ELK+Filebeat日志收集集群搭建
ELK安装教程
作者:半江瑟瑟
- ELK安装教程
- Elasticsearch 6.3.1 安装
1.1创建elk域
groupadd elk
useradd -g elk -m elk
usermod -a -G elk elk
groups elk
passwd elk
密码:elk123
1.2. 修改配置文件,防止安装时出现问题(root 目录操作)
1. 2.1修改limit信息
vi /etc/security/limits.conf
| * soft nofile 65536 * hard nofile 131072 * soft nproc 4096 * hard nproc 4096 * soft memlock unlimited * hard memlock unlimited |
执行:source /etc/ security/limits.conf
1.2.2 修改集群配置信息
|
1.2.3修改sysctl 文件
vi /etc/sysctl.conf
| 添加下面配置: vm.max_map_count=655360 并执行命令: sysctl -p |
1.3 安装elasticsearch
1.3.1 上传elasticsearch 文件到elk组下
在/home/elk/ap/ifsp/下上传 elasticsearch-6.3.1.zip/ elasticsearch-6.3.1.tz 文件
su elk 进入elk用户
Zip:
Unzip elasticsearch-6.3.1.zip 命令解压
Tz
tar -zxvf elasticsearch-6.3.1.tz 命令解压
1.3.2修改配置文件
[elk@gaapospapp31l-14181 config]$ cd /home/elk/ap/ifsp/elasticsearch-6.3.1/config
cd /home/elk/ap/ifsp/elasticsearch-6.3.1/conf/
vi elasticsearch.yml
| # ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- Cluster ----------------------------------- # # Use a descriptive name for your cluster: # #集群名称 cluster.name: application # # ------------------------------------ Node ------------------------------------ # # Use a descriptive name for the node: #节点名同一集群下节点名称不同 node.name: node-1 #主节点(父节点) node.master: true node.data: false # # Add custom attributes to the node: # #node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # # Path to directory where to store the data (separate multiple locations by comma): #路径修改为自己设置的路径 path.data: /home/elk/ap/ifsp/data # # Path to log files: #路径修改为自己设置的路径 path.logs: /home/elk/ap/ifsp/logs # # ----------------------------------- Memory ----------------------------------- # # Lock the memory on startup: #设置内存锁定,防止数据swap bootstrap.memory_lock: true bootstrap.system_call_filter: false # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): #设置绑定地址,这里取本机地址 network.host: 11.18.14.181 # # Set a custom port for HTTP: #本机端口 http.port: 9200 # # For more information, consult the network module documentation. # # --------------------------------- Discovery ---------------------------------- # # Pass an initial list of hosts to perform discovery when new node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] #集群中其他节点ip discovery.zen.ping.unicast.hosts: ["11.18.14.181", "11.18.14.182","11.18.14.183"] # # Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1): # #discovery.zen.minimum_master_nodes: # # For more information, consult the zen discovery module documentation. # # ---------------------------------- Gateway ----------------------------------- # # Block initial recovery after a full cluster restart until N nodes are started: # #gateway.recover_after_nodes: 3 # # For more information, consult the gateway module documentation. # # ---------------------------------- Various ----------------------------------- # # Require explicit names when deleting indices: # #action.destructive_requires_name: true |
这里三台机器进行集群,每台的配置和这个类似只是稍微有些去别,配置的集群名在所有参加集群的机器中都是一样的,只是节点的地方有改动例如下面时配置:
| # ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- Cluster ----------------------------------- # # Use a descriptive name for your cluster: #集群名,所有主节点和子节点都是使用这个名字 cluster.name: application # # ------------------------------------ Node ------------------------------------ # # Use a descriptive name for the node: #所有的节点名称都不能相同 node.name: node-2 #子节点配置都是这样的 node.master: false node.data: true # # Add custom attributes to the node: # #node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # # Path to directory where to store the data (separate multiple locations by comma): #位置选自己设置的路径 path.data: /home/elk/ap/ifsp/data # # Path to log files: # path.logs: /home/elk/ap/ifsp/logs # # ----------------------------------- Memory ----------------------------------- # # Lock the memory on startup: # bootstrap.memory_lock: true bootstrap.system_call_filter: false # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): #自己本机的ip network.host: 11.18.14.182 # # Set a custom port for HTTP: #本机端口 http.port: 9200 # # For more information, consult the network module documentation. # # --------------------------------- Discovery ---------------------------------- # # Pass an initial list of hosts to perform discovery when new node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # discovery.zen.ping.unicast.hosts: ["11.18.14.181", "11.18.14.182","11.18.14.183"] # # Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1): # #discovery.zen.minimum_master_nodes: # # For more information, consult the zen discovery module documentation. # # ---------------------------------- Gateway ----------------------------------- # # Block initial recovery after a full cluster restart until N nodes are started: # #gateway.recover_after_nodes: 3 # # For more information, consult the gateway module documentation. # # ---------------------------------- Various ----------------------------------- # # Require explicit names when deleting indices: # #action.destructive_requires_name: true |
1.3.3测试安装
后台启动:bin 目录下
nohup ./elasticseach &
查看启动日志
tail -300f nohup.out

查看端口是否启动netstat -ant
![]()
启动另外机器的elasticsearch 然后查看集群的状态
健康状况
curl '11.18.14.181:9200/_cluster/health?pretty'
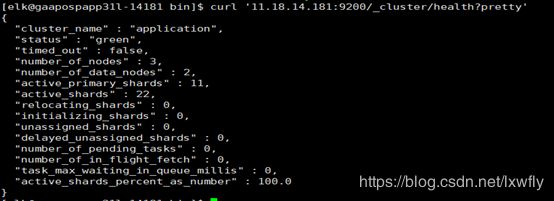
集群状态
curl '11.18.14.181:9200/_cluster/state?pretty'
--测试:./bin/logstash -e 'input{ stin{} } output{ stdout{} }'
1.3.4问题解决办法
1.

su root
vi /etc/security/limits.d/90-nproc.conf
#修改如下内容:
* soft nproc 1024
#修改为
* soft nproc 4096
2.
![]()
vi /etc/security/limits.conf
* soft memlock unlimited
* hard memlock unlimited
- Logstash 6.3.1安装
- 1上传文件
logstash-6.3.1tar.gz
- 2解压
tar -zxvf logstash-6.3.1tar.gz
- 3添加配置文件
这个文件是自己创建的,注意里面的空格,这里收集日志使用的filebeat所以input中使用的beats,如果直接使用logstash搜集日志直接配置file就行了具体配置自行百度
logstash.config
input { beats { port => "5044" } } output { elasticsearch { hosts => ["10.10.114.4:9200"] } stdout { codec => rubydebug } }
|
- 4测试正确性
./logstash -f /home/elk/ap/ifsp/logstash-6.3.1/logstash.config --config.test_and_exit
- 5启动
nohup ./logstash -f /home/elk/ap/ifsp/logstash-6.3.1/logstash.config &
查看端口
netstat -ntpl|grep 5044
或
lsof -i:5044
配置kibana端口
su root
vi /etc/rsyslog.conf
如出下问题Logstash could not be started because there is already..
删掉path.data的路径.lock :ls -alh

添加这行是为了收集系统日志,可已不填;
添加完之后执行命令
service rsyslog restart
-
Kibana安装1.1上传
kibana-6.3-linux-x64.tar.gz
tar -zxvf kibana-6.3-linux-x64.tar.gz;
1.2修改配置文件
vi config/kibana.yml
|
|
启动:
nohup kibana &
访问
http://ip:port
lsof -i :5601 查看端口号
-
filebeat 安装
1.1解压安装
tar -zxvf filebeat-6.3.1-linux-x86_64.tar.gz
1.2修改配置文件
vi /home/weblogic/soft/filebeat-6.3.1-x86_64/filebeat.yml
| ###################### Filebeat Configuration Example #########################
# This file is an example configuration file highlighting only the most common # options. The filebeat.reference.yml file from the same directory contains all the # supported options with more comments. You can use it as a reference. # # You can find the full configuration reference here: # https://www.elastic.co/guide/en/beats/filebeat/index.html
# For more available modules and options, please see the filebeat.reference.yml sample # configuration file.
#=========================== Filebeat inputs =============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so # you can use different inputs for various configurations. # Below are the input specific configurations. #这里可以有多个,这里就是path就是我们要搜集日志的路径 - type: log
# Change to true to enable this input configuration. enabled: true
# Paths that should be crawled and fetched. Glob based paths. paths: - /home/weblogic/ifsp/logs/*.log #- c:\programdata\elasticsearch\logs\*
# Exclude lines. A list of regular expressions to match. It drops the lines that are # matching any regular expression from the list. #exclude_lines: ['^DBG']
# Include lines. A list of regular expressions to match. It exports the lines that are # matching any regular expression from the list. #include_lines: ['^ERR', '^WARN']
# Exclude files. A list of regular expressions to match. Filebeat drops the files that # are matching any regular expression from the list. By default, no files are dropped. #exclude_files: ['.gz$']
# Optional additional fields. These fields can be freely picked # to add additional information to the crawled log files for filtering #fields: # level: debug # review: 1
### Multiline options
# Mutiline can be used for log messages spanning multiple lines. This is common # for Java Stack Traces or C-Line Continuation
# The regexp Pattern that has to be matched. The example pattern matches all lines starting with [ #multiline.pattern: ^\[
# Defines if the pattern set under pattern should be negated or not. Default is false. #multiline.negate: false
# Match can be set to "after" or "before". It is used to define if lines should be append to a pattern # that was (not) matched before or after or as long as a pattern is not matched based on negate. # Note: After is the equivalent to previous and before is the equivalent to to next in Logstash #multiline.match: after
#============================= Filebeat modules ===============================
filebeat.config.modules: # Glob pattern for configuration loading path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading reload.enabled: false
# Period on which files under path should be checked for changes #reload.period: 10s
#==================== Elasticsearch template setting ==========================
setup.template.settings: index.number_of_shards: 3 #index.codec: best_compression #_source.enabled: false
#================================ General =====================================
# The name of the shipper that publishes the network data. It can be used to group # all the transactions sent by a single shipper in the web interface. #name:
# The tags of the shipper are included in their own field with each # transaction published. #tags: ["service-X", "web-tier"]
# Optional fields that you can specify to add additional information to the # output. #fields: # env: staging
#============================== Dashboards ===================================== # These settings control loading the sample dashboards to the Kibana index. Loading # the dashboards is disabled by default and can be enabled either by setting the # options here, or by using the `-setup` CLI flag or the `setup` command. #setup.dashboards.enabled: false
# The URL from where to download the dashboards archive. By default this URL # has a value which is computed based on the Beat name and version. For released # versions, this URL points to the dashboard archive on the artifacts.elastic.co # website. #setup.dashboards.url:
#============================== Kibana =====================================
# Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API. # This requires a Kibana endpoint configuration. setup.kibana:
# Kibana Host # Scheme and port can be left out and will be set to the default (http and 5601) # In case you specify and additional path, the scheme is required: http://localhost:5601/path # IPv6 addresses should always be defined as: https://[2001:db8::1]:5601 #host: "localhost:5601"
#============================= Elastic Cloud ==================================
# These settings simplify using filebeat with the Elastic Cloud (https://cloud.elastic.co/).
# The cloud.id setting overwrites the `output.elasticsearch.hosts` and # `setup.kibana.host` options. # You can find the `cloud.id` in the Elastic Cloud web UI. #cloud.id:
# The cloud.auth setting overwrites the `output.elasticsearch.username` and # `output.elasticsearch.password` settings. The format is ` #cloud.auth:
#================================ Outputs =====================================
# Configure what output to use when sending the data collected by the beat.
#-------------------------- Elasticsearch output ------------------------------ #output.elasticsearch: # Array of hosts to connect to. # hosts: ["localhost:9200"]
# Optional protocol and basic auth credentials. #protocol: "https" #username: "elastic" #password: "changeme"
#----------------------------- Logstash output -------------------------------- output.logstash: # The Logstash hosts hosts: ["11.18.14.181:5044", "11.18.14.182:5044", "11.18.14.183:5044"]
# Optional SSL. By default is off. # List of root certificates for HTTPS server verifications #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication #ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key #ssl.key: "/etc/pki/client/cert.key"
#================================ Logging =====================================
# Sets log level. The default log level is info. # Available log levels are: error, warning, info, debug #logging.level: debug
# At debug level, you can selectively enable logging only for some components. # To enable all selectors use ["*"]. Examples of other selectors are "beat", # "publish", "service". #logging.selectors: ["*"]
#============================== Xpack Monitoring =============================== # filebeat can export internal metrics to a central Elasticsearch monitoring # cluster. This requires xpack monitoring to be enabled in Elasticsearch. The # reporting is disabled by default.
# Set to true to enable the monitoring reporter. #xpack.monitoring.enabled: false
# Uncomment to send the metrics to Elasticsearch. Most settings from the # Elasticsearch output are accepted here as well. Any setting that is not set is # automatically inherited from the Elasticsearch output configuration, so if you # have the Elasticsearch output configured, you can simply uncomment the # following line. #xpack.monitoring.elasticsearch: |
由于我们使用logstash用来发给elasticsearch ,所以我们搜集的日志发给logstash;
1.3启动
到bin目录
nohup ./filebeat -e -c ./filebeat.yml > /dev/null &

启动成功,结束;
- 注意事项和问题
- 所有ELK软件安装都是在elk用户下进行安装的,所有ELK文件都是在elk用户下。jdk版本最好使用8,其他版本会出现兼容性问题。还有一定要注意配置文件中空格,ELK对这个要求很严格
- Error: [illegal_argument_exception] maxConcurrentShardRequests must be >= 1

集群配置,只启动一台服务el会出现这种问题,启动集群内的其他机器就会解决该问题
3.
| unable to install syscall filter: java.lang.UnsupportedOperationException: seccomp unavailable: requires kernel 3.5+ with CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER compiled in at org.elasticsearch.bootstrap.SystemCallFilter.linuxImpl(SystemCallFilter.java:350) ~[elasticsearch-5.4.0.jar:5.4.0] at org.elasticsearch.bootstrap.SystemCallFilter.init(SystemCallFilter.java:638) ~[elasticsearch-5.4.0.jar:5.4.0] at org.elasticsearch.bootstrap.JNANatives.tryInstallSystemCallFilter(JNANatives.java:215) [elasticsearch-5.4.0.jar:5.4.0] at org.elasticsearch.bootstrap.Natives.tryInstallSystemCallFilter(Natives.java:99) [elasticsearch-5.4.0.jar:5.4.0] at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:111) [elasticsearch-5.4.0.jar:5.4.0] at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:204) [elasticsearch-5.4.0.jar:5.4.0] at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:360) [elasticsearch-5.4.0.jar:5.4.0] at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:123) [elasticsearch-5.4.0.jar:5.4.0] at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:114) [elasticsearch-5.4.0.jar:5.4.0] at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:67) [elasticsearch-5.4.0.jar:5.4.0] at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:122) [elasticsearch-5.4.0.jar:5.4.0] at org.elasticsearch.cli.Command.main(Command.java:88) [elasticsearch-5.4.0.jar:5.4.0] 原因:报了一大串错误,大家不必惊慌,其实只是一个警告,主要是因为你Linux版本过低造成的。 解决方案: |
4.
| ERROR: bootstrap checks failed memory locking requested for elasticsearch process but memory is not locked 原因:锁定内存失败
解决方案: 切换到root用户,编辑limits.conf配置文件, 添加类似如下内容: sudo vim /etc/security/limits.conf
添加如下内容: * soft memlock unlimited * hard memlock unlimited
|
5
| ERROR: bootstrap checks failed max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] 原因:无法创建本地文件问题,用户最大可创建文件数太小 解决方案: 切换到root用户,编辑limits.conf配置文件, 添加类似如下内容: sudo vim /etc/security/limits.conf
添加如下内容: * soft nofile 65536 * hard nofile 131072 |
6
| max number of threads [1024] for user [es] is too low, increase to at least [2048] 原因:无法创建本地线程问题,用户最大可创建线程数太小 解决方案:切换到root用户,进入limits.d目录下,修改90-nproc.conf 配置文件。
sudo vim /etc/security/limits.d/90-nproc.conf
找到如下内容: * soft nproc 1024
修改为 * soft nproc 2048
|
7
| max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 原因:最大虚拟内存太小 解决方案:切换到root用户下,修改配置文件sysctl.conf sudo vim /etc/sysctl.conf 添加下面配置: vm.max_map_count=655360 并执行命令: sysctl -p |
8
| system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk 问题原因:因为Centos6不支持SecComp 解决方法:在elasticsearch.yml中配置bootstrap.system_call_filter为false,注意要在Memory下面: bootstrap.memory_lock: false bootstrap.system_call_filter: false! |