从0到1创建基于Unity的ML-Agent机器学习项目
希望大家可以加Unity群交流:484275915
本文意在记录如何在配好环境的情况下在unity中创建一个简单的机器学习项目,其中包含以下内容
- 搭建Unity场景中的代理
- 代码
- 用神经网络给出的参数来控制代理的行为
- 在代码中向神经网络表达奖惩规则
- 设置收集观察变量
- 代理达到目的后重置场景 - 使用Python进行训练
- 使用训练完成后得出的配置文件
文中并不提及关于环境配置的内容。
这个项目在GitHub的ML-Agent项目中有说明文档,但由于以下三点原因,博主决定写下这篇创建unity机器学习项目的博文:
- Git上的教学文档是英文的
- 里面有几处错误,如果完全按照文档中一步步来是得不出正确的结果的,此错误包括代码错误与步骤错误
- 之前因为兴趣自己做了一遍,这几天突然要开始用,发现忘记怎么弄了,调试了半天才重新弄好。
首先给出原文档连接,为了防止时间久了GitHub上的代码被更新,我在我的码云中Clone了一份写本文时的版本给出源码链接
1.场景搭建
首先我介绍一下这个Demo的内容及规则:如下图所示,有一块面板、一个小球以及一个橙色的盒子。规则就是小球被期望不停的冲向盒子,当他与盒子的距离小于1时,可获得奖励+1分,并重置盒子位置随机在地面上某个地方,小球回到在初始位置;当它掉到地面以外时,将会遭到惩罚-1分,并重置盒子位置随机在地面上某个地方,小球回到在初始位置。

2.脚本编写
根据以上说明设置好场景内的物体。接着需要在场景中建立一个空物体“Academy”用于挂载一个叫“RollerAcadeny”的脚本,此脚本里面是空的只要继承“Acadeny”即可,这个脚本是在源码中带着的.因为这个Demo中有很多例子,我想可能是为了区分例子所以才这么做的吧,代码如下所示:
using MLAgents;
public class RollerAcademy : Academy{ }
挂上后如下图所示:

完成上一步后,我们需要创建一个脚本,我们就把它命名为“RollerAgent”,并将其挂载到我们的代理——小球身上,为了达到清楚说明的目的,我们一步一步说如何将这个脚本写出来。
1 首先请引用命名空间
using MLAgents;
2 接着此类需要继承“Agent”此类为源码中自带,如下所示
using MLAgents;
public class RollerAgent : Agent{
public Transform m_tranTarget;
private Rigidbody m_rBody;
private void Start()
{
m_rBody = GetComponent<Rigidbody>();
}
}
3 我们要在小球掉下去或者碰到盒子的时候重置,重置逻辑如下所示,必须重写虚函数“AgentReset”,需要重置时会自动执行重写的逻辑
using MLAgents;
public class RollerAgent : Agent{
public Transform m_tranTarget;
private Rigidbody m_rBody;
private void Start()
{
m_rBody = GetComponent<Rigidbody>();
}
}
/// 重置
public override void AgentReset()
{
if (transform.position.y<0)
{
m_rBody.angularVelocity = Vector3.zero;
m_rBody.velocity = Vector3.zero;
transform.position = new Vector3(0, 0.5f, 0);
}
m_tranTarget.position = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
}
4 接着是手机观察变量,将可能会影响结果的变量当成函数“AddVectorObs”的参数传入,并且必须在重写虚函数“CollectObservations”中实现
using MLAgents;
public class RollerAgent : Agent{
public Transform m_tranTarget;
private Rigidbody m_rBody;
private void Start()
{
m_rBody = GetComponent<Rigidbody>();
}
}
/// 重置
public override void AgentReset()
{
if (transform.position.y<0)
{
m_rBody.angularVelocity = Vector3.zero;
m_rBody.velocity = Vector3.zero;
transform.position = new Vector3(0, 0.5f, 0);
}
m_tranTarget.position = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
}
/// 收集观察变量
public override void CollectObservations()
{
AddVectorObs(m_tranTarget.position);
AddVectorObs(transform.position);
AddVectorObs(m_rBody.velocity.x);
AddVectorObs(m_rBody.velocity.z);
}
5 最后就是如何让神经网络给出的值来操控我们的代理——小球了,并且设置奖惩规则也是在这个函数中,在这个函数中影响我们的代理的其实是“float[] vectorAction”这个数组,一开始神经网络其实也不知道这个数组是做什么的,但是在无数次的训练后它发现通过改变这个数组前两个值可以影响奖励的获得或者惩罚的遭遇,于是它就学会了通过给出这两个不同的参数来得到更高的分数。
//小球的运动速度
public float m_floSpeed = 10.0f;
/// 代理的行为
public override void AgentAction(float[] vectorAction, string textAction)
{
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];
controlSignal.z = vectorAction[1];
m_rBody.AddForce(controlSignal * m_floSpeed);
//小球到盒子的距离
float distanceToTarget = Vector3.Distance(transform.position, m_tranTarget.position);
//以下为奖惩措施
if (distanceToTarget < 1f)
{
Debug.Log("触碰");
AddReward(1.0f);//获得奖励+1
Done();//这个函数是示例教学中带着的,要在调用上面的函数后调用一下
}
if (transform.position.y < 0)
{
AddReward(-1.0f);//遭到惩罚-1
Done();
}
以下为此脚本的完整代码:
using UnityEngine;
using MLAgents;
public class RollerAgent : Agent
{
private Rigidbody m_rBody;
private void Start()
{
m_rBody = GetComponent<Rigidbody>();
}
public Transform m_tranTarget;
/// 重置
public override void AgentReset()
{
if (transform.position.y<0)
{
m_rBody.angularVelocity = Vector3.zero;
m_rBody.velocity = Vector3.zero;
transform.position = new Vector3(0, 0.5f, 0);
}
m_tranTarget.position = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
}
/// 收集观察变量
public override void CollectObservations()
{
AddVectorObs(m_tranTarget.position);
AddVectorObs(transform.position);
AddVectorObs(m_rBody.velocity.x);
AddVectorObs(m_rBody.velocity.z);
}
public float m_floSpeed = 10.0f;
/// 如果你能做到这里表示脚本部分已经结束了,是不是很简单!
接下来我们就要开始训练了!
3.开始训练
1).Unity中的设置
首先创建我们的学习大脑,在Project面板右键Creat下图中所示的"LearningBrain"

创建好后我们将其命名为“RollerBallBrain”,并将其Inspector面板如下图所示设置
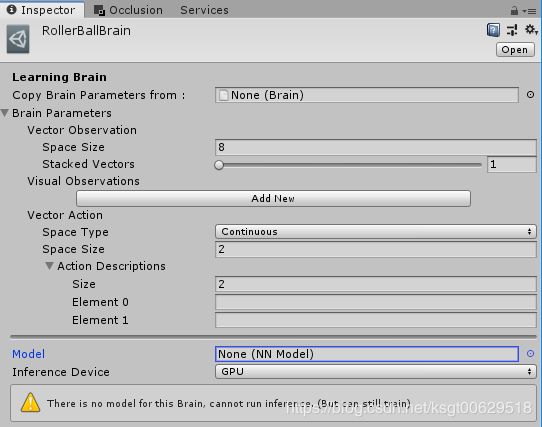
设置好后,选中我们之前挂载脚本叫“Academy”的物体,将其拖到如下图位置上,并选中Control打钩

2).外部设置
将配置环境时安装好的“Anaconda Navigator”软件打开,点击如下图所示按钮

打开后我们首先要将路径定位到我们Clone下来的源码的目录,由于每个人的目录都是不同的,请不要直接按照我的目录设置!但是请注意必须定位到自己源码的根目录下,不然会报无法运行命令的错误按照自己的实际情况设置如下所示

接下来请输入命令
mlagents-learn config/trainer_config.yaml --run-id=RollerBall-1 --train
注意,上一行命令在原说明文件里面是错误的,因为它路径写错了他写的是

但是我们看下载下来的源码中这个文件的文件名是:

当时这里坑了我,找了半天明明是一步步按照说明文档做的为什么报找不到这个文件,最终发现是因为他文件名写错了。
这里我也解释下这句代码是什么意思:
mlagents-learn //这个是命令,告诉程序我要干什么
config/trainer_config.yaml//这是配置文件的相对路径
--run-id=RollerBall-1 //给生成的文件启一个名字,这个名字不要重复,不然会覆盖之前的训练成果
--train//开始训练命令
除了上面所说的命令以外,我们也可以在配置文件中进行设置训练次数等操作,这个训练次数其实非常重要,因为训练次数直接关系到训练效果,理论上说训练次数越多,我们的代理行动越精确,我们可以通过直接修改上述图片中的红框框中的配置文件中的max_steps的值来设定最大训练次数,我记得之前做这个项目的时候使用命令行修改了这个最大训练次数,不过也可能是我记错了我找了半天也没找到那个命令,之后想起来的话再补充上来,如果有知道的同学请告诉我。
除此以外这个配置文件中还可予以修改很多其他的值,参数修改请直接参考。
当你输入这个命令按下回车出来这个界面

以及下方出现时
INFO:mlagents.envs:Start training by pressing the Play button in the Unity Editor.
你就可以点击Unity的Play按钮运行你的程序你就会看到他会飞快的开始进行训练了

训练完成之后,你需要到路径“G:\Work\Git\ml-agents-master\models”下找到你训练好的模型拖入Unity
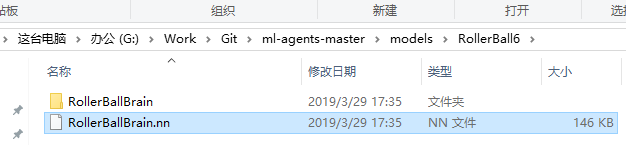
然后拖给他

做完以上工作,将“Academy”上的Control勾掉运行即可看到效果了!
