手把手教你利用Python网络爬虫获取APP推广信息
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:Python进阶者
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http://t.cn/A6Zvjdun
CPA之家app推广平台是国内很大的推广平台。该网址的数据信息高达数万条,爬取该网址的信息进行数据的分析。

项目目标
实现将获取到的QQ,导入excel模板,并生成独立的excel文档。
项目分析
反爬措施处理
前期测试时发现,该网站反爬虫处理措施很多,测试到有以下几个:
-
直接使用requests库,在不设置任何header的情况下,网站直接不返回数据。
-
同一个ip连续访问40多次,直接封掉ip,起初我的ip就是这样被封掉的。
为了解决这两个问题,最后经过研究,使用以下方法,可以有效解决。
-
获取正常的 http请求头,并在requests请求时设置这些常规的http请求头。
-
使用 fake_useragent ,产生随机的UserAgent进行访问。
需要的库和网址
1、网址,如下所示:
https://www.cpajia.com/index.php?g=Wap&a=searchua
2、需要用到的库:requests、time、lxml、ua
项目实现
我们定义get_page方法, 准备url地址和请求头headers,导入对应的库。
import requests
import os
import re
from fake_useragent import UserAgent
from lxml import etree
house_dict = {} #定义一个字典
def get_page(url, page_num):
pass
url = 'https://www.cpajia.com/index.php?g=Wap&a=search' #网址
ua = UserAgent(verify_ssl=False) #随机的UserAgent
kv = {
'User-Agent': ua.random}
pageList = get_page()
下面介绍一下如何爬取ajax动态加载的网页方法。
翻页时发现它的url并没有改变,无法简单的通过request.get()访问其他页面。据搜索资料,了解到这些网站是通过ajax动态加载技术实现。即可以在不重新加载整个网页的情况下,对网页的某部分进行更新。

通过分析响应请求,模拟响应参数。再通过requests库的request.post()函数去post相对应的参数即可。
具体方法如下:打开开发者工具,快捷键F12,不行就Fn + F12。
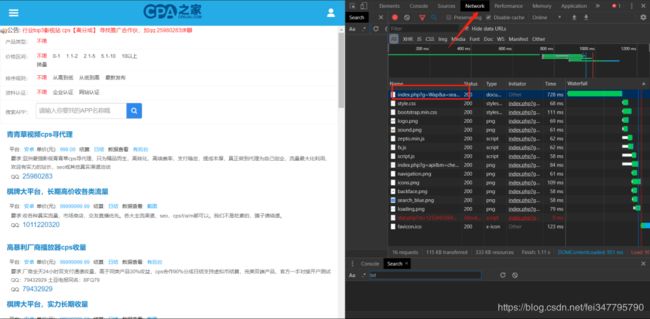
<1>标红的箭头network, 在其中可以看到服务器加载过来的资源。
< 2>标红的框框一个过滤器,你可以按照文件格式筛选。

Headers中的request method 中显示我们使用的是POST方法。而且FROM Data 中有一个参数,PageIndex。
利用Form Data 中的数据,编写一个字典,赋值给requests.post()中的data即可。
接下来就可以正常访问和翻页了!
对网站发生请求
import requests
import os
import re
from fake_useragent import UserAgent
from lxml import etree
def get_page(url, page_num):
pageList = []
for i in range(1, page_num + 1):
formdata = {'PageIndex': i}
ua = UserAgent(verify_ssl=False)
kv = {'User-Agent': ua.random}
pageList = get_page()
对请求到的数据进行处理,具体过程如下所示。
用谷歌浏览器选择开发者工具或者按F12,找到相对应的QQ号的链接。

response = requests.post(url=url, data=formdata, headers=kv)
html = response.content.decode('utf-8')
parse_html = etree.HTML(html)
page = parse_html.xpath('//div[@class="wrap"]//div[@class="list-main"]')
for li in page:
house_dict['项目'] = li.xpath('.//div[@class="main-top"]//b/text()')[0].strip()
house_dict['QQ'] = li.xpath('.// div[ @class ="main-com"]//span//a/text()')[0].strip()
#print(house_dict)
将获取的信息写入excel表格
f = open('QQ号.csv', 'a', encoding='utf-8') # 以'w'方式打开文件
f.write(str(house_dict))
print(house_dict)
f.write("\n")# 键和值分行放,键在单数行,值在双数行
f.close()
注:cvs文件会出现乱码,我们点击文件选择Excel工作薄,后缀名是xlsx;再点保存即可。
输入要爬取的页数
pageList = get_page(url, 100)#页数(网址,页数)
效果展示
点击绿色按钮运行,将结果显示在控制台,如下图所示。输入你要爬取的页数。

打开Excel表格,如下图所示。
