python数据分析pandas包入门学习(四)处理缺失数据
本文参考《利用Python进行数据分析》的第五章 pandas入门
4 处理缺失数据
缺失数据(missing data)在大部分数据分析应用中都很常见。Pandas的设计目标之一就是让缺失数据的处理任务尽量轻松。例如,pandas对象上的所有描述统计都排除了缺失数据。
pandas使用NaN表示缺失数据。

Python内置的None也会被当做NaN处理:
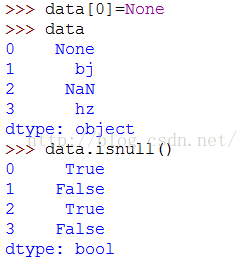

滤除缺失数据
对series,可以使用dropna()方法和布尔型索引达到滤除缺失数据:

对于DataFrame,就有点复杂了,你可能希望丢弃全部是NAN或含有NAN的行或列。
dropna默认丢弃任何含有缺失值的行,传入how='all'则之丢弃全为NaN的行或列:
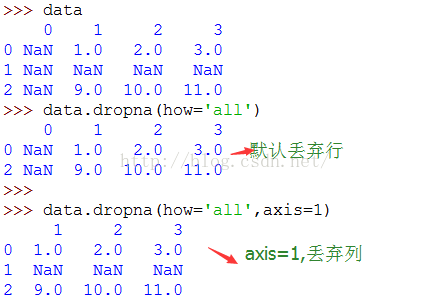
另一个参数是thresh,该参数的类型为整数,它的作用是,比如 thresh=3,会在一行中至少有 3 个
非 NA 值时将其保留。

填充缺失数据
有的时候可能不想滤除缺失数据,而是希望通过其他方式填补那些“空洞”。对于大多数情况,fillna方法是最主要的函数:



