【飞桨】Python小白逆袭大神 心得
目录
主要学习内容:
问题解决:
Day1:
Day2:
Day3:
Day4:
Day5:
持续更新中……
课程链接(Python小白逆袭大神)
主要学习内容:
Day1:人像漫画、视频内容分析、文本纠错、短语言识别;统计文件名
Day2:获取《青春有你2》成员剧照
Day3:《青春有你2》小姐姐单人助力榜单揭秘
Day4:自制数据集,利用PaddleHub 颜值打分
Day5:《青春有你2》评论调取、词频统计、绘制词云;自制数据集、利用PaddleHub进行评论情感分析
问题解决:
Day1:
递归遍历目录及其子目录可用 os.walk(),若要查找一个“特定名称文件”,代码如下:
#导入OS模块
import os
#待搜索的目录路径
path = "Day1-homework"
#待搜索的名称
filename = "2020"
#定义保存结果的数组
result = []
def findfiles():
#三个参数:分别返回1.父目录 2.所有文件夹名字(不含路径) 3.所有文件名字
for parent,dirnames,filenames in os.walk(path):
for f in filenames:
#print(os.path.abspath(os.path.join(parent,f))) #绝对路径,输出文件信息
if f.find(filename)!= -1:
file_path = os.path.join(parent,f)
result.append(file_path)
for i in range(len(result)): #路径输出
print(i+1,result[i])
if __name__ == '__main__':
findfiles()人像动漫化
Day2:
爬虫很关键的点,就是要找到正确的标签。
青春有你第二季
访问某个学员的页面(刘亚楠),移动到“图册”右键单击“检查”。

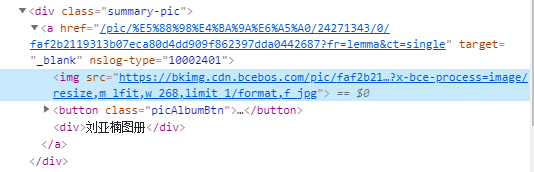
div.summary-pic > a,要获取a标签下的“href”,再访问二级页面(如下图)

上图可以看到有2张图片,都需要获取。
右侧“右键”检查:
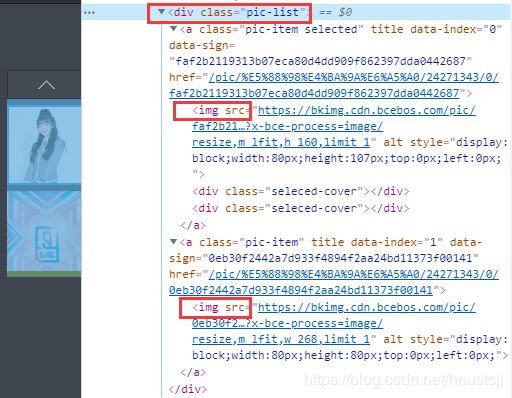
div.pic-list > a > img,获取“src”。
然后写一写代码就可以下载图片啦!!(用BeautifulSoup的select就可)
测试一个小姐姐的图片获取:
#单个调试
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
name = "刘亚楠"
link = 'https://baike.baidu.com/item/%E5%88%98%E4%BA%9A%E6%A5%A0/24271343'
response = requests.get(link ,headers=headers)
print(response.status_code)
soup = BeautifulSoup(response.text,'lxml')
#result = soup.find_all('div',class_ = 'summary-pic')
results = soup.select('div.summary-pic > a ')
print(len(results))
base_url = 'https://baike.baidu.com'
for r in results:
target = base_url + r['href']
print(target)
res1 = requests.get(target, headers = headers)
soup1 = BeautifulSoup(res1.text,'lxml')
rs = soup1.select('div.pic-list > a > img')
i = 0
for r1 in rs:
pic_url = r1['src']
print(pic_url)
#pic = requests.get(pic_url)
pic = requests.get(pic_url, timeout=15)
path = 'work/'
string = str(i + 1) + '.jpg'
with open(path + string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
i += 1运行如下(显示部分):
成功下载第1张图片: https://bkimg.cdn.bcebos.com/pic/faf2b2119313b07eca80d4dd909f862397dda0442687?x-bce-process=image/resize,m_lfit,h_160,limit_1 成功下载第2张图片: https://bkimg.cdn.bcebos.com/pic/0eb30f2442a7d933f4894f2aa24bd11373f00141?x-bce-process=image/resize,m_lfit,w_268,limit_1
去掉最后一个“/”及之后的字符,可得到高清图~
url = 'https://bkimg.cdn.bcebos.com/pic/faf2b2119313b07eca80d4dd909f862397dda0442687?x-bce-process=image/resize,m_lfit,h_160,limit_1'
index = url.rfind('/')#返回字符串最后一次出现的位置,如果没有匹配项则返回-1
print(index)
print(url[:index])运行结果:
#97
#https://bkimg.cdn.bcebos.com/pic/faf2b2119313b07eca80d4dd909f862397dda0442687?x-bce-process=image
Day3:
《青春有你2》选手数据分析
对选手体重分布进行可视化,绘制饼状图(这样是不是不太好,手动捂脸~~)
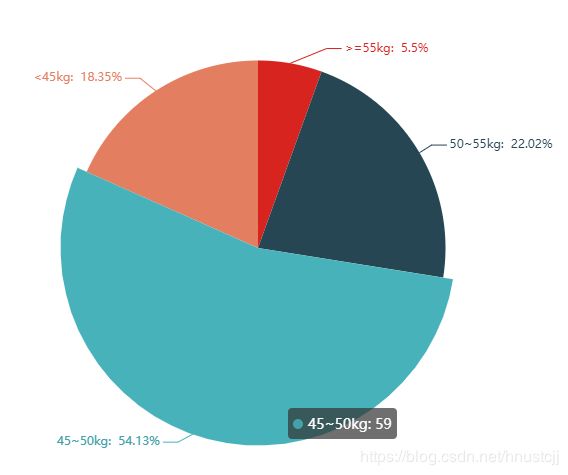
以上是用pyecharts作出的图,交互性很棒~
Day4:
PaddleHub预训练模型体验,完成人物图片5分类任务~
第1步:完成图片的获取(5位小姐姐)
可先据不同“姓名”爬取图片,可适当人工筛选质量高的图片。创建5个文件夹存放对应的不同小姐姐的照片,创建“label_list.txt”作为之后名字与类别编号的映射,划分训练集、验证集和测试集分别对应 "train_list.txt"、"test_list.txt"及"validate_list.txt"。(名称可自己命名,但要方便开发者辨认。)
3个“.txt”文件下一行一条数据,格式为:
图片路径 类别编号
第2步:加载预训练模型,导入paddlehub可加载一些图片分类模型
module = hub.Module(name="resnet_v2_50_imagenet")
#resnet_v2_101_imagenet图像分类模型
第3步:加载图片数据集。使用自定义的数据进行体验~
加载图像类自定义数据集,用户仅需要继承基类BaseCVDatast,修改数据集存放地址即可。
利用PaddleHub迁移CV类任务使用自定义数据时,用户需要自己切分数据集,将数据集且分为训练集、验证集和测试集。
from paddlehub.dataset.base_cv_dataset import BaseCVDataset
class DemoDataset(BaseCVDataset):
def __init__(self):
# 数据集存放位置
self.dataset_dir = "./data/dataset0426/"
super(DemoDataset, self).__init__(
base_path = self.dataset_dir,
train_list_file = "train_list.txt",
validate_list_file = "validate_list.txt",
test_list_file = "test_list.txt",
label_list_file = "label_list.txt",
)
dataset = DemoDataset()参考:
适配数据
第4步:生成数据读取器
生成一个图像分类的reader,reader负责将dataset的数据进行预处理,接着以特定格式组织并输入给模型进行训练。
data_reader = hub.reader.ImageClassificationReader(
image_width = module.get_expected_image_width(),
image_height = module.get_expected_image_height(),
images_mean = module.get_pretrained_images_mean(),
images_std = module.get_pretrained_images_std(),
dataset = dataset)第5步:配置策略
RunConfig
RunConfig代表了在对Task进行Finetune时的运行配置。包括运行的epoch次数、batch的大小、是否使用GPU训练等。
比如:
config = hub.RunConfig(
use_cuda = True, #是否使用GPU训练,默认为False;True
num_epoch = 100, #Fine-tune的轮数;
checkpoint_dir = "cv_finetune_turtorial_demo",#模型checkpoint保存路径, 若用户没有指定,程序会自动生成;
batch_size = 8, #训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
eval_interval = 10, #模型评估的间隔,默认每100个step评估一次验证集;
strategy = hub.finetune.strategy.DefaultFinetuneStrategy()) #Fine-tune优化策略;第6步:组建Finetune Task
模型改造!(参考老师的解释!!)
- 获取module的上下文环境,包括输入和输出的变量,以及Paddle Program;
- 从输出变量中找到特征图提取层feature_map;
- 在feature_map后面接入一个全连接层,生成Task;
主要是feature_map、feature_list
input_dict, output_dict, program = module.context(trainable=True)
img = input_dict["image"]
feature_map = output_dict["feature_map"]
feed_list = [img.name]
task = hub.ImageClassifierTask(
data_reader = data_reader,
feed_list = feed_list,
feature = feature_map,
num_classes = dataset.num_labels,
config = config)第7步:开始Finetune
最后一步~
run_states = task.finetune_and_eval()Day5:
还需补充~
第1步:评论爬取
aiqiyi《青春有你2》
爬取任意一期正片视频下评论(条数不少于1000条)
数据获取就是最关键的一步。首先点击链接(暂停视频),按下F12,先不要急于刷新页面,一直往下滚动,会出现下图:
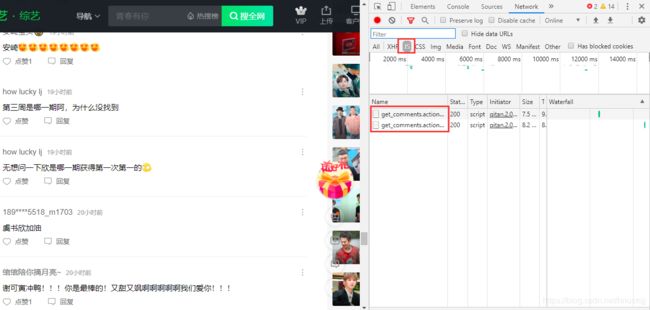
随意点一个“get_comments” 进去,选择“Preview”:
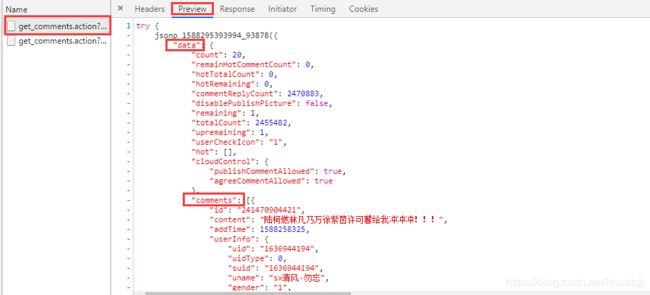
评论信息在“data”的“comments”的“content”下,特别要注意“content”可能不存在,需要添加条件判断语句~
#请求爱奇艺评论接口,返回response信息
c_num = 1
def getMovieinfo(url):
'''
请求爱奇艺评论接口,返回response信息
参数 url: 评论的url
:return: response信息
'''
session = requests.Session()
headers = {
"Host": "sns-comment.iqiyi.com",
"Referer": "https://www.iqiyi.com/v_19ryfkiv8w.html",
#"Origin": "http://m.iqiyi.com",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36"
}
response = session.get(url, headers = headers)
#正常响应
if response.status_code == 200:
return response.text
return None
#解析json数据,获取评论
def saveMovieInfoToFile(lastId, arr):
'''
解析json数据,获取评论
参数 lastId:最后一条评论ID arr:存放文本的list
:return: 新的lastId
'''
global c_num
url = "https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&\
agent_version=9.11.5&authcookie=null&business_type=17&content_id=15068699100&page=&page_size=20&types=time&last_id="
url += str(lastId)
responseTxt = getMovieinfo(url)
responseJson = json.loads(responseTxt)
comments = responseJson['data']['comments']
for val in comments:
if 'content' in val.keys():
c = val['content']
#print(c)
if(c_num % 50 == 0):
print("第 {} 条评论为:{}".format(c_num,c))
c_num += 1
arr.append(c)
lastId = str(val['id'])
return lastId这里要用到requests session,因为一页请求的评论数是有限的,一个重要的参数是“last_id”,上一页最后一条评论信息的“id”就是新的请求中的“last_id”
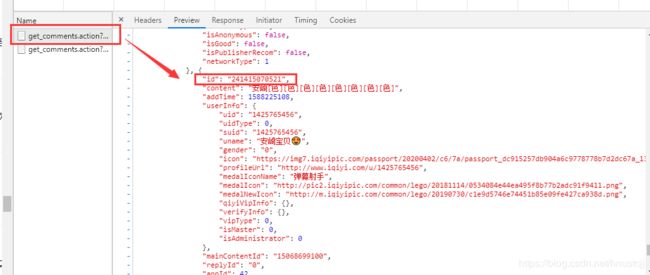
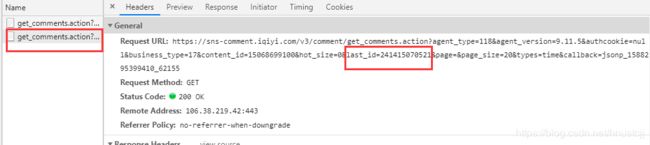
所以要存好“id”这个参数后面要赋值给“last_id”。
可以测试一下:
#评论是多分页的,得多次请求爱奇艺的评论接口才能获取多页评论,有些评论含有表情、特殊字符之类的
#num 是页数,一页10条评论,假如爬取1000条评论,设置num = 50
if __name__ == "__main__":
#c_num = 1
num = 4
lastId = '0'
arr = []
with open("aqy.txt",'w',encoding = 'utf-8') as f:
for i in range(num):
lastId = saveMovieInfoToFile(lastId, arr)
time.sleep(3)
for item in arr:
Item = clear_special_char(item)
if Item.strip()!='':
try:
f.write(Item+"\n")
except Exception as e:
print(e)
print("含特殊字符")第2步:词频统计并可视化
数据预处理:清洗评论中特殊字符,结果存储为txt文档;中文分词:添加新增词(如:青你、奥利给、冲鸭),去除停用词(如:哦、因此、不然、也好、但是)
特殊字符可以用re的正则匹配去除(一行代码就可~),之后的步骤按顺序来就好~
统计top10高频词;可视化高频词
第3步:绘制词云
根据词频生成词云;可选项-添加背景图片,根据背景图片轮廓生成词云
第4步:评论审核
结合PaddleHub,对评论进行内容审核
先安装:
#安装模型
!hub install porn_detection_lstm==1.1.0
!pip install --upgrade paddlehubdef text_detection(test_text, file_path):
'''
使用hub对评论进行内容分析
return:分析结果
'''
porn_detection_lstm = hub.Module(name = 'porn_detection_lstm')
f = open(file_path, 'r', encoding = 'utf-8')
for line in f:
if len(line.strip()) == 1:
continue
else:
test_text.append(line)
f.close()
input_dict = {"text":test_text}
results = porn_detection_lstm.detection(data = input_dict, use_gpu = True, batch_size = 1)
for index, item in enumerate(results):
if item['porn_detection_key'] == 'porn':
print(item['text'],' : ',item['porn_probs'])