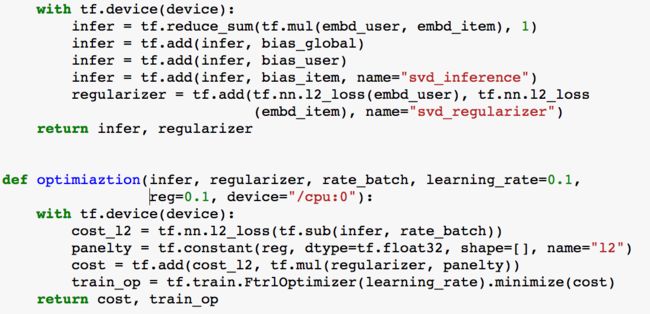
MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS
MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS是一种类似于SVD的推荐算法。它是一种学习算法。
假如要预测Zero君对一部电影M的评分,而手上只有Zero君对若干部电影的评分和风炎君对若干部电影的评分(包含M的评分)。那么能预测出Zero君对M的评分吗?答案显然是能。最简单的方法就是直接将预测分定为平均分。不过这时的准确度就难说了。本文将介绍一种比这个最简单的方法要准上许多,并且也不算复杂的算法。
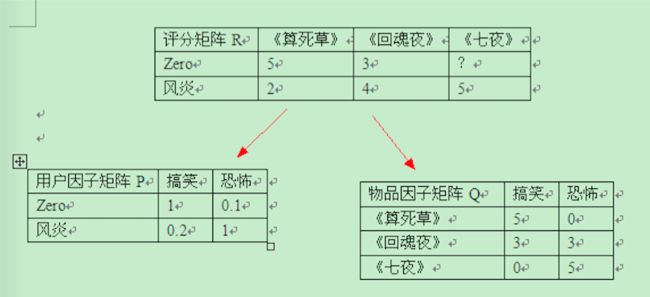
根据已有的评分情况,分析出评分者对各个因子的喜好程度以及电影包含各个因子的程度,最后再反过来根据分析结果预测评分。电影中的因子可以理解成这些东西:电影的搞笑程度,电影的爱情爱得死去活来的程度,电影的恐怖程度。。。。。。SVD的想法抽象点来看就是将一个N行M列的评分矩阵R(R[u][i]代表第u个用户对第i个物品的评分),分解成一个N行F列的用户因子矩阵P(P[u][k]表示用户u对因子k的喜好程度)和一个M行F列的物品因子矩阵Q(Q[i][k]表示第i个物品的因子k的程度)。用公式来表示就是
R = P * T(Q) //T(Q)表示Q矩阵的转置
下面是将评分矩阵R分解成用户因子矩阵P与物品因子矩阵Q的一个例子。R的元素数值越大,表示用户越喜欢这部电影。P的元素数值越大,表示用户越喜欢对应的因子。Q的元素数值越大,表示物品对应的因子程度越高。分解完后,就能利用P,Q来预测Zero君对《七夜》的评分了。按照这个例子来看,Zero君应该会给《七夜》较低的分数。因为他不喜欢恐怖片。注意不要纠结图中的具体数值,因为那些数值是我随便填上去的。
实际上,我们给一部电影评分时,除了考虑电影是否合自己口味外,还会受到自己是否是一个严格的评分者和这部电影已有的评分状况影响。例如:一个严格评分者给的分大多数情况下都比一个宽松评分者的低。你看到这部电影的评分大部分较高时,可能也倾向于给较高的分。在SVD中,口味问题已经有因子来表示了,但是剩下两个还没有相关的式子表示。因此有必要加上相关的部分,提高模型的精准度。改进后的SVD的公式如下: R = OverallMean + biasU + biasI + P * T(Q) (1) 其中OverallMean表示所有电影的平均分,biasU表示用户评分偏离OverallMean的程度,biasI表示电影评分偏离OverallMean的程度,P,Q意思不变。特别注意,这里除了OverallMean之后,其它几个都是矩阵。
这就就是一个最优值优化问题了。
tensorflow 代码如下: